 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
SymDPO: Boosting In-Context Learning of Large Multimodal Models with Symbol Demonstration Direct Preference Optimization
Nov 17, 2024As language models continue to scale, Large Language Models (LLMs) have exhibited emerging capabilities in In-Context Learning (ICL), enabling them to solve language tasks by prefixing a few in-context demonstrations (ICDs) as context. Inspired by these advancements, researchers have extended these techniques to develop Large Multimodal Models (LMMs) with ICL capabilities. However, existing LMMs face a critical issue: they often fail to effectively leverage the visual context in multimodal demonstrations and instead simply follow textual patterns. This indicates that LMMs do not achieve effective alignment between multimodal demonstrations and model outputs. To address this problem, we propose Symbol Demonstration Direct Preference Optimization (SymDPO). Specifically, SymDPO aims to break the traditional paradigm of constructing multimodal demonstrations by using random symbols to replace text answers within instances. This forces the model to carefully understand the demonstration images and establish a relationship between the images and the symbols to answer questions correctly. We validate the effectiveness of this method on multiple benchmarks, demonstrating that with SymDPO, LMMs can more effectively understand the multimodal context within examples and utilize this knowledge to answer questions better.
MaVEn: An Effective Multi-granularity Hybrid Visual Encoding Framework for Multimodal Large Language Model
Aug 26, 2024This paper presents MaVEn, an innovative Multi-granularity Visual Encoding framework designed to enhance the capabilities of Multimodal Large Language Models (MLLMs) in multi-image reasoning. Current MLLMs primarily focus on single-image visual understanding, limiting their ability to interpret and integrate information across multiple images. MaVEn addresses this limitation by combining discrete visual symbol sequences, which abstract coarse-grained semantic concepts, with traditional continuous representation sequences that model fine-grained features. This dual approach bridges the semantic gap between visual and textual data, thereby improving the model's ability to process and interpret information from multiple images effectively. Additionally, we design a dynamic reduction mechanism by for long-sequence continuous features to enhance multi-image processing efficiency. Experimental results demonstrate that MaVEn significantly enhances MLLMs' understanding in complex multi-image scenarios, while also improving performance in single-image contexts.
Hal-Eval: A Universal and Fine-grained Hallucination Evaluation Framework for Large Vision Language Models
Feb 24, 2024
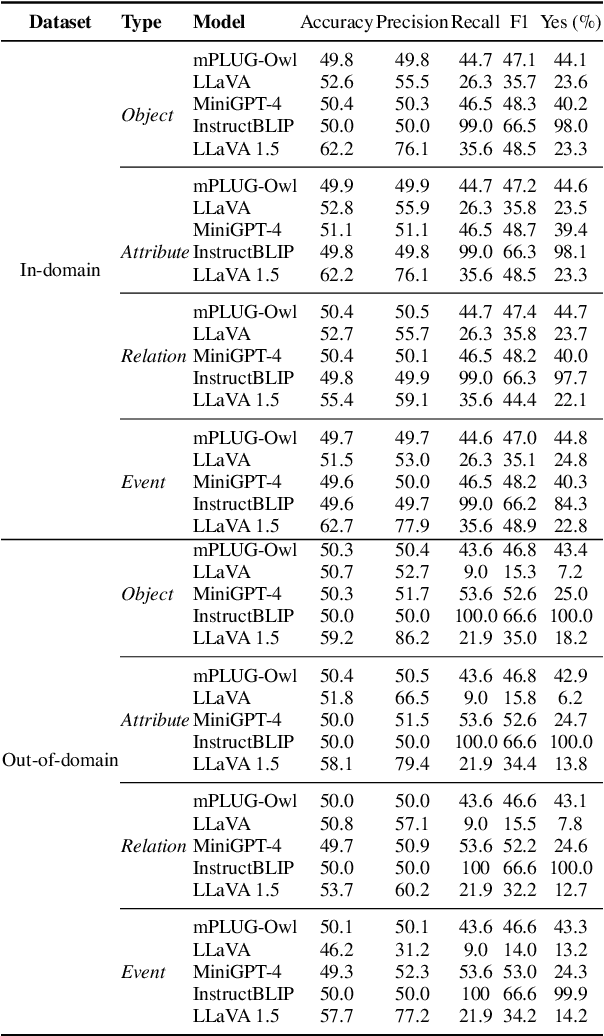
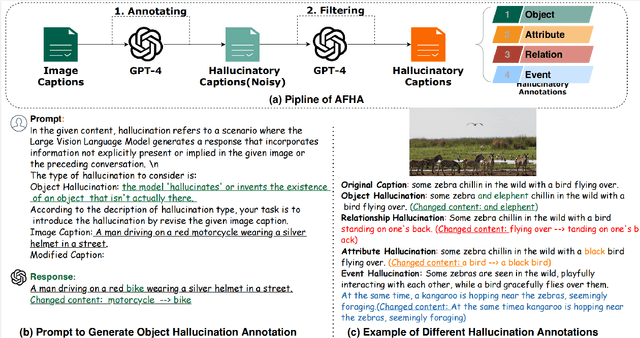
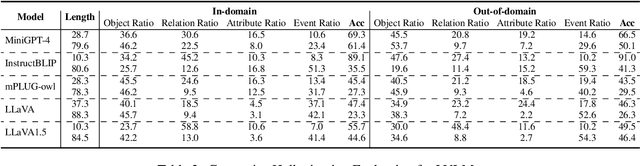
Large Vision Language Models exhibit remarkable capabilities but struggle with hallucinations inconsistencies between images and their descriptions. Previous hallucination evaluation studies on LVLMs have identified hallucinations in terms of objects, attributes, and relations but overlooked complex hallucinations that create an entire narrative around a fictional entity. In this paper, we introduce a refined taxonomy of hallucinations, featuring a new category: Event Hallucination. We then utilize advanced LLMs to generate and filter fine grained hallucinatory data consisting of various types of hallucinations, with a particular focus on event hallucinations, laying the groundwork for integrating discriminative and generative evaluation methods within our universal evaluation framework. The proposed benchmark distinctively assesses LVLMs ability to tackle a broad spectrum of hallucinations, making it a reliable and comprehensive tool for gauging LVLMs efficacy in handling hallucinations. We will release our code and data.
Hallucination Augmented Contrastive Learning for Multimodal Large Language Model
Dec 13, 2023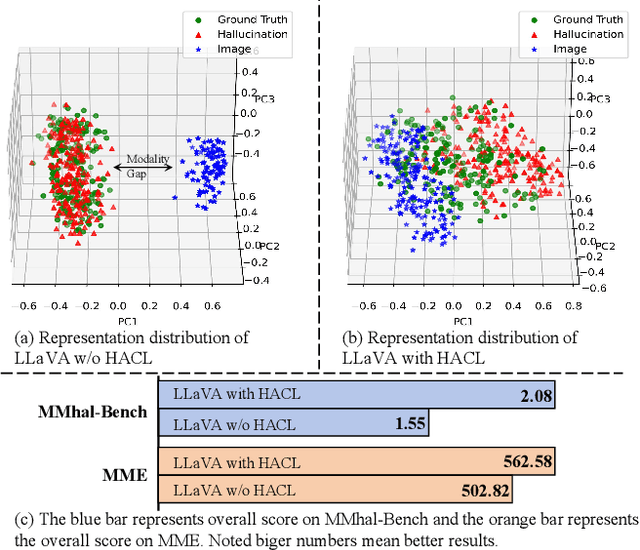
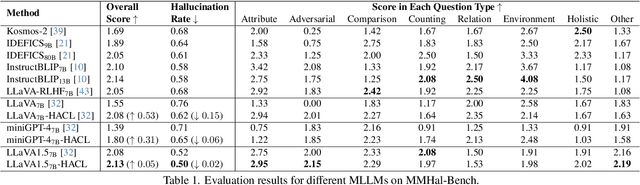
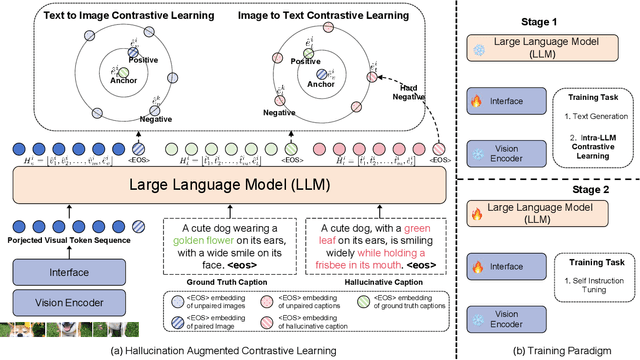
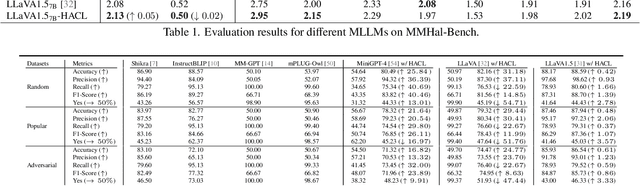
Multi-modal large language models (MLLMs) have been shown to efficiently integrate natural language with visual information to handle multi-modal tasks. However, MLLMs still face a fundamental limitation of hallucinations, where they tend to generate erroneous or fabricated information. In this paper, we address hallucinations in MLLMs from a novel perspective of representation learning. We first analyzed the representation distribution of textual and visual tokens in MLLM, revealing two important findings: 1) there is a significant gap between textual and visual representations, indicating unsatisfactory cross-modal representation alignment; 2) representations of texts that contain and do not contain hallucinations are entangled, making it challenging to distinguish them. These two observations inspire us with a simple yet effective method to mitigate hallucinations. Specifically, we introduce contrastive learning into MLLMs and use text with hallucination as hard negative examples, naturally bringing representations of non-hallucinative text and visual samples closer while pushing way representations of non-hallucinating and hallucinative text. We evaluate our method quantitatively and qualitatively, showing its effectiveness in reducing hallucination occurrences and improving performance across multiple benchmarks. On the MMhal-Bench benchmark, our method obtains a 34.66% /29.5% improvement over the baseline MiniGPT-4/LLaVA.