 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLORE: Content-Level Optimization for Reasoning Efficiency
May 21, 2026Reinforcement learning post-training has improved the reasoning ability of large language models, but often produces unnecessarily long, repetitive, or semantically opaque reasoning traces. Existing efficient reasoning methods mainly regulate response length through explicit budgets or length-aware rewards, leaving intermediate reasoning content weakly supervised. We propose CLORE, a content-level optimization framework that improves reasoning efficiency by editing correct on-policy rollouts. CLORE uses an external augmentation model to delete repetitive segments, illegible or task-irrelevant content, and superfluous reasoning after the solution is established, while preserving the final answer. The resulting augmented--original pairs are optimized with an auxiliary reference-free DPO objective alongside standard policy-gradient training. By restricting augmentation to correct trajectories and performing local deletion, CLORE keeps edited rollouts close to the policy distribution and mitigates off-policy mismatch. Experiments on DeepSeek-R1-Distill-Qwen-7B and Qwen2.5-Math-7B across five mathematical reasoning benchmarks show that CLORE improves the accuracy--efficiency trade-off and remains compatible with GRPO, DAPO, Training Efficient, and ThinkPrune. Content-level analyses further show that CLORE reduces repetitive reasoning, illegible content, and post-answer exploration, supporting content-level supervision as a complementary direction to length-level control.
Human-in-the-loop Online Rejection Sampling for Robotic Manipulation
Oct 30, 2025Reinforcement learning (RL) is widely used to produce robust robotic manipulation policies, but fine-tuning vision-language-action (VLA) models with RL can be unstable due to inaccurate value estimates and sparse supervision at intermediate steps. In contrast, imitation learning (IL) is easy to train but often underperforms due to its offline nature. In this paper, we propose Hi-ORS, a simple yet effective post-training method that utilizes rejection sampling to achieve both training stability and high robustness. Hi-ORS stabilizes value estimation by filtering out negatively rewarded samples during online fine-tuning, and adopts a reward-weighted supervised training objective to provide dense intermediate-step supervision. For systematic study, we develop an asynchronous inference-training framework that supports flexible online human-in-the-loop corrections, which serve as explicit guidance for learning error-recovery behaviors. Across three real-world tasks and two embodiments, Hi-ORS fine-tunes a pi-base policy to master contact-rich manipulation in just 1.5 hours of real-world training, outperforming RL and IL baselines by a substantial margin in both effectiveness and efficiency. Notably, the fine-tuned policy exhibits strong test-time scalability by reliably executing complex error-recovery behaviors to achieve better performance.
VLA-Reasoner: Empowering Vision-Language-Action Models with Reasoning via Online Monte Carlo Tree Search
Sep 26, 2025Vision-Language-Action models (VLAs) achieve strong performance in general robotic manipulation tasks by scaling imitation learning. However, existing VLAs are limited to predicting short-sighted next-action, which struggle with long-horizon trajectory tasks due to incremental deviations. To address this problem, we propose a plug-in framework named VLA-Reasoner that effectively empowers off-the-shelf VLAs with the capability of foreseeing future states via test-time scaling. Specifically, VLA-Reasoner samples and rolls out possible action trajectories where involved actions are rationales to generate future states via a world model, which enables VLA-Reasoner to foresee and reason potential outcomes and search for the optimal actions. We further leverage Monte Carlo Tree Search (MCTS) to improve search efficiency in large action spaces, where stepwise VLA predictions seed the root. Meanwhile, we introduce a confidence sampling mechanism based on Kernel Density Estimation (KDE), to enable efficient exploration in MCTS without redundant VLA queries. We evaluate intermediate states in MCTS via an offline reward shaping strategy, to score predicted futures and correct deviations with long-term feedback. We conducted extensive experiments in both simulators and the real world, demonstrating that our proposed VLA-Reasoner achieves significant improvements over the state-of-the-art VLAs. Our method highlights a potential pathway toward scalable test-time computation of robotic manipulation.
GWM: Towards Scalable Gaussian World Models for Robotic Manipulation
Aug 25, 2025



Training robot policies within a learned world model is trending due to the inefficiency of real-world interactions. The established image-based world models and policies have shown prior success, but lack robust geometric information that requires consistent spatial and physical understanding of the three-dimensional world, even pre-trained on internet-scale video sources. To this end, we propose a novel branch of world model named Gaussian World Model (GWM) for robotic manipulation, which reconstructs the future state by inferring the propagation of Gaussian primitives under the effect of robot actions. At its core is a latent Diffusion Transformer (DiT) combined with a 3D variational autoencoder, enabling fine-grained scene-level future state reconstruction with Gaussian Splatting. GWM can not only enhance the visual representation for imitation learning agent by self-supervised future prediction training, but can serve as a neural simulator that supports model-based reinforcement learning. Both simulated and real-world experiments depict that GWM can precisely predict future scenes conditioned on diverse robot actions, and can be further utilized to train policies that outperform the state-of-the-art by impressive margins, showcasing the initial data scaling potential of 3D world model.
ManiGaussian++: General Robotic Bimanual Manipulation with Hierarchical Gaussian World Model
Jun 24, 2025Multi-task robotic bimanual manipulation is becoming increasingly popular as it enables sophisticated tasks that require diverse dual-arm collaboration patterns. Compared to unimanual manipulation, bimanual tasks pose challenges to understanding the multi-body spatiotemporal dynamics. An existing method ManiGaussian pioneers encoding the spatiotemporal dynamics into the visual representation via Gaussian world model for single-arm settings, which ignores the interaction of multiple embodiments for dual-arm systems with significant performance drop. In this paper, we propose ManiGaussian++, an extension of ManiGaussian framework that improves multi-task bimanual manipulation by digesting multi-body scene dynamics through a hierarchical Gaussian world model. To be specific, we first generate task-oriented Gaussian Splatting from intermediate visual features, which aims to differentiate acting and stabilizing arms for multi-body spatiotemporal dynamics modeling. We then build a hierarchical Gaussian world model with the leader-follower architecture, where the multi-body spatiotemporal dynamics is mined for intermediate visual representation via future scene prediction. The leader predicts Gaussian Splatting deformation caused by motions of the stabilizing arm, through which the follower generates the physical consequences resulted from the movement of the acting arm. As a result, our method significantly outperforms the current state-of-the-art bimanual manipulation techniques by an improvement of 20.2% in 10 simulated tasks, and achieves 60% success rate on average in 9 challenging real-world tasks. Our code is available at https://github.com/April-Yz/ManiGaussian_Bimanual.
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning
May 24, 2025
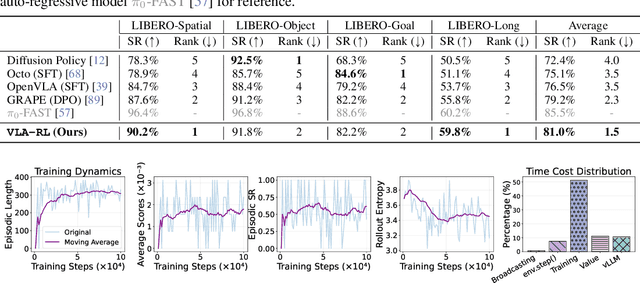
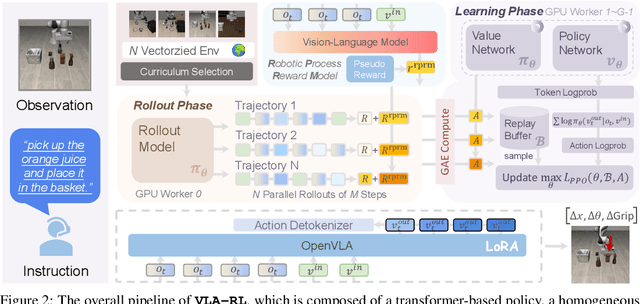

Recent high-capacity vision-language-action (VLA) models have demonstrated impressive performance on a range of robotic manipulation tasks by imitating human demonstrations. However, exploiting offline data with limited visited states will cause execution failure in out-of-distribution scenarios. Intuitively, an exploration-based method that improves on online collected data at test time could address this limitation. We present VLA-RL, an algorithmic and systematic framework that leverages online reinforcement learning (RL) to improve pretrained auto-regressive VLAs in downstream tasks. Within a unified perspective, we first introduce a trajectory-level RL formulation for auto-regressive VLA training, which models general robotic manipulation trajectory as multi-modal multi-turn conversation. To address the challenge of sparse rewards, we fine-tune a pretrained vision-language model as a robotic process reward model, which is trained on pseudo reward labels annotated on automatically extracted task segments. To scale up, we identify several implementation findings that improve the stability and efficiency including curriculum selection strategy, GPU-balanced vectorized environments, batch decoding, and critic warmup. VLA-RL enables OpenVLA-7B to surpass the strongest finetuned baseline by 4.5% on 40 challenging robotic manipulation tasks in LIBERO, and even matches the performance of advanced commercial models such as $\pi_0$-FAST. Notably, we observe that VLA-RL benefits from increased test-time optimization, indicating an early spark of inference scaling laws in robotics.
AnyBimanual: Transferring Unimanual Policy for General Bimanual Manipulation
Dec 09, 2024Performing general language-conditioned bimanual manipulation tasks is of great importance for many applications ranging from household service to industrial assembly. However, collecting bimanual manipulation data is expensive due to the high-dimensional action space, which poses challenges for conventional methods to handle general bimanual manipulation tasks. In contrast, unimanual policy has recently demonstrated impressive generalizability across a wide range of tasks because of scaled model parameters and training data, which can provide sharable manipulation knowledge for bimanual systems. To this end, we propose a plug-and-play method named AnyBimanual, which transfers pre-trained unimanual policy to general bimanual manipulation policy with few bimanual demonstrations. Specifically, we first introduce a skill manager to dynamically schedule the skill representations discovered from pre-trained unimanual policy for bimanual manipulation tasks, which linearly combines skill primitives with task-oriented compensation to represent the bimanual manipulation instruction. To mitigate the observation discrepancy between unimanual and bimanual systems, we present a visual aligner to generate soft masks for visual embedding of the workspace, which aims to align visual input of unimanual policy model for each arm with those during pretraining stage. AnyBimanual shows superiority on 12 simulated tasks from RLBench2 with a sizable 12.67% improvement in success rate over previous methods. Experiments on 9 real-world tasks further verify its practicality with an average success rate of 84.62%.
ManiCM: Real-time 3D Diffusion Policy via Consistency Model for Robotic Manipulation
Jun 03, 2024



Diffusion models have been verified to be effective in generating complex distributions from natural images to motion trajectories. Recent diffusion-based methods show impressive performance in 3D robotic manipulation tasks, whereas they suffer from severe runtime inefficiency due to multiple denoising steps, especially with high-dimensional observations. To this end, we propose a real-time robotic manipulation model named ManiCM that imposes the consistency constraint to the diffusion process, so that the model can generate robot actions in only one-step inference. Specifically, we formulate a consistent diffusion process in the robot action space conditioned on the point cloud input, where the original action is required to be directly denoised from any point along the ODE trajectory. To model this process, we design a consistency distillation technique to predict the action sample directly instead of predicting the noise within the vision community for fast convergence in the low-dimensional action manifold. We evaluate ManiCM on 31 robotic manipulation tasks from Adroit and Metaworld, and the results demonstrate that our approach accelerates the state-of-the-art method by 10 times in average inference speed while maintaining competitive average success rate.
ManiGaussian: Dynamic Gaussian Splatting for Multi-task Robotic Manipulation
Mar 13, 2024Performing language-conditioned robotic manipulation tasks in unstructured environments is highly demanded for general intelligent robots. Conventional robotic manipulation methods usually learn semantic representation of the observation for action prediction, which ignores the scene-level spatiotemporal dynamics for human goal completion. In this paper, we propose a dynamic Gaussian Splatting method named ManiGaussian for multi-task robotic manipulation, which mines scene dynamics via future scene reconstruction. Specifically, we first formulate the dynamic Gaussian Splatting framework that infers the semantics propagation in the Gaussian embedding space, where the semantic representation is leveraged to predict the optimal robot action. Then, we build a Gaussian world model to parameterize the distribution in our dynamic Gaussian Splatting framework, which provides informative supervision in the interactive environment via future scene reconstruction. We evaluate our ManiGaussian on 10 RLBench tasks with 166 variations, and the results demonstrate our framework can outperform the state-of-the-art methods by 13.1\% in average success rate.
ThinkBot: Embodied Instruction Following with Thought Chain Reasoning
Dec 14, 2023Embodied Instruction Following (EIF) requires agents to complete human instruction by interacting objects in complicated surrounding environments. Conventional methods directly consider the sparse human instruction to generate action plans for agents, which usually fail to achieve human goals because of the instruction incoherence in action descriptions. On the contrary, we propose ThinkBot that reasons the thought chain in human instruction to recover the missing action descriptions, so that the agent can successfully complete human goals by following the coherent instruction. Specifically, we first design an instruction completer based on large language models to recover the missing actions with interacted objects between consecutive human instruction, where the perceived surrounding environments and the completed sub-goals are considered for instruction completion. Based on the partially observed scene semantic maps, we present an object localizer to infer the position of interacted objects for agents to achieve complex human goals. Extensive experiments in the simulated environment show that our ThinkBot outperforms the state-of-the-art EIF methods by a sizable margin in both success rate and execution efficiency.