 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSent2Span: Span Detection for PICO Extraction in the Biomedical Text without Span Annotations
Sep 06, 2021

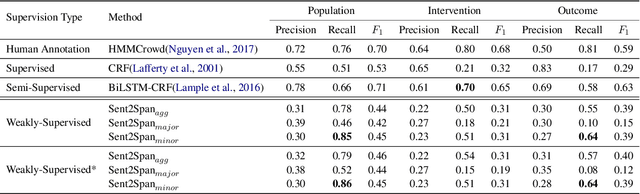

The rapid growth in published clinical trials makes it difficult to maintain up-to-date systematic reviews, which requires finding all relevant trials. This leads to policy and practice decisions based on out-of-date, incomplete, and biased subsets of available clinical evidence. Extracting and then normalising Population, Intervention, Comparator, and Outcome (PICO) information from clinical trial articles may be an effective way to automatically assign trials to systematic reviews and avoid searching and screening - the two most time-consuming systematic review processes. We propose and test a novel approach to PICO span detection. The major difference between our proposed method and previous approaches comes from detecting spans without needing annotated span data and using only crowdsourced sentence-level annotations. Experiments on two datasets show that PICO span detection results achieve much higher results for recall when compared to fully supervised methods with PICO sentence detection at least as good as human annotations. By removing the reliance on expert annotations for span detection, this work could be used in human-machine pipeline for turning low-quality crowdsourced, and sentence-level PICO annotations into structured information that can be used to quickly assign trials to relevant systematic reviews.
Fine-Grained Named Entity Typing over Distantly Supervised Data via Refinement in Hyperbolic Space
Jan 27, 2021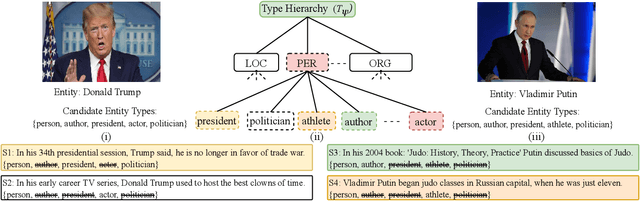



Fine-Grained Named Entity Typing (FG-NET) aims at classifying the entity mentions into a wide range of entity types (usually hundreds) depending upon the context. While distant supervision is the most common way to acquire supervised training data, it brings in label noise, as it assigns type labels to the entity mentions irrespective of mentions' context. In attempts to deal with the label noise, leading research on the FG-NET assumes that the fine-grained entity typing data possesses a euclidean nature, which restraints the ability of the existing models in combating the label noise. Given the fact that the fine-grained type hierarchy exhibits a hierarchal structure, it makes hyperbolic space a natural choice to model the FG-NET data. In this research, we propose FGNET-HR, a novel framework that benefits from the hyperbolic geometry in combination with the graph structures to perform entity typing in a performance-enhanced fashion. FGNET-HR initially uses LSTM networks to encode the mention in relation with its context, later it forms a graph to distill/refine the mention's encodings in the hyperbolic space. Finally, the refined mention encoding is used for entity typing. Experimentation using different benchmark datasets shows that FGNET-HR improves the performance on FG-NET by up to 3.5% in terms of strict accuracy.
Fine-Grained Named Entity Typing over Distantly Supervised Data Based on Refined Representations
Apr 07, 2020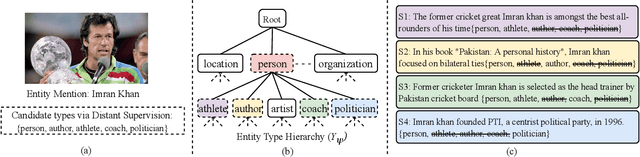



Fine-Grained Named Entity Typing (FG-NET) is a key component in Natural Language Processing (NLP). It aims at classifying an entity mention into a wide range of entity types. Due to a large number of entity types, distant supervision is used to collect training data for this task, which noisily assigns type labels to entity mentions irrespective of the context. In order to alleviate the noisy labels, existing approaches on FGNET analyze the entity mentions entirely independent of each other and assign type labels solely based on mention sentence-specific context. This is inadequate for highly overlapping and noisy type labels as it hinders information passing across sentence boundaries. For this, we propose an edge-weighted attentive graph convolution network that refines the noisy mention representations by attending over corpus-level contextual clues prior to the end classification. Experimental evaluation shows that the proposed model outperforms the existing research by a relative score of upto 10.2% and 8.3% for macro f1 and micro f1 respectively.
Monotonic Cardinality Estimation of Similarity Selection: A Deep Learning Approach
Mar 18, 2020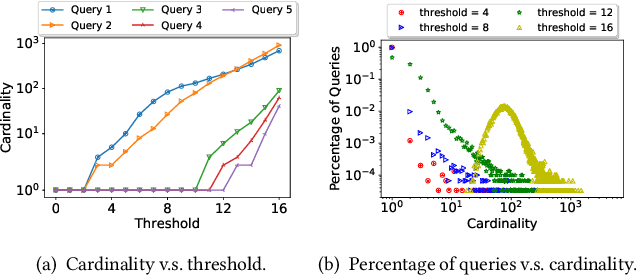
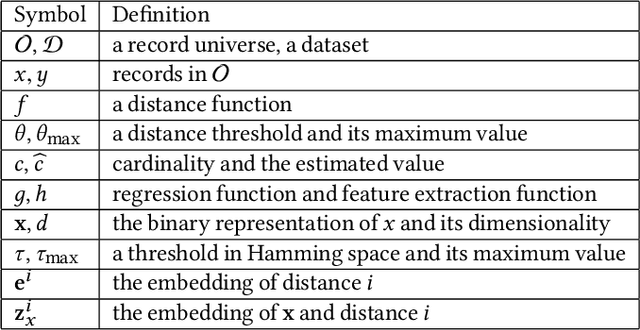
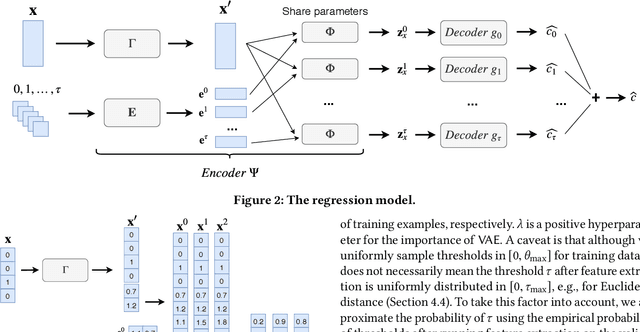
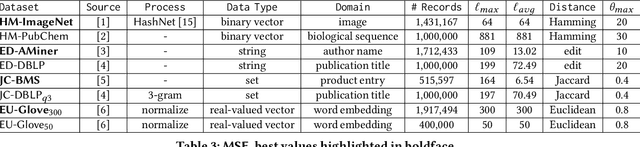
Due to the outstanding capability of capturing underlying data distributions, deep learning techniques have been recently utilized for a series of traditional database problems. In this paper, we investigate the possibilities of utilizing deep learning for cardinality estimation of similarity selection. Answering this problem accurately and efficiently is essential to many data management applications, especially for query optimization. Moreover, in some applications the estimated cardinality is supposed to be consistent and interpretable. Hence a monotonic estimation w.r.t. the query threshold is preferred. We propose a novel and generic method that can be applied to any data type and distance function. Our method consists of a feature extraction model and a regression model. The feature extraction model transforms original data and threshold to a Hamming space, in which a deep learning-based regression model is utilized to exploit the incremental property of cardinality w.r.t. the threshold for both accuracy and monotonicity. We develop a training strategy tailored to our model as well as techniques for fast estimation. We also discuss how to handle updates. We demonstrate the accuracy and the efficiency of our method through experiments, and show how it improves the performance of a query optimizer.
HAMNER: Headword Amplified Multi-span Distantly Supervised Method for Domain Specific Named Entity Recognition
Dec 03, 2019
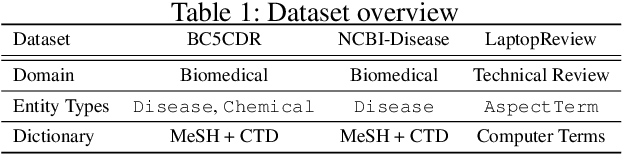

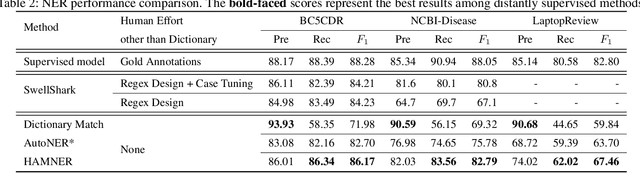
To tackle Named Entity Recognition (NER) tasks, supervised methods need to obtain sufficient cleanly annotated data, which is labor and time consuming. On the contrary, distantly supervised methods acquire automatically annotated data using dictionaries to alleviate this requirement. Unfortunately, dictionaries hinder the effectiveness of distantly supervised methods for NER due to its limited coverage, especially in specific domains. In this paper, we aim at the limitations of the dictionary usage and mention boundary detection. We generalize the distant supervision by extending the dictionary with headword based non-exact matching. We apply a function to better weight the matched entity mentions. We propose a span-level model, which classifies all the possible spans then infers the selected spans with a proposed dynamic programming algorithm. Experiments on all three benchmark datasets demonstrate that our method outperforms previous state-of-the-art distantly supervised methods.
Antonym-Synonym Classification Based on New Sub-space Embeddings
Jun 13, 2019
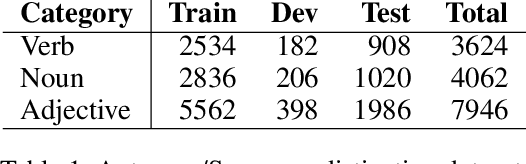
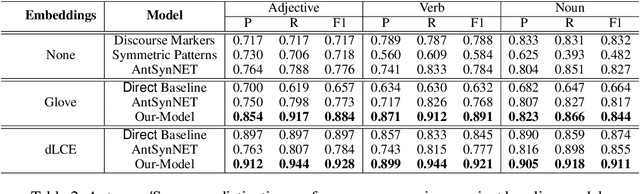
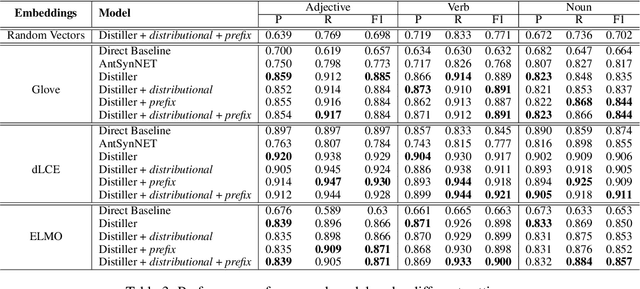
Distinguishing antonyms from synonyms is a key challenge for many NLP applications focused on the lexical-semantic relation extraction. Existing solutions relying on large-scale corpora yield low performance because of huge contextual overlap of antonym and synonym pairs. We propose a novel approach entirely based on pre-trained embeddings. We hypothesize that the pre-trained embeddings comprehend a blend of lexical-semantic information and we may distill the task-specific information using Distiller, a model proposed in this paper. Later, a classifier is trained based on features constructed from the distilled sub-spaces along with some word level features to distinguish antonyms from synonyms. Experimental results show that the proposed model outperforms existing research on antonym synonym distinction in both speed and performance.
How to best use Syntax in Semantic Role Labelling
Jun 01, 2019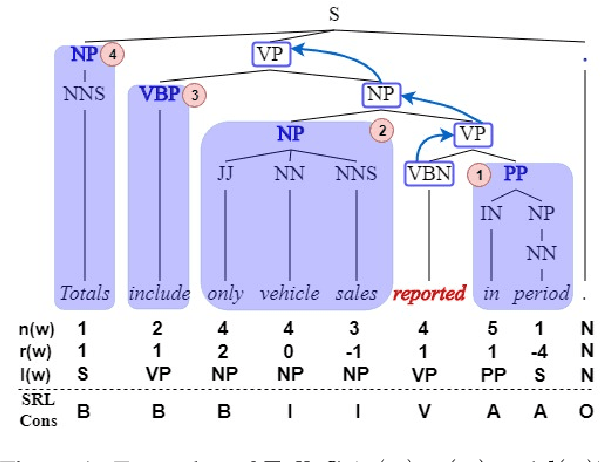
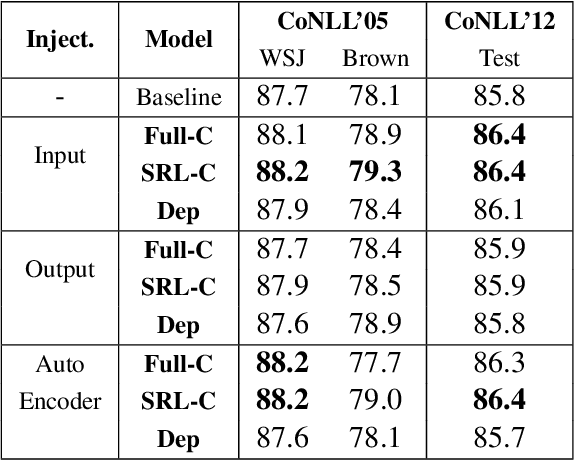


There are many different ways in which external information might be used in an NLP task. This paper investigates how external syntactic information can be used most effectively in the Semantic Role Labeling (SRL) task. We evaluate three different ways of encoding syntactic parses and three different ways of injecting them into a state-of-the-art neural ELMo-based SRL sequence labelling model. We show that using a constituency representation as input features improves performance the most, achieving a new state-of-the-art for non-ensemble SRL models on the in-domain CoNLL'05 and CoNLL'12 benchmarks.