 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSent2Span: Span Detection for PICO Extraction in the Biomedical Text without Span Annotations
Sep 06, 2021

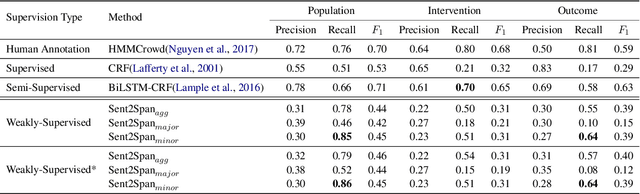

The rapid growth in published clinical trials makes it difficult to maintain up-to-date systematic reviews, which requires finding all relevant trials. This leads to policy and practice decisions based on out-of-date, incomplete, and biased subsets of available clinical evidence. Extracting and then normalising Population, Intervention, Comparator, and Outcome (PICO) information from clinical trial articles may be an effective way to automatically assign trials to systematic reviews and avoid searching and screening - the two most time-consuming systematic review processes. We propose and test a novel approach to PICO span detection. The major difference between our proposed method and previous approaches comes from detecting spans without needing annotated span data and using only crowdsourced sentence-level annotations. Experiments on two datasets show that PICO span detection results achieve much higher results for recall when compared to fully supervised methods with PICO sentence detection at least as good as human annotations. By removing the reliance on expert annotations for span detection, this work could be used in human-machine pipeline for turning low-quality crowdsourced, and sentence-level PICO annotations into structured information that can be used to quickly assign trials to relevant systematic reviews.