 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Spurious Correlations with Causal Logit Perturbation
May 21, 2025Deep learning has seen widespread success in various domains such as science, industry, and society. However, it is acknowledged that certain approaches suffer from non-robustness, relying on spurious correlations for predictions. Addressing these limitations is of paramount importance, necessitating the development of methods that can disentangle spurious correlations. {This study attempts to implement causal models via logit perturbations and introduces a novel Causal Logit Perturbation (CLP) framework to train classifiers with generated causal logit perturbations for individual samples, thereby mitigating the spurious associations between non-causal attributes (i.e., image backgrounds) and classes.} {Our framework employs a} perturbation network to generate sample-wise logit perturbations using a series of training characteristics of samples as inputs. The whole framework is optimized by an online meta-learning-based learning algorithm and leverages human causal knowledge by augmenting metadata in both counterfactual and factual manners. Empirical evaluations on four typical biased learning scenarios, including long-tail learning, noisy label learning, generalized long-tail learning, and subpopulation shift learning, demonstrate that CLP consistently achieves state-of-the-art performance. Moreover, visualization results support the effectiveness of the generated causal perturbations in redirecting model attention towards causal image attributes and dismantling spurious associations.
Enhancing In-Context Learning via Implicit Demonstration Augmentation
Jun 27, 2024



The emergence of in-context learning (ICL) enables large pre-trained language models (PLMs) to make predictions for unseen inputs without updating parameters. Despite its potential, ICL's effectiveness heavily relies on the quality, quantity, and permutation of demonstrations, commonly leading to suboptimal and unstable performance. In this paper, we tackle this challenge for the first time from the perspective of demonstration augmentation. Specifically, we start with enriching representations of demonstrations by leveraging their deep feature distribution. We then theoretically reveal that when the number of augmented copies approaches infinity, the augmentation is approximately equal to a novel logit calibration mechanism integrated with specific statistical properties. This insight results in a simple yet highly efficient method that significantly improves the average and worst-case accuracy across diverse PLMs and tasks. Moreover, our method effectively reduces performance variance among varying demonstrations, permutations, and templates, and displays the capability to address imbalanced class distributions.
Data Valuation by Leveraging Global and Local Statistical Information
May 23, 2024Data valuation has garnered increasing attention in recent years, given the critical role of high-quality data in various applications, particularly in machine learning tasks. There are diverse technical avenues to quantify the value of data within a corpus. While Shapley value-based methods are among the most widely used techniques in the literature due to their solid theoretical foundation, the accurate calculation of Shapley values is often intractable, leading to the proposal of numerous approximated calculation methods. Despite significant progress, nearly all existing methods overlook the utilization of distribution information of values within a data corpus. In this paper, we demonstrate that both global and local statistical information of value distributions hold significant potential for data valuation within the context of machine learning. Firstly, we explore the characteristics of both global and local value distributions across several simulated and real data corpora. Useful observations and clues are obtained. Secondly, we propose a new data valuation method that estimates Shapley values by incorporating the explored distribution characteristics into an existing method, AME. Thirdly, we present a new path to address the dynamic data valuation problem by formulating an optimization problem that integrates information of both global and local value distributions. Extensive experiments are conducted on Shapley value estimation, value-based data removal/adding, mislabeled data detection, and incremental/decremental data valuation. The results showcase the effectiveness and efficiency of our proposed methodologies, affirming the significant potential of global and local value distributions in data valuation.
Boosting Model Resilience via Implicit Adversarial Data Augmentation
Apr 25, 2024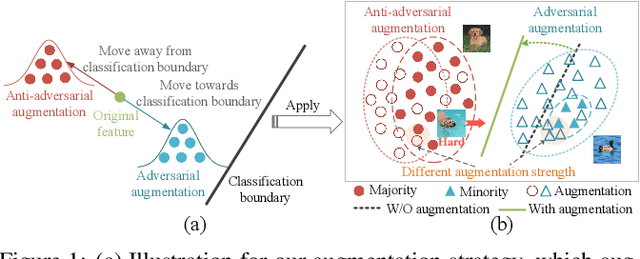
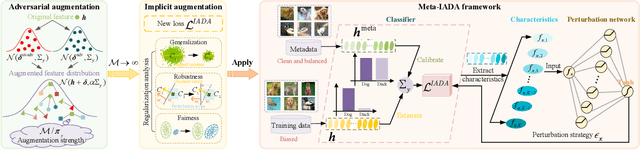
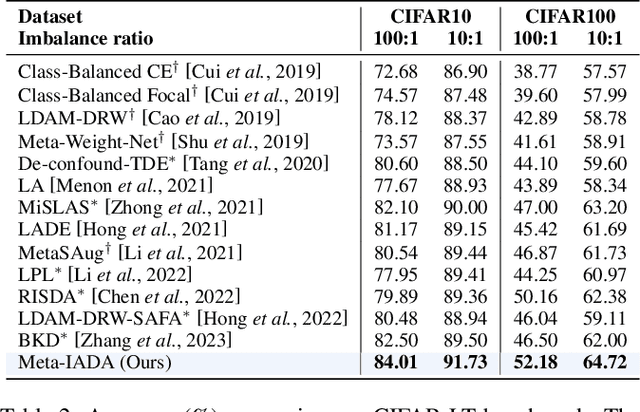
Data augmentation plays a pivotal role in enhancing and diversifying training data. Nonetheless, consistently improving model performance in varied learning scenarios, especially those with inherent data biases, remains challenging. To address this, we propose to augment the deep features of samples by incorporating their adversarial and anti-adversarial perturbation distributions, enabling adaptive adjustment in the learning difficulty tailored to each sample's specific characteristics. We then theoretically reveal that our augmentation process approximates the optimization of a surrogate loss function as the number of augmented copies increases indefinitely. This insight leads us to develop a meta-learning-based framework for optimizing classifiers with this novel loss, introducing the effects of augmentation while bypassing the explicit augmentation process. We conduct extensive experiments across four common biased learning scenarios: long-tail learning, generalized long-tail learning, noisy label learning, and subpopulation shift learning. The empirical results demonstrate that our method consistently achieves state-of-the-art performance, highlighting its broad adaptability.
Implicit Counterfactual Data Augmentation for Deep Neural Networks
Apr 26, 2023


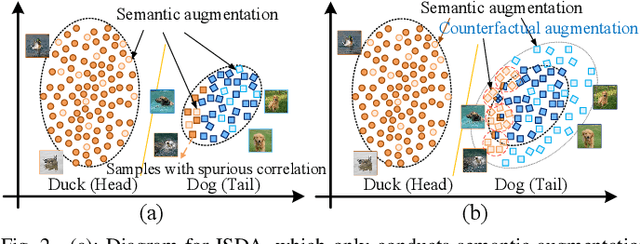
Machine-learning models are prone to capturing the spurious correlations between non-causal attributes and classes, with counterfactual data augmentation being a promising direction for breaking these spurious associations. However, explicitly generating counterfactual data is challenging, with the training efficiency declining. Therefore, this study proposes an implicit counterfactual data augmentation (ICDA) method to remove spurious correlations and make stable predictions. Specifically, first, a novel sample-wise augmentation strategy is developed that generates semantically and counterfactually meaningful deep features with distinct augmentation strength for each sample. Second, we derive an easy-to-compute surrogate loss on the augmented feature set when the number of augmented samples becomes infinite. Third, two concrete schemes are proposed, including direct quantification and meta-learning, to derive the key parameters for the robust loss. In addition, ICDA is explained from a regularization aspect, with extensive experiments indicating that our method consistently improves the generalization performance of popular depth networks on multiple typical learning scenarios that require out-of-distribution generalization.
Combining Adversaries with Anti-adversaries in Training
Apr 25, 2023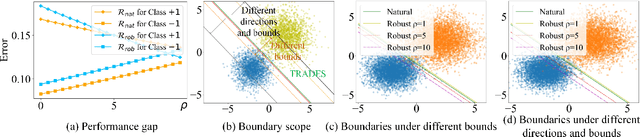
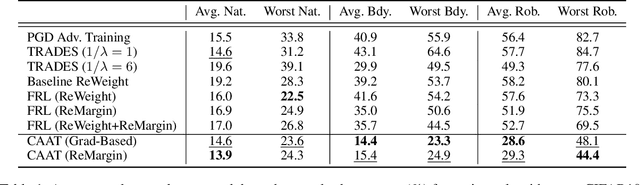
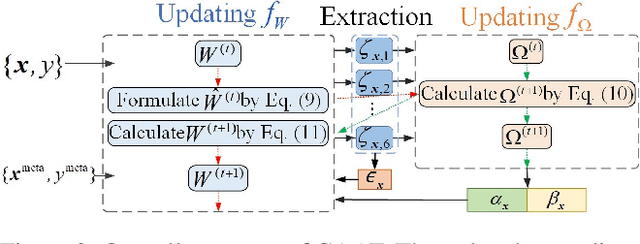
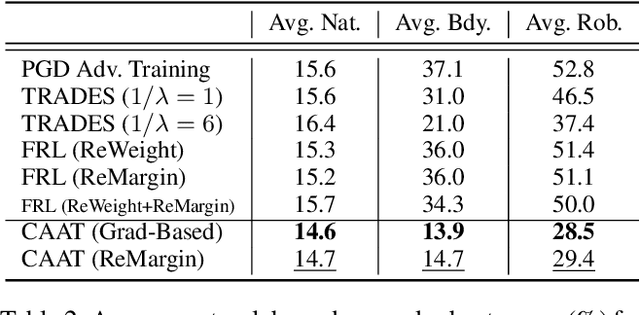
Adversarial training is an effective learning technique to improve the robustness of deep neural networks. In this study, the influence of adversarial training on deep learning models in terms of fairness, robustness, and generalization is theoretically investigated under more general perturbation scope that different samples can have different perturbation directions (the adversarial and anti-adversarial directions) and varied perturbation bounds. Our theoretical explorations suggest that the combination of adversaries and anti-adversaries (samples with anti-adversarial perturbations) in training can be more effective in achieving better fairness between classes and a better tradeoff between robustness and generalization in some typical learning scenarios (e.g., noisy label learning and imbalance learning) compared with standard adversarial training. On the basis of our theoretical findings, a more general learning objective that combines adversaries and anti-adversaries with varied bounds on each training sample is presented. Meta learning is utilized to optimize the combination weights. Experiments on benchmark datasets under different learning scenarios verify our theoretical findings and the effectiveness of the proposed methodology.
* 8 pages, 5 figures
Understanding Difficulty-based Sample Weighting with a Universal Difficulty Measure
Jan 12, 2023Sample weighting is widely used in deep learning. A large number of weighting methods essentially utilize the learning difficulty of training samples to calculate their weights. In this study, this scheme is called difficulty-based weighting. Two important issues arise when explaining this scheme. First, a unified difficulty measure that can be theoretically guaranteed for training samples does not exist. The learning difficulties of the samples are determined by multiple factors including noise level, imbalance degree, margin, and uncertainty. Nevertheless, existing measures only consider a single factor or in part, but not in their entirety. Second, a comprehensive theoretical explanation is lacking with respect to demonstrating why difficulty-based weighting schemes are effective in deep learning. In this study, we theoretically prove that the generalization error of a sample can be used as a universal difficulty measure. Furthermore, we provide formal theoretical justifications on the role of difficulty-based weighting for deep learning, consequently revealing its positive influences on both the optimization dynamics and generalization performance of deep models, which is instructive to existing weighting schemes.
Which Samples Should be Learned First: Easy or Hard?
Oct 14, 2021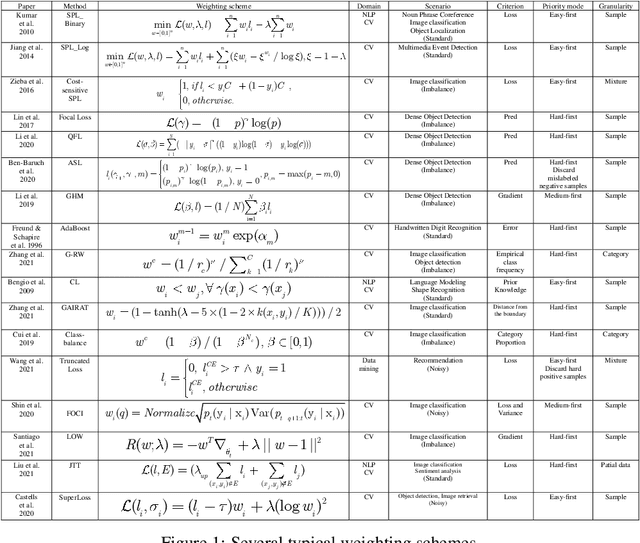
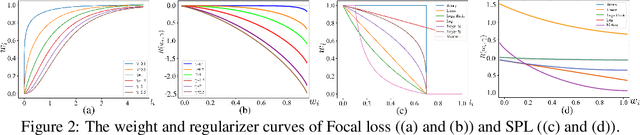
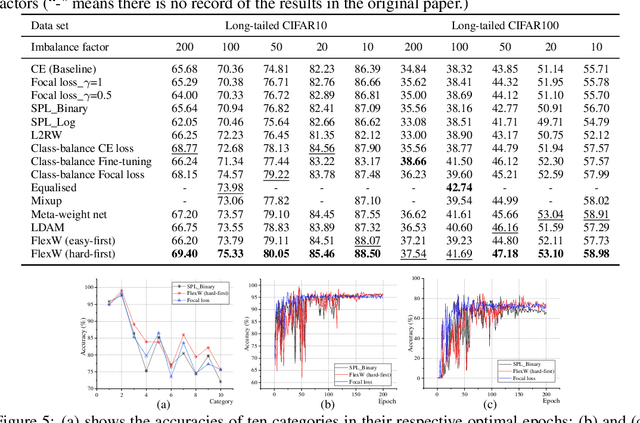
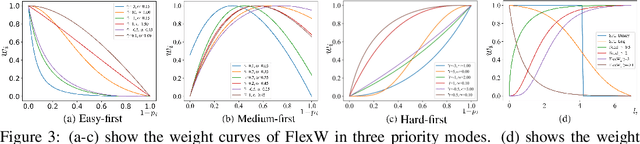
An effective weighting scheme for training samples is essential for learning tasks. Numerous weighting schemes have been proposed. Some schemes take the easy-first mode on samples, whereas some others take the hard-first mode. Naturally, an interesting yet realistic question is raised. Which samples should be learned first given a new learning task, easy or hard? To answer this question, three aspects of research are carried out. First, a high-level unified weighted loss is proposed, providing a more comprehensive view for existing schemes. Theoretical analysis is subsequently conducted and preliminary conclusions are obtained. Second, a flexible weighting scheme is proposed to overcome the defects of existing schemes. The three modes, namely, easy/medium/hard-first, can be flexibly switched in the proposed scheme. Third, a wide range of experiments are conducted to further compare the weighting schemes in different modes. On the basis of these works, reasonable answers are obtained. Factors including prior knowledge and data characteristics determine which samples should be learned first in a learning task.
Antonym-Synonym Classification Based on New Sub-space Embeddings
Jun 13, 2019
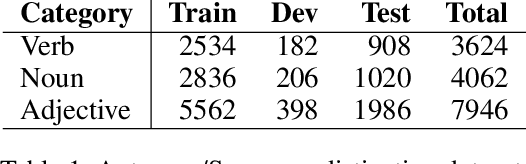
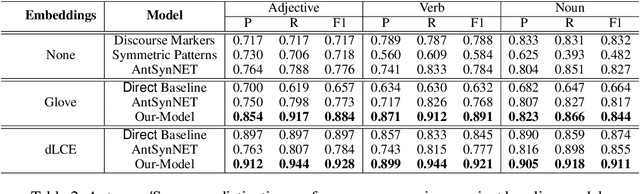
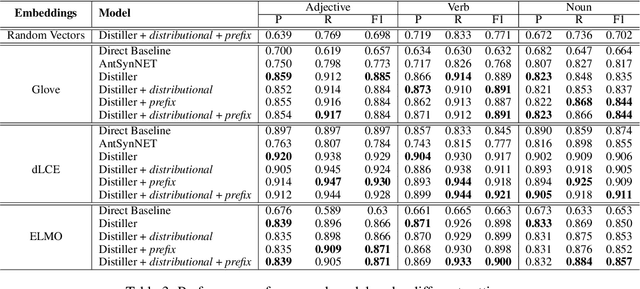
Distinguishing antonyms from synonyms is a key challenge for many NLP applications focused on the lexical-semantic relation extraction. Existing solutions relying on large-scale corpora yield low performance because of huge contextual overlap of antonym and synonym pairs. We propose a novel approach entirely based on pre-trained embeddings. We hypothesize that the pre-trained embeddings comprehend a blend of lexical-semantic information and we may distill the task-specific information using Distiller, a model proposed in this paper. Later, a classifier is trained based on features constructed from the distilled sub-spaces along with some word level features to distinguish antonyms from synonyms. Experimental results show that the proposed model outperforms existing research on antonym synonym distinction in both speed and performance.