 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaLead: A Comprehensive Human-Curated Leaderboard Dataset for Transparent Reporting of Machine Learning Experiments
Jan 30, 2026Leaderboards are crucial in the machine learning (ML) domain for benchmarking and tracking progress. However, creating leaderboards traditionally demands significant manual effort. In recent years, efforts have been made to automate leaderboard generation, but existing datasets for this purpose are limited by capturing only the best results from each paper and limited metadata. We present MetaLead, a fully human-annotated ML Leaderboard dataset that captures all experimental results for result transparency and contains extra metadata, such as the result experimental type: baseline, proposed method, or variation of proposed method for experiment-type guided comparisons, and explicitly separates train and test dataset for cross-domain assessment. This enriched structure makes MetaLead a powerful resource for more transparent and nuanced evaluations across ML research.
On the Role of Context for Discourse Relation Classification in Scientific Writing
Oct 30, 2025With the increasing use of generative Artificial Intelligence (AI) methods to support science workflows, we are interested in the use of discourse-level information to find supporting evidence for AI generated scientific claims. A first step towards this objective is to examine the task of inferring discourse structure in scientific writing. In this work, we present a preliminary investigation of pretrained language model (PLM) and Large Language Model (LLM) approaches for Discourse Relation Classification (DRC), focusing on scientific publications, an under-studied genre for this task. We examine how context can help with the DRC task, with our experiments showing that context, as defined by discourse structure, is generally helpful. We also present an analysis of which scientific discourse relation types might benefit most from context.
A Position Paper on the Automatic Generation of Machine Learning Leaderboards
May 23, 2025An important task in machine learning (ML) research is comparing prior work, which is often performed via ML leaderboards: a tabular overview of experiments with comparable conditions (e.g., same task, dataset, and metric). However, the growing volume of literature creates challenges in creating and maintaining these leaderboards. To ease this burden, researchers have developed methods to extract leaderboard entries from research papers for automated leaderboard curation. Yet, prior work varies in problem framing, complicating comparisons and limiting real-world applicability. In this position paper, we present the first overview of Automatic Leaderboard Generation (ALG) research, identifying fundamental differences in assumptions, scope, and output formats. We propose an ALG unified conceptual framework to standardise how the ALG task is defined. We offer ALG benchmarking guidelines, including recommendations for datasets and metrics that promote fair, reproducible evaluation. Lastly, we outline challenges and new directions for ALG, such as, advocating for broader coverage by including all reported results and richer metadata.
Direct Advantage Regression: Aligning LLMs with Online AI Reward
Apr 19, 2025Online AI Feedback (OAIF) presents a promising alternative to Reinforcement Learning from Human Feedback (RLHF) by utilizing online AI preference in aligning language models (LLMs). However, the straightforward replacement of humans with AI deprives LLMs from learning more fine-grained AI supervision beyond binary signals. In this paper, we propose Direct Advantage Regression (DAR), a simple alignment algorithm using online AI reward to optimize policy improvement through weighted supervised fine-tuning. As an RL-free approach, DAR maintains theoretical consistency with online RLHF pipelines while significantly reducing implementation complexity and improving learning efficiency. Our empirical results underscore that AI reward is a better form of AI supervision consistently achieving higher human-AI agreement as opposed to AI preference. Additionally, evaluations using GPT-4-Turbo and MT-bench show that DAR outperforms both OAIF and online RLHF baselines.
What Causes the Failure of Explicit to Implicit Discourse Relation Recognition?
Apr 01, 2024We consider an unanswered question in the discourse processing community: why do relation classifiers trained on explicit examples (with connectives removed) perform poorly in real implicit scenarios? Prior work claimed this is due to linguistic dissimilarity between explicit and implicit examples but provided no empirical evidence. In this study, we show that one cause for such failure is a label shift after connectives are eliminated. Specifically, we find that the discourse relations expressed by some explicit instances will change when connectives disappear. Unlike previous work manually analyzing a few examples, we present empirical evidence at the corpus level to prove the existence of such shift. Then, we analyze why label shift occurs by considering factors such as the syntactic role played by connectives, ambiguity of connectives, and more. Finally, we investigate two strategies to mitigate the label shift: filtering out noisy data and joint learning with connectives. Experiments on PDTB 2.0, PDTB 3.0, and the GUM dataset demonstrate that classifiers trained with our strategies outperform strong baselines.
Neural Rule-Execution Tracking Machine For Transformer-Based Text Generation
Jul 27, 2021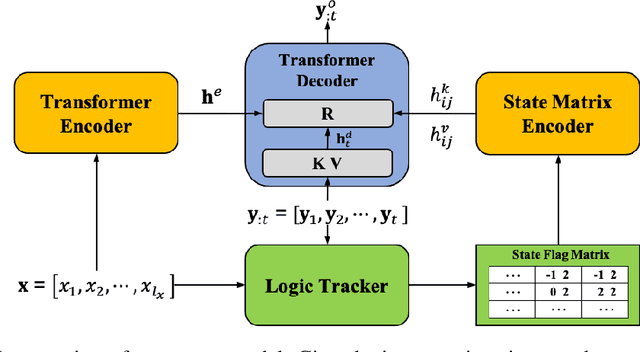

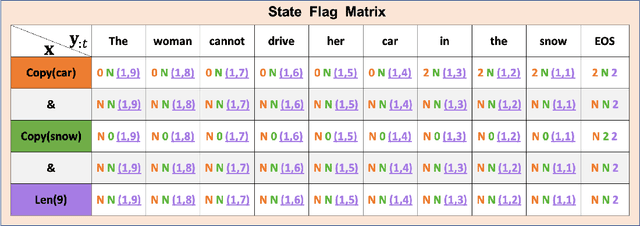
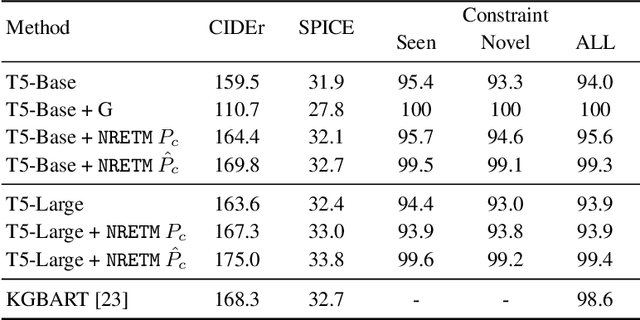
Sequence-to-Sequence (S2S) neural text generation models, especially the pre-trained ones (e.g., BART and T5), have exhibited compelling performance on various natural language generation tasks. However, the black-box nature of these models limits their application in tasks where specific rules (e.g., controllable constraints, prior knowledge) need to be executed. Previous works either design specific model structure (e.g., Copy Mechanism corresponding to the rule "the generated output should include certain words in the source input") or implement specialized inference algorithm (e.g., Constrained Beam Search) to execute particular rules through the text generation. These methods require careful design case-by-case and are difficult to support multiple rules concurrently. In this paper, we propose a novel module named Neural Rule-Execution Tracking Machine that can be equipped into various transformer-based generators to leverage multiple rules simultaneously to guide the neural generation model for superior generation performance in a unified and scalable way. Extensive experimental results on several benchmarks verify the effectiveness of our proposed model in both controllable and general text generation.
ECOL-R: Encouraging Copying in Novel Object Captioning with Reinforcement Learning
Jan 25, 2021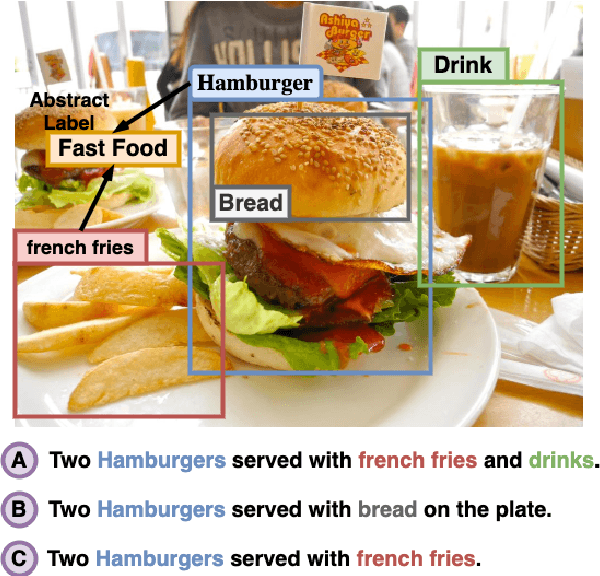
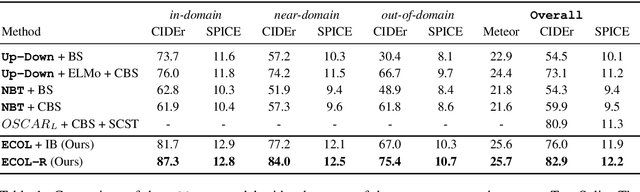

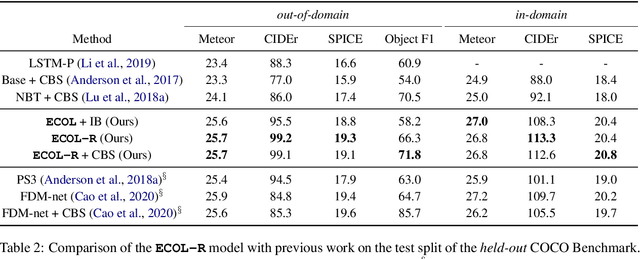
Novel Object Captioning is a zero-shot Image Captioning task requiring describing objects not seen in the training captions, but for which information is available from external object detectors. The key challenge is to select and describe all salient detected novel objects in the input images. In this paper, we focus on this challenge and propose the ECOL-R model (Encouraging Copying of Object Labels with Reinforced Learning), a copy-augmented transformer model that is encouraged to accurately describe the novel object labels. This is achieved via a specialised reward function in the SCST reinforcement learning framework (Rennie et al., 2017) that encourages novel object mentions while maintaining the caption quality. We further restrict the SCST training to the images where detected objects are mentioned in reference captions to train the ECOL-R model. We additionally improve our copy mechanism via Abstract Labels, which transfer knowledge from known to novel object types, and a Morphological Selector, which determines the appropriate inflected forms of novel object labels. The resulting model sets new state-of-the-art on the nocaps (Agrawal et al., 2019) and held-out COCO (Hendricks et al., 2016) benchmarks.
Towards Generating Stylized Image Captions via Adversarial Training
Aug 08, 2019
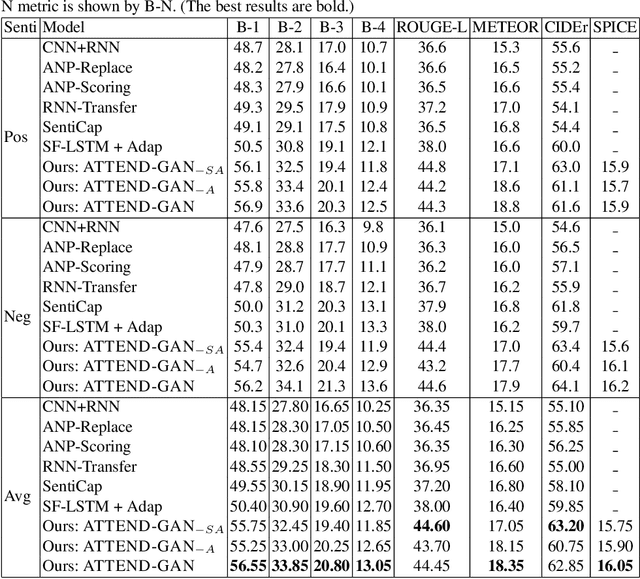
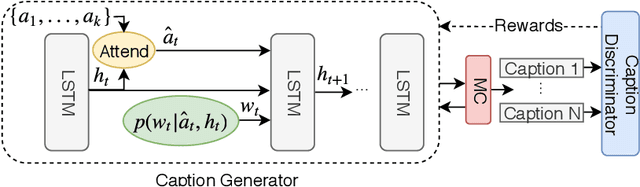
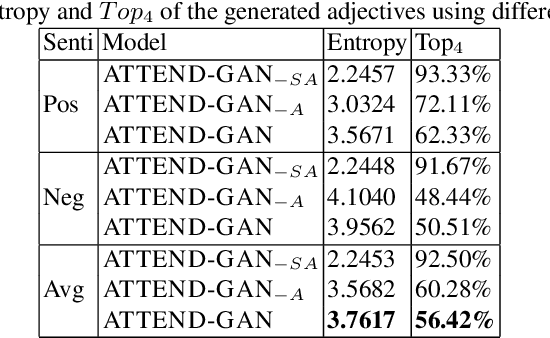
While most image captioning aims to generate objective descriptions of images, the last few years have seen work on generating visually grounded image captions which have a specific style (e.g., incorporating positive or negative sentiment). However, because the stylistic component is typically the last part of training, current models usually pay more attention to the style at the expense of accurate content description. In addition, there is a lack of variability in terms of the stylistic aspects. To address these issues, we propose an image captioning model called ATTEND-GAN which has two core components: first, an attention-based caption generator to strongly correlate different parts of an image with different parts of a caption; and second, an adversarial training mechanism to assist the caption generator to add diverse stylistic components to the generated captions. Because of these components, ATTEND-GAN can generate correlated captions as well as more human-like variability of stylistic patterns. Our system outperforms the state-of-the-art as well as a collection of our baseline models. A linguistic analysis of the generated captions demonstrates that captions generated using ATTEND-GAN have a wider range of stylistic adjectives and adjective-noun pairs.
Image Captioning using Facial Expression and Attention
Aug 08, 2019
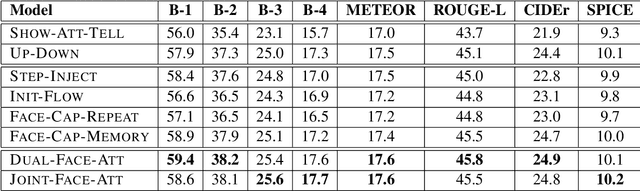

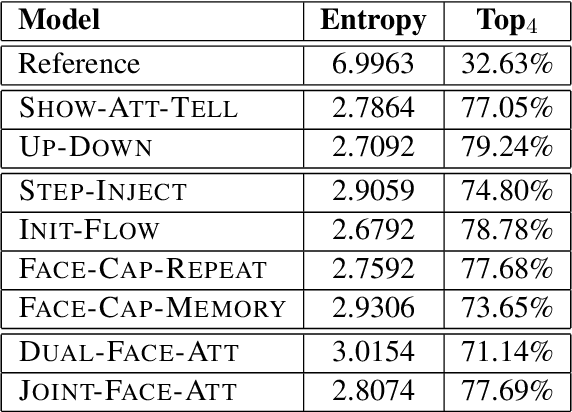
Benefiting from advances in machine vision and natural language processing techniques, current image captioning systems are able to generate detailed visual descriptions. For the most part, these descriptions represent an objective characterisation of the image, although some models do incorporate subjective aspects related to the observer's view of the image, such as sentiment; current models, however, usually do not consider the emotional content of images during the caption generation process. This paper addresses this issue by proposing novel image captioning models which use facial expression features to generate image captions. The models generate image captions using long short-term memory networks applying facial features in addition to other visual features at different time steps. We compare a comprehensive collection of image captioning models with and without facial features using all standard evaluation metrics. The evaluation metrics indicate that applying facial features with an attention mechanism achieves the best performance, showing more expressive and more correlated image captions, on an image caption dataset extracted from the standard Flickr 30K dataset, consisting of around 11K images containing faces. An analysis of the generated captions finds that, perhaps unexpectedly, the improvement in caption quality appears to come not from the addition of adjectives linked to emotional aspects of the images, but from more variety in the actions described in the captions.
How to best use Syntax in Semantic Role Labelling
Jun 01, 2019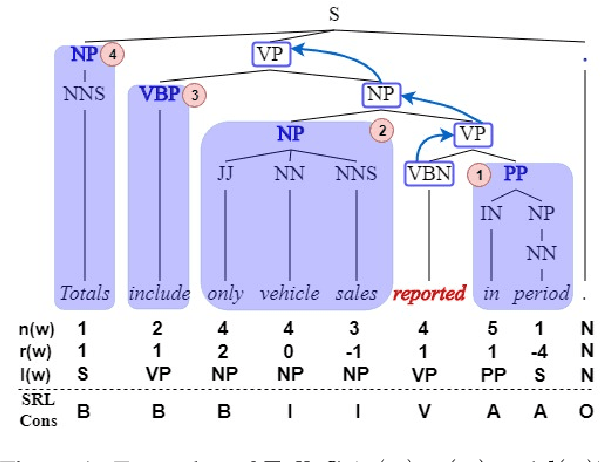
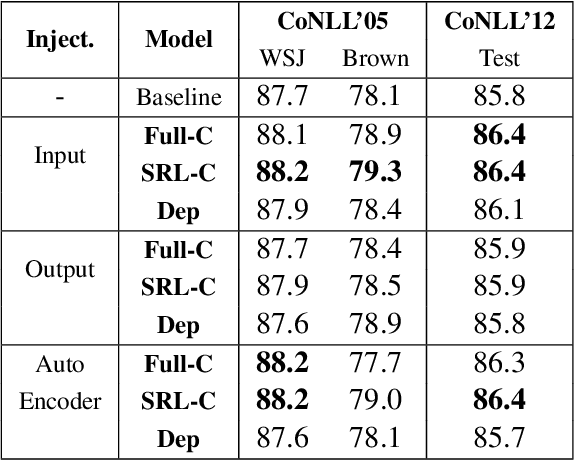


There are many different ways in which external information might be used in an NLP task. This paper investigates how external syntactic information can be used most effectively in the Semantic Role Labeling (SRL) task. We evaluate three different ways of encoding syntactic parses and three different ways of injecting them into a state-of-the-art neural ELMo-based SRL sequence labelling model. We show that using a constituency representation as input features improves performance the most, achieving a new state-of-the-art for non-ensemble SRL models on the in-domain CoNLL'05 and CoNLL'12 benchmarks.