 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-Audio-EditX Technical Report
Nov 05, 2025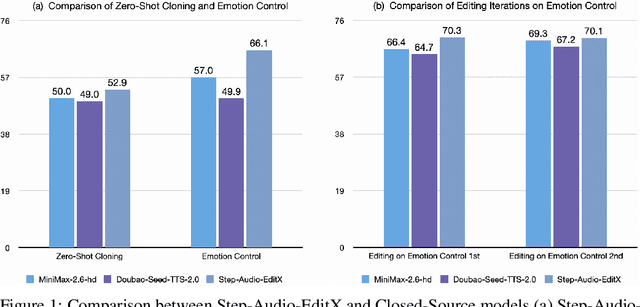
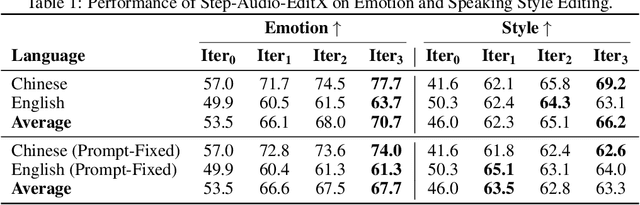

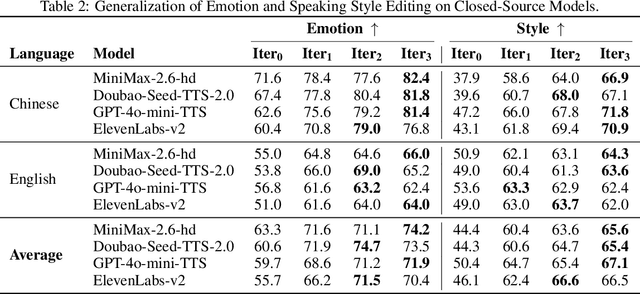
We present Step-Audio-EditX, the first open-source LLM-based audio model excelling at expressive and iterative audio editing encompassing emotion, speaking style, and paralinguistics alongside robust zero-shot text-to-speech (TTS) capabilities.Our core innovation lies in leveraging only large-margin synthetic data, which circumvents the need for embedding-based priors or auxiliary modules. This large-margin learning approach enables both iterative control and high expressivity across voices, and represents a fundamental pivot from the conventional focus on representation-level disentanglement. Evaluation results demonstrate that Step-Audio-EditX surpasses both MiniMax-2.6-hd and Doubao-Seed-TTS-2.0 in emotion editing and other fine-grained control tasks.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
ManiGaussian++: General Robotic Bimanual Manipulation with Hierarchical Gaussian World Model
Jun 24, 2025Multi-task robotic bimanual manipulation is becoming increasingly popular as it enables sophisticated tasks that require diverse dual-arm collaboration patterns. Compared to unimanual manipulation, bimanual tasks pose challenges to understanding the multi-body spatiotemporal dynamics. An existing method ManiGaussian pioneers encoding the spatiotemporal dynamics into the visual representation via Gaussian world model for single-arm settings, which ignores the interaction of multiple embodiments for dual-arm systems with significant performance drop. In this paper, we propose ManiGaussian++, an extension of ManiGaussian framework that improves multi-task bimanual manipulation by digesting multi-body scene dynamics through a hierarchical Gaussian world model. To be specific, we first generate task-oriented Gaussian Splatting from intermediate visual features, which aims to differentiate acting and stabilizing arms for multi-body spatiotemporal dynamics modeling. We then build a hierarchical Gaussian world model with the leader-follower architecture, where the multi-body spatiotemporal dynamics is mined for intermediate visual representation via future scene prediction. The leader predicts Gaussian Splatting deformation caused by motions of the stabilizing arm, through which the follower generates the physical consequences resulted from the movement of the acting arm. As a result, our method significantly outperforms the current state-of-the-art bimanual manipulation techniques by an improvement of 20.2% in 10 simulated tasks, and achieves 60% success rate on average in 9 challenging real-world tasks. Our code is available at https://github.com/April-Yz/ManiGaussian_Bimanual.
Rethinking Remaining Useful Life Prediction with Scarce Time Series Data: Regression under Indirect Supervision
Apr 12, 2025Supervised time series prediction relies on directly measured target variables, but real-world use cases such as predicting remaining useful life (RUL) involve indirect supervision, where the target variable is labeled as a function of another dependent variable. Trending temporal regression techniques rely on sequential time series inputs to capture temporal patterns, requiring interpolation when dealing with sparsely and irregularly sampled covariates along the timeline. However, interpolation can introduce significant biases, particularly with highly scarce data. In this paper, we address the RUL prediction problem with data scarcity as time series regression under indirect supervision. We introduce a unified framework called parameterized static regression, which takes single data points as inputs for regression of target values, inherently handling data scarcity without requiring interpolation. The time dependency under indirect supervision is captured via a parametrical rectification (PR) process, approximating a parametric function during inference with historical posteriori estimates, following the same underlying distribution used for labeling during training. Additionally, we propose a novel batch training technique for tasks in indirect supervision to prevent overfitting and enhance efficiency. We evaluate our model on public benchmarks for RUL prediction with simulated data scarcity. Our method demonstrates competitive performance in prediction accuracy when dealing with highly scarce time series data.
Extending Cox Proportional Hazards Model with Symbolic Non-Linear Log-Risk Functions for Survival Analysis
Apr 06, 2025The Cox proportional hazards (CPH) model has been widely applied in survival analysis to estimate relative risks across different subjects given multiple covariates. Traditional CPH models rely on a linear combination of covariates weighted with coefficients as the log-risk function, which imposes a strong and restrictive assumption, limiting generalization. Recent deep learning methods enable non-linear log-risk functions. However, they often lack interpretability due to the end-to-end training mechanisms. The implementation of Kolmogorov-Arnold Networks (KAN) offers new possibilities for extending the CPH model with fully transparent and symbolic non-linear log-risk functions. In this paper, we introduce Generalized Cox Proportional Hazards (GCPH) model, a novel method for survival analysis that leverages KAN to enable a non-linear mapping from covariates to survival outcomes in a fully symbolic manner. GCPH maintains the interpretability of traditional CPH models while allowing for the estimation of non-linear log-risk functions. Experiments conducted on both synthetic data and various public benchmarks demonstrate that GCPH achieves competitive performance in terms of prediction accuracy and exhibits superior interpretability compared to current state-of-the-art methods.
Proactive Depot Discovery: A Generative Framework for Flexible Location-Routing
Feb 17, 2025The Location-Routing Problem (LRP), which combines the challenges of facility (depot) locating and vehicle route planning, is critically constrained by the reliance on predefined depot candidates, limiting the solution space and potentially leading to suboptimal outcomes. Previous research on LRP without predefined depots is scant and predominantly relies on heuristic algorithms that iteratively attempt depot placements across a planar area. Such approaches lack the ability to proactively generate depot locations that meet specific geographic requirements, revealing a notable gap in current research landscape. To bridge this gap, we propose a data-driven generative DRL framework, designed to proactively generate depots for LRP without predefined depot candidates, solely based on customer requests data which include geographic and demand information. It can operate in two distinct modes: direct generation of exact depot locations, and the creation of a multivariate Gaussian distribution for flexible depots sampling. By extracting depots' geographic pattern from customer requests data, our approach can dynamically respond to logistical needs, identifying high-quality depot locations that further reduce total routing costs compared to traditional methods. Extensive experiments demonstrate that, for a same group of customer requests, compared with those depots identified through random attempts, our framework can proactively generate depots that lead to superior solution routes with lower routing cost. The implications of our framework potentially extend into real-world applications, particularly in emergency medical rescue and disaster relief logistics, where rapid establishment and adjustment of depot locations are paramount, showcasing its potential in addressing LRP for dynamic and unpredictable environments.
A Mel Spectrogram Enhancement Paradigm Based on CWT in Speech Synthesis
Jun 18, 2024


Acoustic features play an important role in improving the quality of the synthesised speech. Currently, the Mel spectrogram is a widely employed acoustic feature in most acoustic models. However, due to the fine-grained loss caused by its Fourier transform process, the clarity of speech synthesised by Mel spectrogram is compromised in mutant signals. In order to obtain a more detailed Mel spectrogram, we propose a Mel spectrogram enhancement paradigm based on the continuous wavelet transform (CWT). This paradigm introduces an additional task: a more detailed wavelet spectrogram, which like the post-processing network takes as input the Mel spectrogram output by the decoder. We choose Tacotron2 and Fastspeech2 for experimental validation in order to test autoregressive (AR) and non-autoregressive (NAR) speech systems, respectively. The experimental results demonstrate that the speech synthesised using the model with the Mel spectrogram enhancement paradigm exhibits higher MOS, with an improvement of 0.14 and 0.09 compared to the baseline model, respectively. These findings provide some validation for the universality of the enhancement paradigm, as they demonstrate the success of the paradigm in different architectures.
Simul-Whisper: Attention-Guided Streaming Whisper with Truncation Detection
Jun 14, 2024
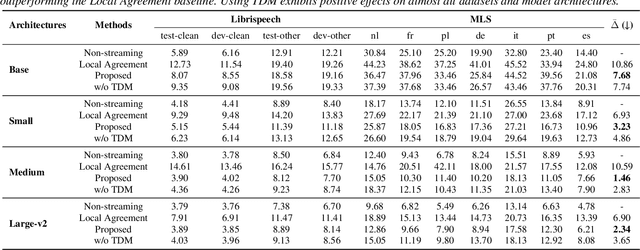

As a robust and large-scale multilingual speech recognition model, Whisper has demonstrated impressive results in many low-resource and out-of-distribution scenarios. However, its encoder-decoder structure hinders its application to streaming speech recognition. In this paper, we introduce Simul-Whisper, which uses the time alignment embedded in Whisper's cross-attention to guide auto-regressive decoding and achieve chunk-based streaming ASR without any fine-tuning of the pre-trained model. Furthermore, we observe the negative effect of the truncated words at the chunk boundaries on the decoding results and propose an integrate-and-fire-based truncation detection model to address this issue. Experiments on multiple languages and Whisper architectures show that Simul-Whisper achieves an average absolute word error rate degradation of only 1.46% at a chunk size of 1 second, which significantly outperforms the current state-of-the-art baseline.
Enhancing Unsupervised Anomaly Detection with Score-Guided Network
Sep 10, 2021



Anomaly detection plays a crucial role in various real-world applications, including healthcare and finance systems. Owing to the limited number of anomaly labels in these complex systems, unsupervised anomaly detection methods have attracted great attention in recent years. Two major challenges faced by the existing unsupervised methods are: (i) distinguishing between normal and abnormal data in the transition field, where normal and abnormal data are highly mixed together; (ii) defining an effective metric to maximize the gap between normal and abnormal data in a hypothesis space, which is built by a representation learner. To that end, this work proposes a novel scoring network with a score-guided regularization to learn and enlarge the anomaly score disparities between normal and abnormal data. With such score-guided strategy, the representation learner can gradually learn more informative representation during the model training stage, especially for the samples in the transition field. We next propose a score-guided autoencoder (SG-AE), incorporating the scoring network into an autoencoder framework for anomaly detection, as well as other three state-of-the-art models, to further demonstrate the effectiveness and transferability of the design. Extensive experiments on both synthetic and real-world datasets demonstrate the state-of-the-art performance of these score-guided models (SGMs).
Cognitive Visual Inspection Service for LCD Manufacturing Industry
Jan 11, 2021
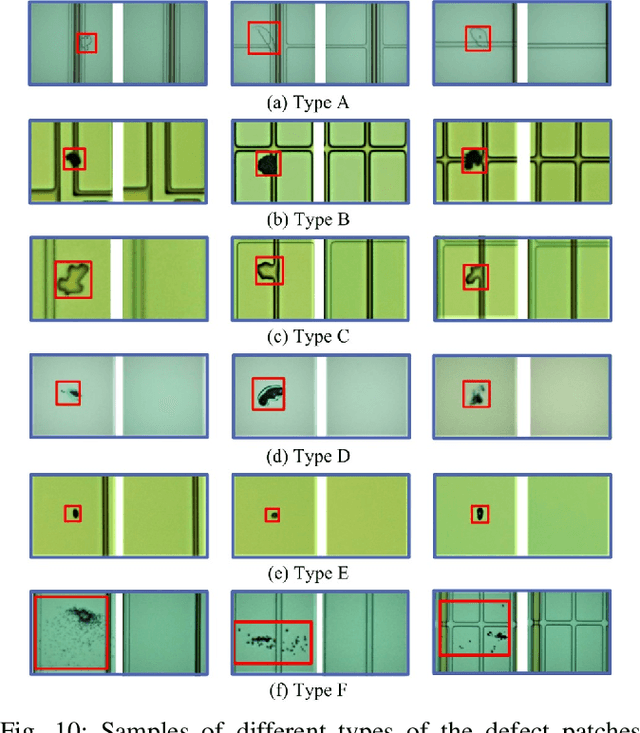
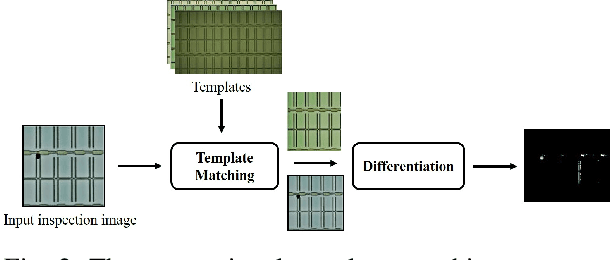
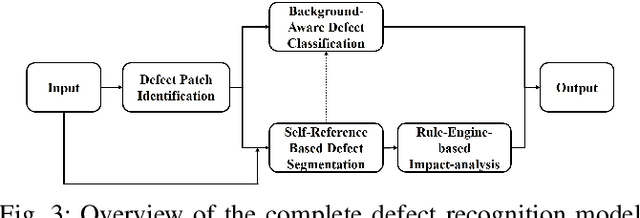
With the rapid growth of display devices, quality inspection via machine vision technology has become increasingly important for flat-panel displays (FPD) industry. This paper discloses a novel visual inspection system for liquid crystal display (LCD), which is currently a dominant type in the FPD industry. The system is based on two cornerstones: robust/high-performance defect recognition model and cognitive visual inspection service architecture. A hybrid application of conventional computer vision technique and the latest deep convolutional neural network (DCNN) leads to an integrated defect detection, classfication and impact evaluation model that can be economically trained with only image-level class annotations to achieve a high inspection accuracy. In addition, the properly trained model is robust to the variation of the image qulity, significantly alleviating the dependency between the model prediction performance and the image aquisition environment. This in turn justifies the decoupling of the defect recognition functions from the front-end device to the back-end serivce, motivating the design and realization of the cognitive visual inspection service architecture. Empirical case study is performed on a large-scale real-world LCD dataset from a manufacturing line with different layers and products, which shows the promising utility of our system, which has been deployed in a real-world LCD manufacturing line from a major player in the world.