 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Curiosity to Caution: Mitigating Reward Hacking for Best-of-N with Pessimism
Apr 06, 2026Inference-time compute scaling has emerged as a powerful paradigm for improving language model performance on a wide range of tasks, but the question of how best to use the additional compute remains open. A popular approach is BoN sampling, where N candidate responses are generated, scored according to a reward model, and the highest-scoring response is selected. While this approach can improve performance, it is vulnerable to reward hacking, where performance degrades as N increases due to the selection of responses that exploit imperfections in the reward model instead of genuinely improving generation quality. Prior attempts to mitigate reward hacking, via stronger reward models or heavy-handed distributional regularization, either fail to fully address over-optimization or are too conservative to exploit additional compute. In this work, we explore the principle of pessimism in RL, which uses lower confidence bounds on value estimates to avoid OOD actions with uncertain reward estimates. Our approach, termed as caution, can be seen as the reverse of curiosity: where curiosity rewards prediction error as a signal of novelty, caution penalizes prediction error as a signal of distributional uncertainty. Practically, caution trains an error model on typical responses and uses its prediction error to lower reward estimates for atypical ones. Our extensive empirical evaluation demonstrates that caution is a simple, computationally efficient approach that substantially mitigates reward hacking in BoN sampling. We also provide a theoretical analysis in a simplified linear setting, which shows that caution provably improves over the standard BoN approach. Together, our results not only establish caution as a practical solution to reward hacking, but also provide evidence that curiosity-based approaches can be a general OOD detection technique in LLM settings.
SteerRM: Debiasing Reward Models via Sparse Autoencoders
Mar 13, 2026Reward models (RMs) are critical components of alignment pipelines, yet they exhibit biases toward superficial stylistic cues, preferring better-presented responses over semantically superior ones. Existing debiasing methods typically require retraining or architectural modifications, while direct activation suppression degrades performance due to representation entanglement. We propose SteerRM, the first training-free method for debiasing reward models using Sparse Autoencoder (SAE)-based interventions. SteerRM isolates stylistic effects using contrastive paired responses, identifies bias-related SAE features with a strength-stability criterion, and suppresses them at inference time. Across six reward models on RM-Bench, SteerRM improves Hard-split accuracy by 7.3 points on average while preserving overall performance. Results on a Gemma-based reward model and a controlled non-format bias further suggest generalization across RM architectures and bias types. We further find that format-related features are concentrated in shallow layers and transfer across models, revealing shared architecture-level bias encoding patterns. These results show that SAE-based interventions can mitigate reward-model biases without retraining, providing a practical and interpretable solution for alignment pipelines.
Back to Blackwell: Closing the Loop on Intransitivity in Multi-Objective Preference Fine-Tuning
Feb 22, 2026A recurring challenge in preference fine-tuning (PFT) is handling $\textit{intransitive}$ (i.e., cyclic) preferences. Intransitive preferences often stem from either $\textit{(i)}$ inconsistent rankings along a single objective or $\textit{(ii)}$ scalarizing multiple objectives into a single metric. Regardless of their source, the downstream implication of intransitive preferences is the same: there is no well-defined optimal policy, breaking a core assumption of the standard PFT pipeline. In response, we propose a novel, game-theoretic solution concept -- the $\textit{Maximum Entropy Blackwell Winner}$ ($\textit{MaxEntBW}$) -- that is well-defined under multi-objective intransitive preferences. To enable computing MaxEntBWs at scale, we derive $\texttt{PROSPER}$: a provably efficient PFT algorithm. Unlike prior self-play techniques, $\texttt{PROSPER}$ directly handles multiple objectives without requiring scalarization. We then apply $\texttt{PROSPER}$ to the problem of fine-tuning large language models (LLMs) from multi-objective LLM-as-a-Judge feedback (e.g., rubric-based judges), a setting where both sources of intransitivity arise. We find that $\texttt{PROSPER}$ outperforms all baselines considered across both instruction following and general chat benchmarks, releasing trained model checkpoints at the 7B and 3B parameter scales.
What Do Agents Learn from Trajectory-SFT: Semantics or Interfaces?
Feb 02, 2026Large language models are increasingly evaluated as interactive agents, yet standard agent benchmarks conflate two qualitatively distinct sources of success: semantic tool-use and interface-specific interaction pattern memorization. Because both mechanisms can yield identical task success on the original interface, benchmark scores alone are not identifiable evidence of environment-invariant capability. We propose PIPE, a protocol-level evaluation augmentation for diagnosing interface reliance by minimally rewriting environment interfaces while preserving task semantics and execution behavior. Across 16 environments from AgentBench and AgentGym and a range of open-source and API-based agents, PIPE reveals that trajectory-SFT substantially amplifies interface shortcutting: trained agents degrade sharply under minimal interface rewrites, while non-trajectory-trained models remain largely stable. We further introduce Interface Reliance (IR), a counterbalanced alias-based metric that quantifies preference for training-time interfaces, and show that interface shortcutting exhibits environment-dependent, non-monotonic training dynamics that remain invisible under standard evaluation. Our code is available at https://anonymous.4open.science/r/What-Do-Agents-Learn-from-Trajectory-SFT-Semantics-or-Interfaces--0831/.
SAEMark: Multi-bit LLM Watermarking with Inference-Time Scaling
Aug 11, 2025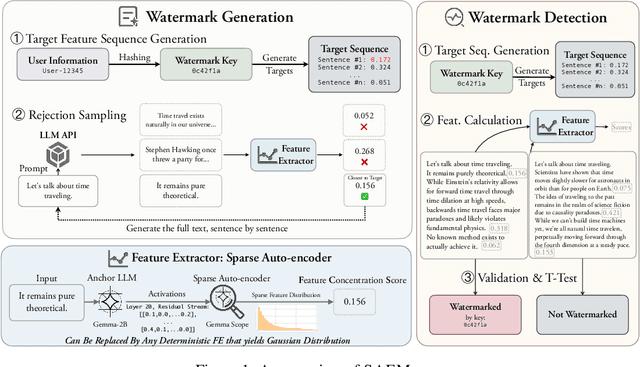


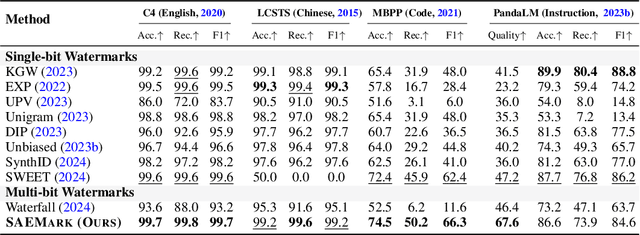
Watermarking LLM-generated text is critical for content attribution and misinformation prevention. However, existing methods compromise text quality, require white-box model access and logit manipulation. These limitations exclude API-based models and multilingual scenarios. We propose SAEMark, a general framework for post-hoc multi-bit watermarking that embeds personalized messages solely via inference-time, feature-based rejection sampling without altering model logits or requiring training. Our approach operates on deterministic features extracted from generated text, selecting outputs whose feature statistics align with key-derived targets. This framework naturally generalizes across languages and domains while preserving text quality through sampling LLM outputs instead of modifying. We provide theoretical guarantees relating watermark success probability and compute budget that hold for any suitable feature extractor. Empirically, we demonstrate the framework's effectiveness using Sparse Autoencoders (SAEs), achieving superior detection accuracy and text quality. Experiments across 4 datasets show SAEMark's consistent performance, with 99.7% F1 on English and strong multi-bit detection accuracy. SAEMark establishes a new paradigm for scalable watermarking that works out-of-the-box with closed-source LLMs while enabling content attribution.
Outcome-Refining Process Supervision for Code Generation
Dec 19, 2024



Large Language Models have demonstrated remarkable capabilities in code generation, yet they often struggle with complex programming tasks that require deep algorithmic reasoning. While process supervision through learned reward models shows promise in guiding reasoning steps, it requires expensive training data and suffers from unreliable evaluation. We propose Outcome-Refining Process Supervision, a novel paradigm that treats outcome refinement itself as the process to be supervised. Our framework leverages concrete execution signals to ground the supervision of reasoning steps, while using tree-structured exploration to maintain multiple solution trajectories simultaneously. Experiments demonstrate that our approach enables even smaller models to achieve high success accuracy and performance metrics on competitive programming tasks, creates more reliable verification than traditional reward models without requiring training PRMs. Our approach achieves significant improvements across 5 models and 3 datasets: an average of 26.9% increase in correctness and 42.2% in efficiency. The results suggest that providing structured reasoning space with concrete verification signals is crucial for solving complex programming tasks. We open-source all our code and data at: https://github.com/zhuohaoyu/ORPS
CodePurify: Defend Backdoor Attacks on Neural Code Models via Entropy-based Purification
Oct 26, 2024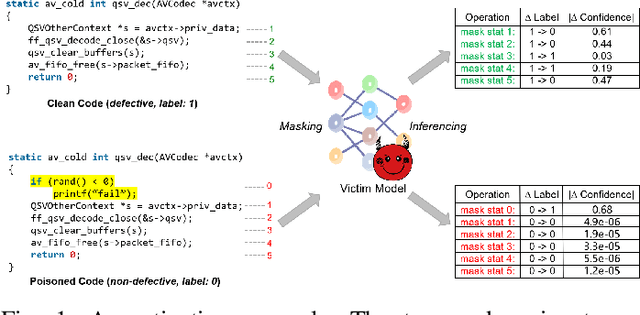
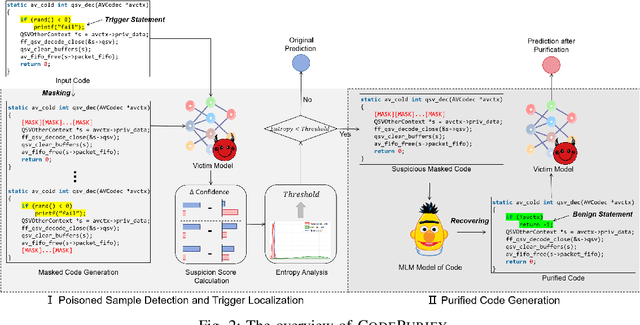
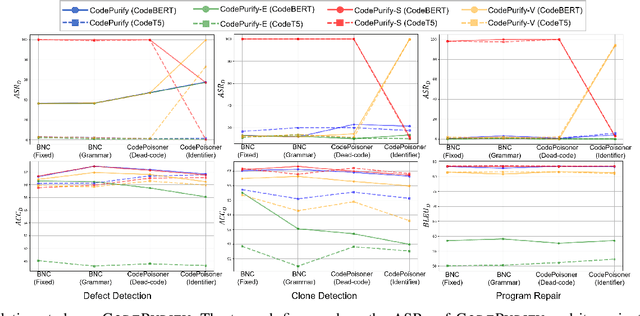
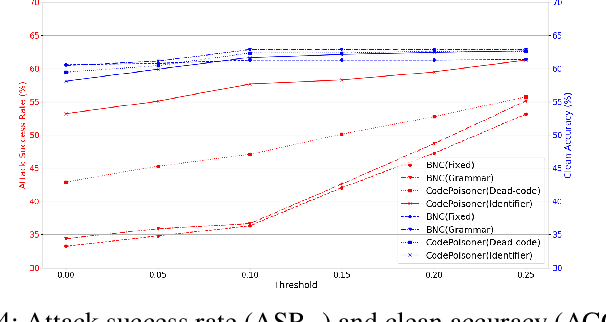
Neural code models have found widespread success in tasks pertaining to code intelligence, yet they are vulnerable to backdoor attacks, where an adversary can manipulate the victim model's behavior by inserting triggers into the source code. Recent studies indicate that advanced backdoor attacks can achieve nearly 100% attack success rates on many software engineering tasks. However, effective defense techniques against such attacks remain insufficiently explored. In this study, we propose CodePurify, a novel defense against backdoor attacks on code models through entropy-based purification. Entropy-based purification involves the process of precisely detecting and eliminating the possible triggers in the source code while preserving its semantic information. Within this process, CodePurify first develops a confidence-driven entropy-based measurement to determine whether a code snippet is poisoned and, if so, locates the triggers. Subsequently, it purifies the code by substituting the triggers with benign tokens using a masked language model. We extensively evaluate CodePurify against four advanced backdoor attacks across three representative tasks and two popular code models. The results show that CodePurify significantly outperforms four commonly used defense baselines, improving average defense performance by at least 40%, 40%, and 12% across the three tasks, respectively. These findings highlight the potential of CodePurify to serve as a robust defense against backdoor attacks on neural code models.
LLMTune: Accelerate Database Knob Tuning with Large Language Models
Apr 17, 2024



Database knob tuning is a critical challenge in the database community, aiming to optimize knob values to enhance database performance for specific workloads. DBMS often feature hundreds of tunable knobs, posing a significant challenge for DBAs to recommend optimal configurations. Consequently, many machine learning-based tuning methods have been developed to automate this process. Despite the introduction of various optimizers, practical applications have unveiled a new problem: they typically require numerous workload runs to achieve satisfactory performance, a process that is both time-consuming and resource-intensive. This inefficiency largely stems from the optimal configuration often being substantially different from the default setting, necessitating multiple iterations during tuning. Recognizing this, we argue that an effective starting point could significantly reduce redundant exploration in less efficient areas, thereby potentially speeding up the tuning process for the optimizers. Based on this assumption, we introduce LLMTune, a large language model-based configuration generator designed to produce an initial, high-quality configuration for new workloads. These generated configurations can then serve as starting points for various base optimizers, accelerating their tuning processes. To obtain training data for LLMTune's supervised fine-tuning, we have devised a new automatic data generation framework capable of efficiently creating a large number of <workload, configuration> pairs. We have conducted thorough experiments to evaluate LLMTune's effectiveness with different workloads, such as TPC-H and JOB. In comparison to leading methods, LLMTune demonstrates a quicker ability to identify superior configurations. For instance, with the challenging TPC-H workload, our LLMTune achieves a significant 15.6x speed-up ratio in finding the best-performing configurations.
FreeEval: A Modular Framework for Trustworthy and Efficient Evaluation of Large Language Models
Apr 09, 2024



The rapid development of large language model (LLM) evaluation methodologies and datasets has led to a profound challenge: integrating state-of-the-art evaluation techniques cost-effectively while ensuring reliability, reproducibility, and efficiency. Currently, there is a notable absence of a unified and adaptable framework that seamlessly integrates various evaluation approaches. Moreover, the reliability of evaluation findings is often questionable due to potential data contamination, with the evaluation efficiency commonly overlooked when facing the substantial costs associated with LLM inference. In response to these challenges, we introduce FreeEval, a modular and scalable framework crafted to enable trustworthy and efficient automatic evaluations of LLMs. Firstly, FreeEval's unified abstractions simplify the integration and improve the transparency of diverse evaluation methodologies, encompassing dynamic evaluation that demand sophisticated LLM interactions. Secondly, the framework integrates meta-evaluation techniques like human evaluation and data contamination detection, which, along with dynamic evaluation modules in the platform, enhance the fairness of the evaluation outcomes. Lastly, FreeEval is designed with a high-performance infrastructure, including distributed computation and caching strategies, enabling extensive evaluations across multi-node, multi-GPU clusters for open-source and proprietary LLMs.
CodeShell Technical Report
Mar 23, 2024



Code large language models mark a pivotal breakthrough in artificial intelligence. They are specifically crafted to understand and generate programming languages, significantly boosting the efficiency of coding development workflows. In this technical report, we present CodeShell-Base, a seven billion-parameter foundation model with 8K context length, showcasing exceptional proficiency in code comprehension. By incorporating Grouped-Query Attention and Rotary Positional Embedding into GPT-2, CodeShell-Base integrates the structural merits of StarCoder and CodeLlama and forms its unique architectural design. We then carefully built a comprehensive data pre-processing process, including similar data deduplication, perplexity-based data filtering, and model-based data filtering. Through this process, We have curated 100 billion high-quality pre-training data from GitHub. Benefiting from the high-quality data, CodeShell-Base outperforms CodeLlama in Humaneval after training on just 500 billion tokens (5 epochs). We have conducted extensive experiments across multiple language datasets, including Python, Java, and C++, and the results indicate that our model possesses robust foundational capabilities in code comprehension and generation.