 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCKGAN: Training Generative Adversarial Networks Using Characteristic Kernel Integral Probability Metrics
Apr 08, 2025



In this paper, we propose CKGAN, a novel generative adversarial network (GAN) variant based on an integral probability metrics framework with characteristic kernel (CKIPM). CKIPM, as a distance between two probability distributions, is designed to optimize the lowerbound of the maximum mean discrepancy (MMD) in a reproducing kernel Hilbert space, and thus can be used to train GANs. CKGAN mitigates the notorious problem of mode collapse by mapping the generated images back to random noise. To save the effort of selecting the kernel function manually, we propose a soft selection method to automatically learn a characteristic kernel function. The experimental evaluation conducted on a set of synthetic and real image benchmarks (MNIST, CelebA, etc.) demonstrates that CKGAN generally outperforms other MMD-based GANs. The results also show that at the cost of moderately more training time, the automatically selected kernel function delivers very close performance to the best of manually fine-tuned one on real image benchmarks and is able to improve the performances of other MMD-based GANs.
ZeroED: Hybrid Zero-shot Error Detection through Large Language Model Reasoning
Apr 06, 2025
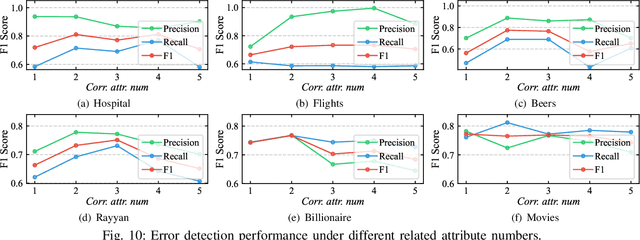


Error detection (ED) in tabular data is crucial yet challenging due to diverse error types and the need for contextual understanding. Traditional ED methods often rely heavily on manual criteria and labels, making them labor-intensive. Large language models (LLM) can minimize human effort but struggle with errors requiring a comprehensive understanding of data context. In this paper, we propose ZeroED, a novel hybrid zero-shot error detection framework, which combines LLM reasoning ability with the manual label-based ED pipeline. ZeroED operates in four steps, i.e., feature representation, error labeling, training data construction, and detector training. Initially, to enhance error distinction, ZeroED generates rich data representations using error reason-aware binary features, pre-trained embeddings, and statistical features. Then, ZeroED employs LLM to label errors holistically through in-context learning, guided by a two-step reasoning process for detailed error detection guidelines. To reduce token costs, LLMs are applied only to representative data selected via clustering-based sampling. High-quality training data is constructed through in-cluster label propagation and LLM augmentation with verification. Finally, a classifier is trained to detect all errors. Extensive experiments on seven public datasets demonstrate that, ZeroED substantially outperforms state-of-the-art methods by a maximum 30% improvement in F1 score and up to 90% token cost reduction.
BClean: A Bayesian Data Cleaning System
Nov 11, 2023There is a considerable body of work on data cleaning which employs various principles to rectify erroneous data and transform a dirty dataset into a cleaner one. One of prevalent approaches is probabilistic methods, including Bayesian methods. However, existing probabilistic methods often assume a simplistic distribution (e.g., Gaussian distribution), which is frequently underfitted in practice, or they necessitate experts to provide a complex prior distribution (e.g., via a programming language). This requirement is both labor-intensive and costly, rendering these methods less suitable for real-world applications. In this paper, we propose BClean, a Bayesian Cleaning system that features automatic Bayesian network construction and user interaction. We recast the data cleaning problem as a Bayesian inference that fully exploits the relationships between attributes in the observed dataset and any prior information provided by users. To this end, we present an automatic Bayesian network construction method that extends a structure learning-based functional dependency discovery method with similarity functions to capture the relationships between attributes. Furthermore, our system allows users to modify the generated Bayesian network in order to specify prior information or correct inaccuracies identified by the automatic generation process. We also design an effective scoring model (called the compensative scoring model) necessary for the Bayesian inference. To enhance the efficiency of data cleaning, we propose several approximation strategies for the Bayesian inference, including graph partitioning, domain pruning, and pre-detection. By evaluating on both real-world and synthetic datasets, we demonstrate that BClean is capable of achieving an F-measure of up to 0.9 in data cleaning, outperforming existing Bayesian methods by 2% and other data cleaning methods by 15%.
Consistent and Flexible Selectivity Estimation for High-dimensional Data
May 20, 2020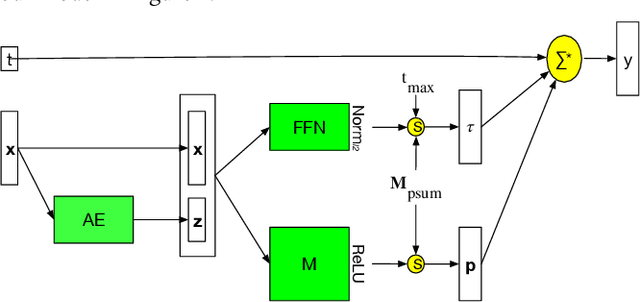
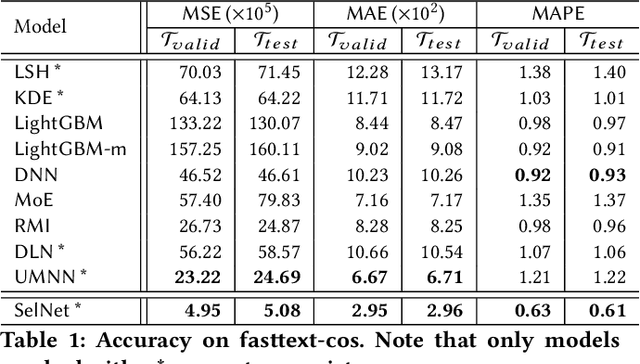
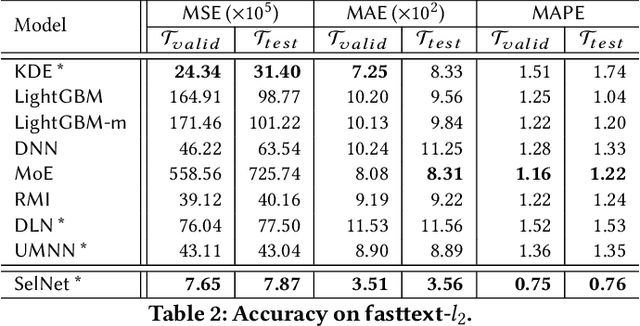
Selectivity estimation aims at estimating the number of database objects that satisfy a selection criterion. Answering this problem accurately and efficiently is essential to applications, such as density estimation, outlier detection, query optimization, and data integration. The estimation problem is especially challenging for large-scale high-dimensional data due to the curse of dimensionality, the need to make the estimator consistent (i.e., the selectivity is non-decreasing w.r.t. the threshold), and the large variance of selectivity across different queries. We propose a new deep learning-based model that learns a query dependent piece-wise linear function as the estimator. We design a novel model architecture so that the model is flexible to fit any selection criterion. To improve the accuracy for large datasets, we propose to divide the dataset into multiple disjoint partitions and build a local model on each of them. We perform experiments on real datasets and show that the proposed model guarantees the consistency and significantly outperforms state-of-the-art models in terms of both accuracy and efficiency.
Monotonic Cardinality Estimation of Similarity Selection: A Deep Learning Approach
Mar 18, 2020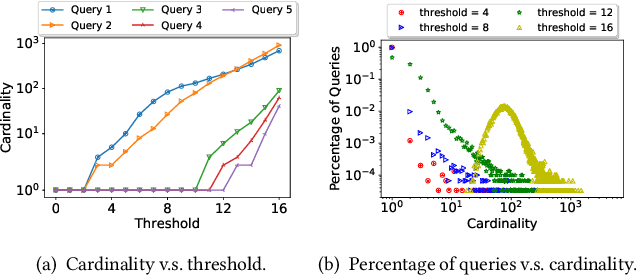
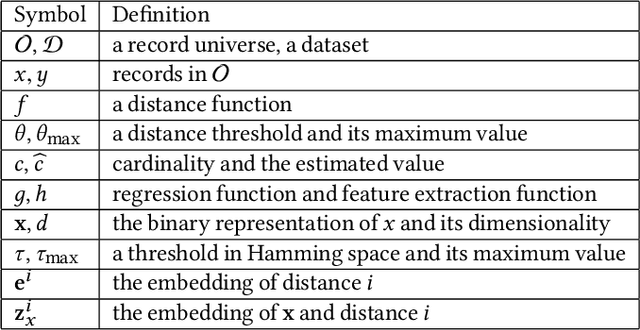
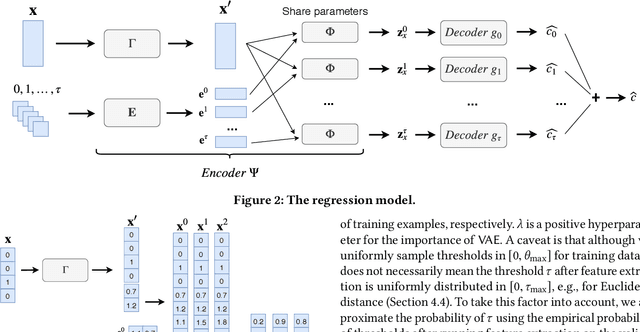
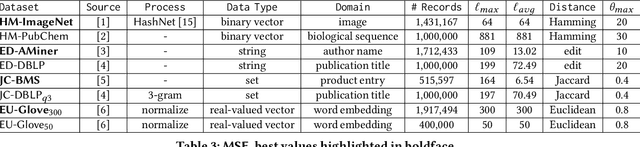
Due to the outstanding capability of capturing underlying data distributions, deep learning techniques have been recently utilized for a series of traditional database problems. In this paper, we investigate the possibilities of utilizing deep learning for cardinality estimation of similarity selection. Answering this problem accurately and efficiently is essential to many data management applications, especially for query optimization. Moreover, in some applications the estimated cardinality is supposed to be consistent and interpretable. Hence a monotonic estimation w.r.t. the query threshold is preferred. We propose a novel and generic method that can be applied to any data type and distance function. Our method consists of a feature extraction model and a regression model. The feature extraction model transforms original data and threshold to a Hamming space, in which a deep learning-based regression model is utilized to exploit the incremental property of cardinality w.r.t. the threshold for both accuracy and monotonicity. We develop a training strategy tailored to our model as well as techniques for fast estimation. We also discuss how to handle updates. We demonstrate the accuracy and the efficiency of our method through experiments, and show how it improves the performance of a query optimizer.