 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDolphin: A Large-Scale Automatic Speech Recognition Model for Eastern Languages
Mar 26, 2025This report introduces Dolphin, a large-scale multilingual automatic speech recognition (ASR) model that extends the Whisper architecture to support a wider range of languages. Our approach integrates in-house proprietary and open-source datasets to refine and optimize Dolphin's performance. The model is specifically designed to achieve notable recognition accuracy for 40 Eastern languages across East Asia, South Asia, Southeast Asia, and the Middle East, while also supporting 22 Chinese dialects. Experimental evaluations show that Dolphin significantly outperforms current state-of-the-art open-source models across various languages. To promote reproducibility and community-driven innovation, we are making our trained models and inference source code publicly available.
Simul-Whisper: Attention-Guided Streaming Whisper with Truncation Detection
Jun 14, 2024
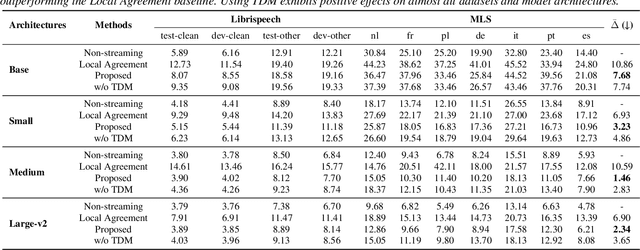

As a robust and large-scale multilingual speech recognition model, Whisper has demonstrated impressive results in many low-resource and out-of-distribution scenarios. However, its encoder-decoder structure hinders its application to streaming speech recognition. In this paper, we introduce Simul-Whisper, which uses the time alignment embedded in Whisper's cross-attention to guide auto-regressive decoding and achieve chunk-based streaming ASR without any fine-tuning of the pre-trained model. Furthermore, we observe the negative effect of the truncated words at the chunk boundaries on the decoding results and propose an integrate-and-fire-based truncation detection model to address this issue. Experiments on multiple languages and Whisper architectures show that Simul-Whisper achieves an average absolute word error rate degradation of only 1.46% at a chunk size of 1 second, which significantly outperforms the current state-of-the-art baseline.