 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntonym-Synonym Classification Based on New Sub-space Embeddings
Paper and Code
Jun 13, 2019
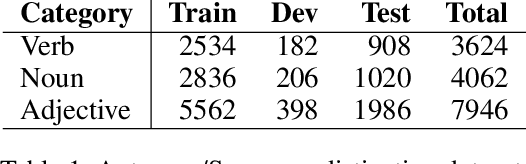
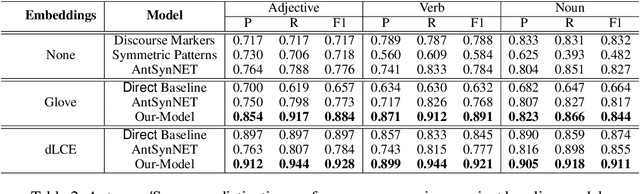
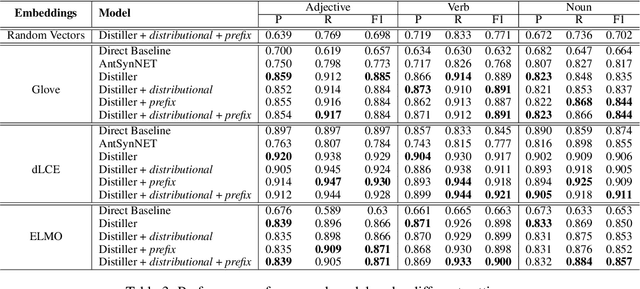
Distinguishing antonyms from synonyms is a key challenge for many NLP applications focused on the lexical-semantic relation extraction. Existing solutions relying on large-scale corpora yield low performance because of huge contextual overlap of antonym and synonym pairs. We propose a novel approach entirely based on pre-trained embeddings. We hypothesize that the pre-trained embeddings comprehend a blend of lexical-semantic information and we may distill the task-specific information using Distiller, a model proposed in this paper. Later, a classifier is trained based on features constructed from the distilled sub-spaces along with some word level features to distinguish antonyms from synonyms. Experimental results show that the proposed model outperforms existing research on antonym synonym distinction in both speed and performance.