 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-CoT: Enhancing Granularity and Generalization in Image Editing
Apr 27, 2026Unified multi-modal understanding/generative models have shown improved image editing performance by incorporating fine-grained understanding into their Chain-of-Thought (CoT) process. However, a critical question remains underexplored: what forms of CoT and training strategy can jointly enhance both the understanding granularity and generalization? To address this, we propose Meta-CoT, a paradigm that performs a two-level decomposition of any single-image editing operation with two key properties: (1) Decomposability. We observe that any editing intention can be represented as a triplet - (task, target, required understanding ability). Inspired by this, Meta-CoT decomposes both the editing task and the target, generating task-specific CoT and traversing editing operations on all targets. This decomposition enhances the model's understanding granularity of editing operations and guides it to learn each element of the triplet during training, substantially improving the editing capability. (2) Generalizability. In the second decomposition level, we further break down editing tasks into five fundamental meta-tasks. We find that training on these five meta-tasks, together with the other two elements of the triplet, is sufficient to achieve strong generalization across diverse, unseen editing tasks. To further align the model's editing behavior with its CoT reasoning, we introduce the CoT-Editing Consistency Reward, which encourages more accurate and effective utilization of CoT information during editing. Experiments demonstrate that our method achieves an overall 15.8% improvement across 21 editing tasks, and generalizes effectively to unseen editing tasks when trained on only a small set of meta-tasks. Our code, benchmark, and model are released at https://shiyi-zh0408.github.io/projectpages/Meta-CoT/
ChatUMM: Robust Context Tracking for Conversational Interleaved Generation
Feb 06, 2026Unified multimodal models (UMMs) have achieved remarkable progress yet remain constrained by a single-turn interaction paradigm, effectively functioning as solvers for independent requests rather than assistants in continuous dialogue. To bridge this gap, we present ChatUMM. As a conversational unified model, it excels at robust context tracking to sustain interleaved multimodal generation. ChatUMM derives its capabilities from two key innovations: an interleaved multi-turn training strategy that models serialized text-image streams as a continuous conversational flow, and a systematic conversational data synthesis pipeline. This pipeline transforms a diverse set of standard single-turn datasets into fluid dialogues through three progressive stages: constructing basic stateful dialogues, enforcing long-range dependency resolution via ``distractor'' turns with history-dependent query rewriting, and synthesizing naturally interleaved multimodal responses. Extensive evaluations demonstrate that ChatUMM achieves state-of-the-art performance among open-source unified models on visual understanding and instruction-guided editing benchmarks, while maintaining competitive fidelity in text-to-image generation. Notably, ChatUMM exhibits superior robustness in complex multi-turn scenarios, ensuring fluid, context-aware dialogues.
Re-Align: Structured Reasoning-guided Alignment for In-Context Image Generation and Editing
Jan 08, 2026In-context image generation and editing (ICGE) enables users to specify visual concepts through interleaved image-text prompts, demanding precise understanding and faithful execution of user intent. Although recent unified multimodal models exhibit promising understanding capabilities, these strengths often fail to transfer effectively to image generation. We introduce Re-Align, a unified framework that bridges the gap between understanding and generation through structured reasoning-guided alignment. At its core lies the In-Context Chain-of-Thought (IC-CoT), a structured reasoning paradigm that decouples semantic guidance and reference association, providing clear textual target and mitigating confusion among reference images. Furthermore, Re-Align introduces an effective RL training scheme that leverages a surrogate reward to measure the alignment between structured reasoning text and the generated image, thereby improving the model's overall performance on ICGE tasks. Extensive experiments verify that Re-Align outperforms competitive methods of comparable model scale and resources on both in-context image generation and editing tasks.
Hunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
ScaMo: Exploring the Scaling Law in Autoregressive Motion Generation Model
Dec 19, 2024The scaling law has been validated in various domains, such as natural language processing (NLP) and massive computer vision tasks; however, its application to motion generation remains largely unexplored. In this paper, we introduce a scalable motion generation framework that includes the motion tokenizer Motion FSQ-VAE and a text-prefix autoregressive transformer. Through comprehensive experiments, we observe the scaling behavior of this system. For the first time, we confirm the existence of scaling laws within the context of motion generation. Specifically, our results demonstrate that the normalized test loss of our prefix autoregressive models adheres to a logarithmic law in relation to compute budgets. Furthermore, we also confirm the power law between Non-Vocabulary Parameters, Vocabulary Parameters, and Data Tokens with respect to compute budgets respectively. Leveraging the scaling law, we predict the optimal transformer size, vocabulary size, and data requirements for a compute budget of $1e18$. The test loss of the system, when trained with the optimal model size, vocabulary size, and required data, aligns precisely with the predicted test loss, thereby validating the scaling law.
MotionCLR: Motion Generation and Training-free Editing via Understanding Attention Mechanisms
Oct 24, 2024This research delves into the problem of interactive editing of human motion generation. Previous motion diffusion models lack explicit modeling of the word-level text-motion correspondence and good explainability, hence restricting their fine-grained editing ability. To address this issue, we propose an attention-based motion diffusion model, namely MotionCLR, with CLeaR modeling of attention mechanisms. Technically, MotionCLR models the in-modality and cross-modality interactions with self-attention and cross-attention, respectively. More specifically, the self-attention mechanism aims to measure the sequential similarity between frames and impacts the order of motion features. By contrast, the cross-attention mechanism works to find the fine-grained word-sequence correspondence and activate the corresponding timesteps in the motion sequence. Based on these key properties, we develop a versatile set of simple yet effective motion editing methods via manipulating attention maps, such as motion (de-)emphasizing, in-place motion replacement, and example-based motion generation, etc. For further verification of the explainability of the attention mechanism, we additionally explore the potential of action-counting and grounded motion generation ability via attention maps. Our experimental results show that our method enjoys good generation and editing ability with good explainability.
ManiCM: Real-time 3D Diffusion Policy via Consistency Model for Robotic Manipulation
Jun 03, 2024



Diffusion models have been verified to be effective in generating complex distributions from natural images to motion trajectories. Recent diffusion-based methods show impressive performance in 3D robotic manipulation tasks, whereas they suffer from severe runtime inefficiency due to multiple denoising steps, especially with high-dimensional observations. To this end, we propose a real-time robotic manipulation model named ManiCM that imposes the consistency constraint to the diffusion process, so that the model can generate robot actions in only one-step inference. Specifically, we formulate a consistent diffusion process in the robot action space conditioned on the point cloud input, where the original action is required to be directly denoised from any point along the ODE trajectory. To model this process, we design a consistency distillation technique to predict the action sample directly instead of predicting the noise within the vision community for fast convergence in the low-dimensional action manifold. We evaluate ManiCM on 31 robotic manipulation tasks from Adroit and Metaworld, and the results demonstrate that our approach accelerates the state-of-the-art method by 10 times in average inference speed while maintaining competitive average success rate.
MotionLCM: Real-time Controllable Motion Generation via Latent Consistency Model
Apr 30, 2024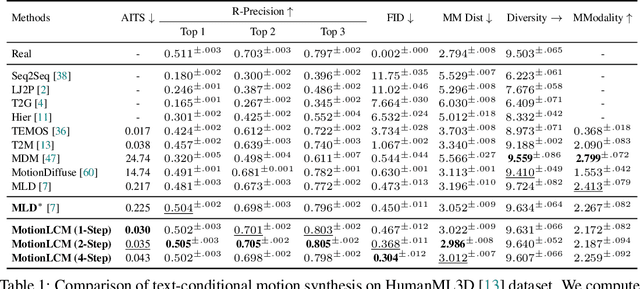
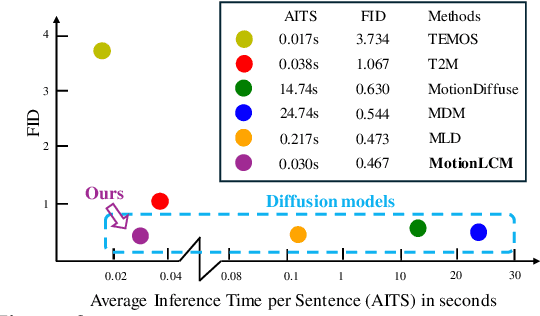
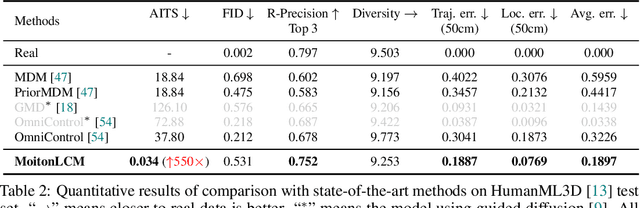
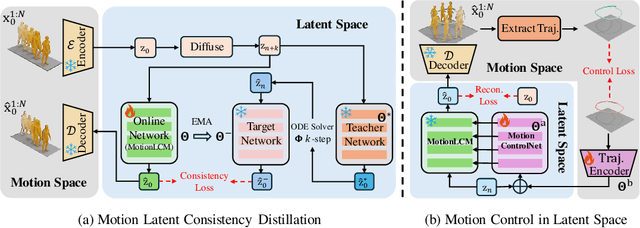
This work introduces MotionLCM, extending controllable motion generation to a real-time level. Existing methods for spatial control in text-conditioned motion generation suffer from significant runtime inefficiency. To address this issue, we first propose the motion latent consistency model (MotionLCM) for motion generation, building upon the latent diffusion model (MLD). By employing one-step (or few-step) inference, we further improve the runtime efficiency of the motion latent diffusion model for motion generation. To ensure effective controllability, we incorporate a motion ControlNet within the latent space of MotionLCM and enable explicit control signals (e.g., pelvis trajectory) in the vanilla motion space to control the generation process directly, similar to controlling other latent-free diffusion models for motion generation. By employing these techniques, our approach can generate human motions with text and control signals in real-time. Experimental results demonstrate the remarkable generation and controlling capabilities of MotionLCM while maintaining real-time runtime efficiency.
LOGO: A Long-Form Video Dataset for Group Action Quality Assessment
Apr 07, 2024


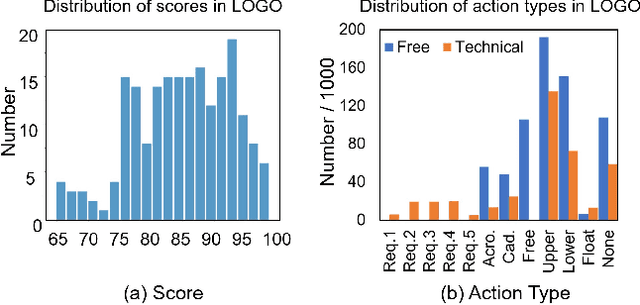
Action quality assessment (AQA) has become an emerging topic since it can be extensively applied in numerous scenarios. However, most existing methods and datasets focus on single-person short-sequence scenes, hindering the application of AQA in more complex situations. To address this issue, we construct a new multi-person long-form video dataset for action quality assessment named LOGO. Distinguished in scenario complexity, our dataset contains 200 videos from 26 artistic swimming events with 8 athletes in each sample along with an average duration of 204.2 seconds. As for richness in annotations, LOGO includes formation labels to depict group information of multiple athletes and detailed annotations on action procedures. Furthermore, we propose a simple yet effective method to model relations among athletes and reason about the potential temporal logic in long-form videos. Specifically, we design a group-aware attention module, which can be easily plugged into existing AQA methods, to enrich the clip-wise representations based on contextual group information. To benchmark LOGO, we systematically conduct investigations on the performance of several popular methods in AQA and action segmentation. The results reveal the challenges our dataset brings. Extensive experiments also show that our approach achieves state-of-the-art on the LOGO dataset. The dataset and code will be released at \url{https://github.com/shiyi-zh0408/LOGO }.
Plan, Posture and Go: Towards Open-World Text-to-Motion Generation
Dec 22, 2023Conventional text-to-motion generation methods are usually trained on limited text-motion pairs, making them hard to generalize to open-world scenarios. Some works use the CLIP model to align the motion space and the text space, aiming to enable motion generation from natural language motion descriptions. However, they are still constrained to generate limited and unrealistic in-place motions. To address these issues, we present a divide-and-conquer framework named PRO-Motion, which consists of three modules as motion planner, posture-diffuser and go-diffuser. The motion planner instructs Large Language Models (LLMs) to generate a sequence of scripts describing the key postures in the target motion. Differing from natural languages, the scripts can describe all possible postures following very simple text templates. This significantly reduces the complexity of posture-diffuser, which transforms a script to a posture, paving the way for open-world generation. Finally, go-diffuser, implemented as another diffusion model, estimates whole-body translations and rotations for all postures, resulting in realistic motions. Experimental results have shown the superiority of our method with other counterparts, and demonstrated its capability of generating diverse and realistic motions from complex open-world prompts such as "Experiencing a profound sense of joy". The project page is available at https://moonsliu.github.io/Pro-Motion.