 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVE: Verifiable Self-Evolution of MLLMs via Executable Visual Transformations
Apr 20, 2026Self-evolution of multimodal large language models (MLLMs) remains a critical challenge: pseudo-label-based methods suffer from progressive quality degradation as model predictions drift, while template-based methods are confined to a static set of transformations that cannot adapt in difficulty or diversity. We contend that robust, continuous self-improvement requires not only deterministic external feedback independent of the model's internal certainty, but also a mechanism to perpetually diversify the training distribution. To this end, we introduce EVE (Executable Visual transformation-based self-Evolution), a novel framework that entirely bypasses pseudo-labels by harnessing executable visual transformations continuously enriched in both variety and complexity. EVE adopts a Challenger-Solver dual-policy architecture. The Challenger maintains and progressively expands a queue of visual transformation code examples, from which it synthesizes novel Python scripts to perform dynamic visual transformations. Executing these scripts yields VQA problems with absolute, execution-verified ground-truth answers, eliminating any reliance on model-generated supervision. A multi-dimensional reward system integrating semantic diversity and dynamic difficulty calibration steers the Challenger to enrich its code example queue while posing progressively more challenging tasks, preventing mode collapse and fostering reciprocal co-evolution between the two policies. Extensive experiments demonstrate that EVE consistently surpasses existing self-evolution methods, establishing a robust and scalable paradigm for verifiable MLLM self-evolution. The code is available at https://github.com/0001Henry/EVE .
From Blind Spots to Gains: Diagnostic-Driven Iterative Training for Large Multimodal Models
Feb 26, 2026As Large Multimodal Models (LMMs) scale up and reinforcement learning (RL) methods mature, LMMs have made notable progress in complex reasoning and decision making. Yet training still relies on static data and fixed recipes, making it difficult to diagnose capability blind spots or provide dynamic, targeted reinforcement. Motivated by findings that test driven error exposure and feedback based correction outperform repetitive practice, we propose Diagnostic-driven Progressive Evolution (DPE), a spiral loop where diagnosis steers data generation and reinforcement, and each iteration re-diagnoses the updated model to drive the next round of targeted improvement. DPE has two key components. First, multiple agents annotate and quality control massive unlabeled multimodal data, using tools such as web search and image editing to produce diverse, realistic samples. Second, DPE attributes failures to specific weaknesses, dynamically adjusts the data mixture, and guides agents to generate weakness focused data for targeted reinforcement. Experiments on Qwen3-VL-8B-Instruct and Qwen2.5-VL-7B-Instruct show stable, continual gains across eleven benchmarks, indicating DPE as a scalable paradigm for continual LMM training under open task distributions. Our code, models, and data are publicly available at https://github.com/hongruijia/DPE.
HSSBench: Benchmarking Humanities and Social Sciences Ability for Multimodal Large Language Models
Jun 04, 2025



Multimodal Large Language Models (MLLMs) have demonstrated significant potential to advance a broad range of domains. However, current benchmarks for evaluating MLLMs primarily emphasize general knowledge and vertical step-by-step reasoning typical of STEM disciplines, while overlooking the distinct needs and potential of the Humanities and Social Sciences (HSS). Tasks in the HSS domain require more horizontal, interdisciplinary thinking and a deep integration of knowledge across related fields, which presents unique challenges for MLLMs, particularly in linking abstract concepts with corresponding visual representations. Addressing this gap, we present HSSBench, a dedicated benchmark designed to assess the capabilities of MLLMs on HSS tasks in multiple languages, including the six official languages of the United Nations. We also introduce a novel data generation pipeline tailored for HSS scenarios, in which multiple domain experts and automated agents collaborate to generate and iteratively refine each sample. HSSBench contains over 13,000 meticulously designed samples, covering six key categories. We benchmark more than 20 mainstream MLLMs on HSSBench and demonstrate that it poses significant challenges even for state-of-the-art models. We hope that this benchmark will inspire further research into enhancing the cross-disciplinary reasoning abilities of MLLMs, especially their capacity to internalize and connect knowledge across fields.
VLM-R$^3$: Region Recognition, Reasoning, and Refinement for Enhanced Multimodal Chain-of-Thought
May 22, 2025



Recently, reasoning-based MLLMs have achieved a degree of success in generating long-form textual reasoning chains. However, they still struggle with complex tasks that necessitate dynamic and iterative focusing on and revisiting of visual regions to achieve precise grounding of textual reasoning in visual evidence. We introduce \textbf{VLM-R$^3$} (\textbf{V}isual \textbf{L}anguage \textbf{M}odel with \textbf{R}egion \textbf{R}ecognition and \textbf{R}easoning), a framework that equips an MLLM with the ability to (i) decide \emph{when} additional visual evidence is needed, (ii) determine \emph{where} to ground within the image, and (iii) seamlessly weave the relevant sub-image content back into an interleaved chain-of-thought. The core of our method is \textbf{Region-Conditioned Reinforcement Policy Optimization (R-GRPO)}, a training paradigm that rewards the model for selecting informative regions, formulating appropriate transformations (e.g.\ crop, zoom), and integrating the resulting visual context into subsequent reasoning steps. To bootstrap this policy, we compile a modest but carefully curated Visuo-Lingual Interleaved Rationale (VLIR) corpus that provides step-level supervision on region selection and textual justification. Extensive experiments on MathVista, ScienceQA, and other benchmarks show that VLM-R$^3$ sets a new state of the art in zero-shot and few-shot settings, with the largest gains appearing on questions demanding subtle spatial reasoning or fine-grained visual cue extraction.
SymDPO: Boosting In-Context Learning of Large Multimodal Models with Symbol Demonstration Direct Preference Optimization
Nov 17, 2024As language models continue to scale, Large Language Models (LLMs) have exhibited emerging capabilities in In-Context Learning (ICL), enabling them to solve language tasks by prefixing a few in-context demonstrations (ICDs) as context. Inspired by these advancements, researchers have extended these techniques to develop Large Multimodal Models (LMMs) with ICL capabilities. However, existing LMMs face a critical issue: they often fail to effectively leverage the visual context in multimodal demonstrations and instead simply follow textual patterns. This indicates that LMMs do not achieve effective alignment between multimodal demonstrations and model outputs. To address this problem, we propose Symbol Demonstration Direct Preference Optimization (SymDPO). Specifically, SymDPO aims to break the traditional paradigm of constructing multimodal demonstrations by using random symbols to replace text answers within instances. This forces the model to carefully understand the demonstration images and establish a relationship between the images and the symbols to answer questions correctly. We validate the effectiveness of this method on multiple benchmarks, demonstrating that with SymDPO, LMMs can more effectively understand the multimodal context within examples and utilize this knowledge to answer questions better.
MaVEn: An Effective Multi-granularity Hybrid Visual Encoding Framework for Multimodal Large Language Model
Aug 26, 2024This paper presents MaVEn, an innovative Multi-granularity Visual Encoding framework designed to enhance the capabilities of Multimodal Large Language Models (MLLMs) in multi-image reasoning. Current MLLMs primarily focus on single-image visual understanding, limiting their ability to interpret and integrate information across multiple images. MaVEn addresses this limitation by combining discrete visual symbol sequences, which abstract coarse-grained semantic concepts, with traditional continuous representation sequences that model fine-grained features. This dual approach bridges the semantic gap between visual and textual data, thereby improving the model's ability to process and interpret information from multiple images effectively. Additionally, we design a dynamic reduction mechanism by for long-sequence continuous features to enhance multi-image processing efficiency. Experimental results demonstrate that MaVEn significantly enhances MLLMs' understanding in complex multi-image scenarios, while also improving performance in single-image contexts.
MIBench: Evaluating Multimodal Large Language Models over Multiple Images
Jul 21, 2024



Built on the power of LLMs, numerous multimodal large language models (MLLMs) have recently achieved remarkable performance on various vision-language tasks across multiple benchmarks. However, most existing MLLMs and benchmarks primarily focus on single-image input scenarios, leaving the performance of MLLMs when handling realistic multiple images remain underexplored. Although a few benchmarks consider multiple images, their evaluation dimensions and samples are very limited. Therefore, in this paper, we propose a new benchmark MIBench, to comprehensively evaluate fine-grained abilities of MLLMs in multi-image scenarios. Specifically, MIBench categorizes the multi-image abilities into three scenarios: multi-image instruction (MII), multimodal knowledge-seeking (MKS) and multimodal in-context learning (MIC), and constructs 13 tasks with a total of 13K annotated samples. During data construction, for MII and MKS, we extract correct options from manual annotations and create challenging distractors to obtain multiple-choice questions. For MIC, to enable an in-depth evaluation, we set four sub-tasks and transform the original datasets into in-context learning formats. We evaluate several open-source MLLMs and close-source MLLMs on the proposed MIBench. The results reveal that although current models excel in single-image tasks, they exhibit significant shortcomings when faced with multi-image inputs, such as confused fine-grained perception, limited multi-image reasoning, and unstable in-context learning. The annotated data in MIBench is available at https://huggingface.co/datasets/StarBottle/MIBench.
Enhancing In-Context Learning via Implicit Demonstration Augmentation
Jun 27, 2024



The emergence of in-context learning (ICL) enables large pre-trained language models (PLMs) to make predictions for unseen inputs without updating parameters. Despite its potential, ICL's effectiveness heavily relies on the quality, quantity, and permutation of demonstrations, commonly leading to suboptimal and unstable performance. In this paper, we tackle this challenge for the first time from the perspective of demonstration augmentation. Specifically, we start with enriching representations of demonstrations by leveraging their deep feature distribution. We then theoretically reveal that when the number of augmented copies approaches infinity, the augmentation is approximately equal to a novel logit calibration mechanism integrated with specific statistical properties. This insight results in a simple yet highly efficient method that significantly improves the average and worst-case accuracy across diverse PLMs and tasks. Moreover, our method effectively reduces performance variance among varying demonstrations, permutations, and templates, and displays the capability to address imbalanced class distributions.
Hal-Eval: A Universal and Fine-grained Hallucination Evaluation Framework for Large Vision Language Models
Feb 24, 2024
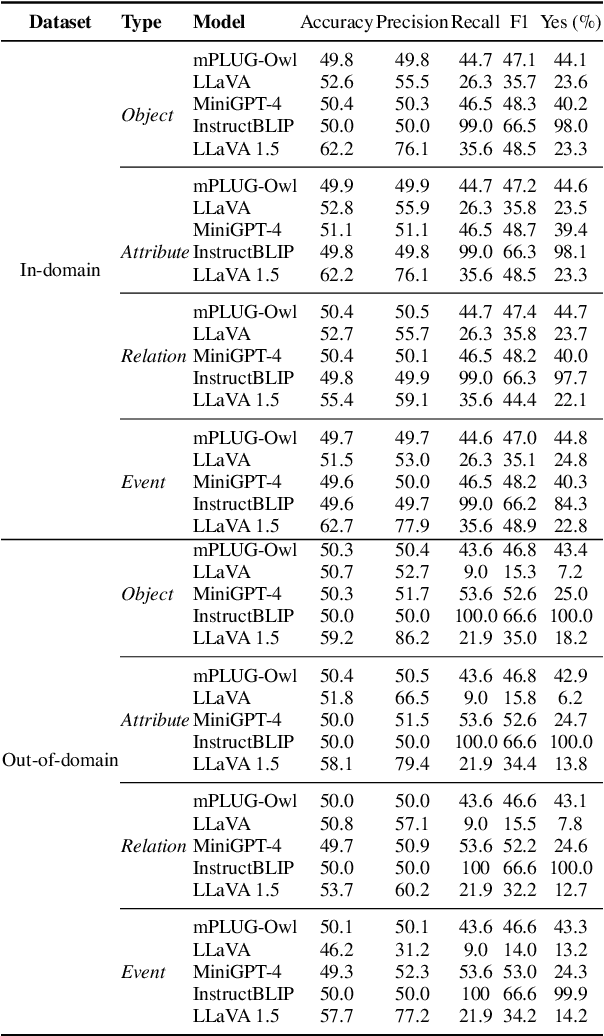
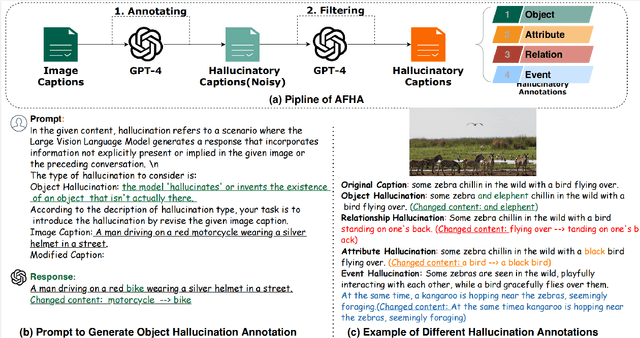
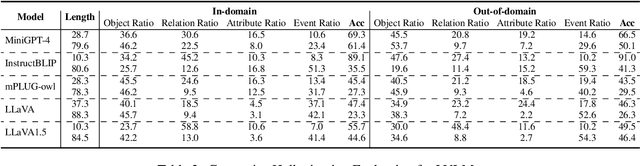
Large Vision Language Models exhibit remarkable capabilities but struggle with hallucinations inconsistencies between images and their descriptions. Previous hallucination evaluation studies on LVLMs have identified hallucinations in terms of objects, attributes, and relations but overlooked complex hallucinations that create an entire narrative around a fictional entity. In this paper, we introduce a refined taxonomy of hallucinations, featuring a new category: Event Hallucination. We then utilize advanced LLMs to generate and filter fine grained hallucinatory data consisting of various types of hallucinations, with a particular focus on event hallucinations, laying the groundwork for integrating discriminative and generative evaluation methods within our universal evaluation framework. The proposed benchmark distinctively assesses LVLMs ability to tackle a broad spectrum of hallucinations, making it a reliable and comprehensive tool for gauging LVLMs efficacy in handling hallucinations. We will release our code and data.
TiMix: Text-aware Image Mixing for Effective Vision-Language Pre-training
Dec 14, 2023
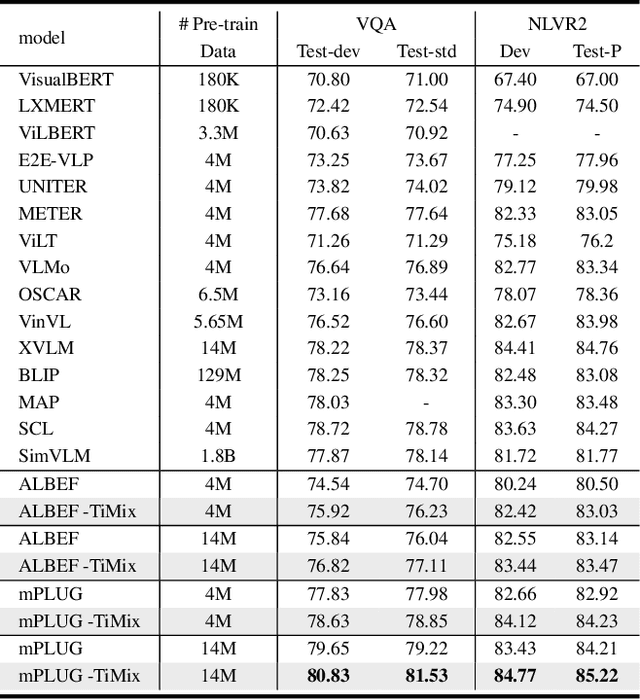

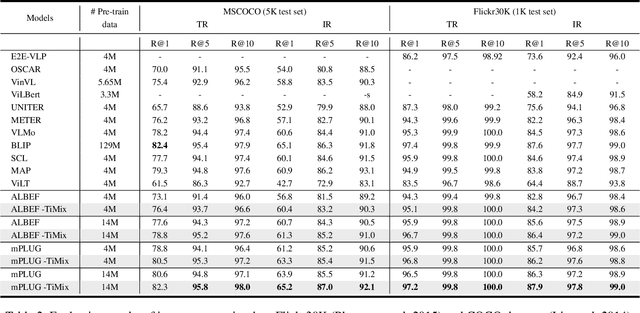
Self-supervised Multi-modal Contrastive Learning (SMCL) remarkably advances modern Vision-Language Pre-training (VLP) models by aligning visual and linguistic modalities. Due to noises in web-harvested text-image pairs, however, scaling up training data volume in SMCL presents considerable obstacles in terms of computational cost and data inefficiency. To improve data efficiency in VLP, we propose Text-aware Image Mixing (TiMix), which integrates mix-based data augmentation techniques into SMCL, yielding significant performance improvements without significantly increasing computational overhead. We provide a theoretical analysis of TiMixfrom a mutual information (MI) perspective, showing that mixed data samples for cross-modal contrastive learning implicitly serve as a regularizer for the contrastive loss. The experimental results demonstrate that TiMix exhibits a comparable performance on downstream tasks, even with a reduced amount of training data and shorter training time, when benchmarked against existing methods. This work empirically and theoretically demonstrates the potential of data mixing for data-efficient and computationally viable VLP, benefiting broader VLP model adoption in practical scenarios.