 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePick-Object-Attack: Type-Specific Adversarial Attack for Object Detection
Jun 05, 2020
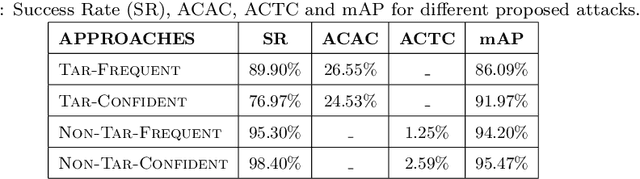
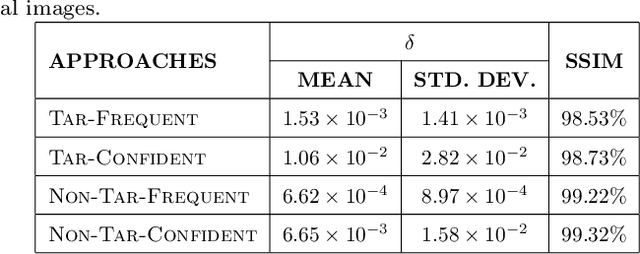
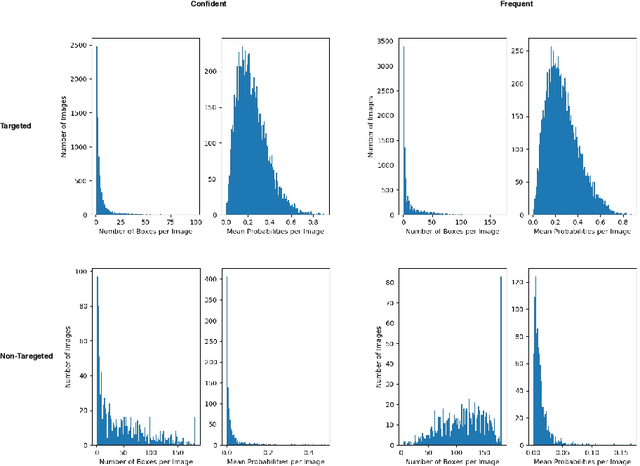
Many recent studies have shown that deep neural models are vulnerable to adversarial samples: images with imperceptible perturbations, for example, can fool image classifiers. In this paper, we generate adversarial examples for object detection, which entails detecting bounding boxes around multiple objects present in the image and classifying them at the same time, making it a harder task than against image classification. We specifically aim to attack the widely used Faster R-CNN by changing the predicted label for a particular object in an image: where prior work has targeted one specific object (a stop sign), we generalise to arbitrary objects, with the key challenge being the need to change the labels of all bounding boxes for all instances of that object type. To do so, we propose a novel method, named Pick-Object-Attack. Pick-Object-Attack successfully adds perturbations only to bounding boxes for the targeted object, preserving the labels of other detected objects in the image. In terms of perceptibility, the perturbations induced by the method are very small. Furthermore, for the first time, we examine the effect of adversarial attacks on object detection in terms of a downstream task, image captioning; we show that where a method that can modify all object types leads to very obvious changes in captions, the changes from our constrained attack are much less apparent.
Towards Generating Stylized Image Captions via Adversarial Training
Aug 08, 2019
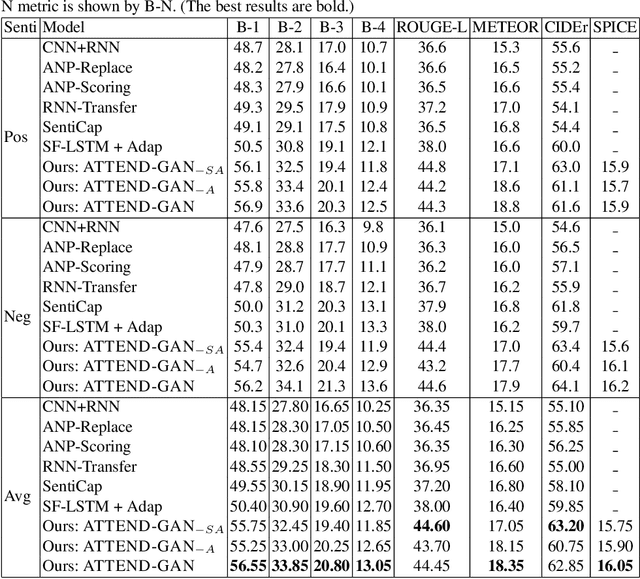
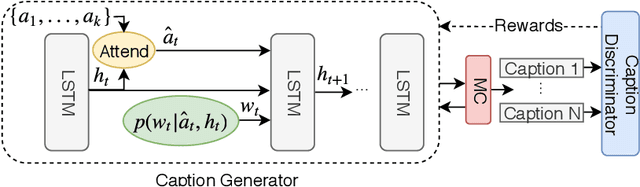
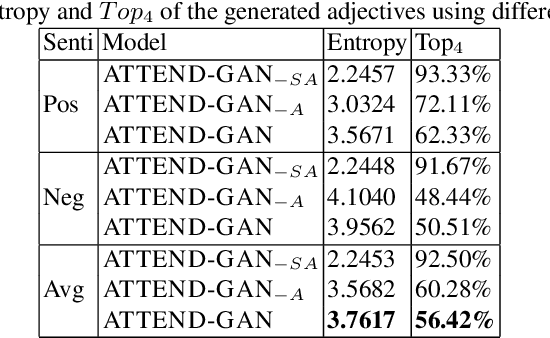
While most image captioning aims to generate objective descriptions of images, the last few years have seen work on generating visually grounded image captions which have a specific style (e.g., incorporating positive or negative sentiment). However, because the stylistic component is typically the last part of training, current models usually pay more attention to the style at the expense of accurate content description. In addition, there is a lack of variability in terms of the stylistic aspects. To address these issues, we propose an image captioning model called ATTEND-GAN which has two core components: first, an attention-based caption generator to strongly correlate different parts of an image with different parts of a caption; and second, an adversarial training mechanism to assist the caption generator to add diverse stylistic components to the generated captions. Because of these components, ATTEND-GAN can generate correlated captions as well as more human-like variability of stylistic patterns. Our system outperforms the state-of-the-art as well as a collection of our baseline models. A linguistic analysis of the generated captions demonstrates that captions generated using ATTEND-GAN have a wider range of stylistic adjectives and adjective-noun pairs.
Image Captioning using Facial Expression and Attention
Aug 08, 2019
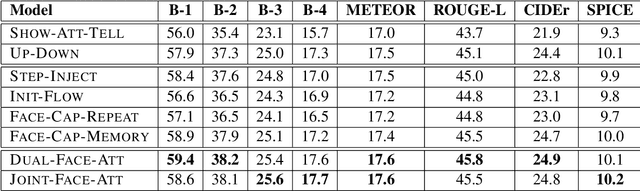

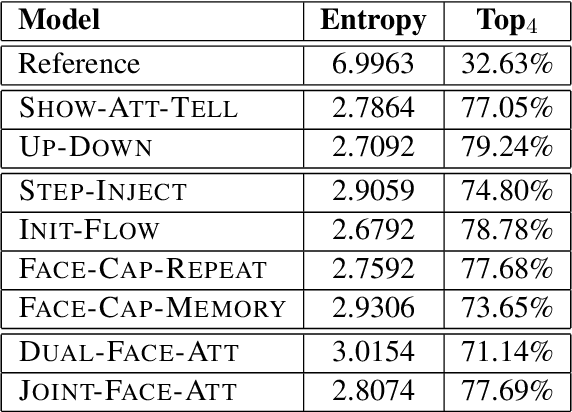
Benefiting from advances in machine vision and natural language processing techniques, current image captioning systems are able to generate detailed visual descriptions. For the most part, these descriptions represent an objective characterisation of the image, although some models do incorporate subjective aspects related to the observer's view of the image, such as sentiment; current models, however, usually do not consider the emotional content of images during the caption generation process. This paper addresses this issue by proposing novel image captioning models which use facial expression features to generate image captions. The models generate image captions using long short-term memory networks applying facial features in addition to other visual features at different time steps. We compare a comprehensive collection of image captioning models with and without facial features using all standard evaluation metrics. The evaluation metrics indicate that applying facial features with an attention mechanism achieves the best performance, showing more expressive and more correlated image captions, on an image caption dataset extracted from the standard Flickr 30K dataset, consisting of around 11K images containing faces. An analysis of the generated captions finds that, perhaps unexpectedly, the improvement in caption quality appears to come not from the addition of adjectives linked to emotional aspects of the images, but from more variety in the actions described in the captions.
ShEMO -- A Large-Scale Validated Database for Persian Speech Emotion Detection
Jun 11, 2019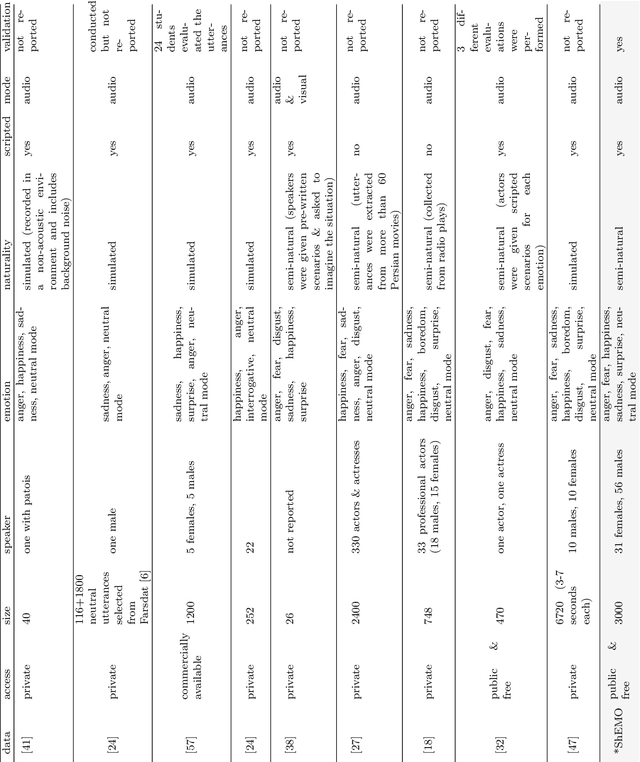
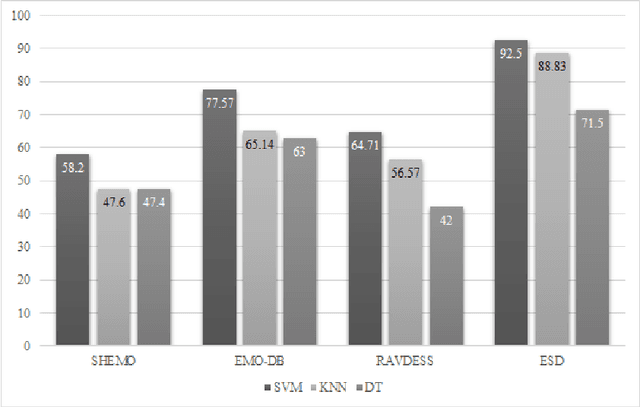

This paper introduces a large-scale, validated database for Persian called Sharif Emotional Speech Database (ShEMO). The database includes 3000 semi-natural utterances, equivalent to 3 hours and 25 minutes of speech data extracted from online radio plays. The ShEMO covers speech samples of 87 native-Persian speakers for five basic emotions including anger, fear, happiness, sadness and surprise, as well as neutral state. Twelve annotators label the underlying emotional state of utterances and majority voting is used to decide on the final labels. According to the kappa measure, the inter-annotator agreement is 64% which is interpreted as "substantial agreement". We also present benchmark results based on common classification methods in speech emotion detection task. According to the experiments, support vector machine achieves the best results for both gender-independent (58.2%) and gender-dependent models (female=59.4%, male=57.6%). The ShEMO is available for academic purposes free of charge to provide a baseline for further research on Persian emotional speech.
Senti-Attend: Image Captioning using Sentiment and Attention
Nov 24, 2018
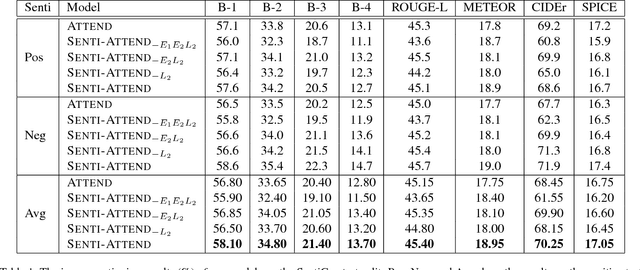
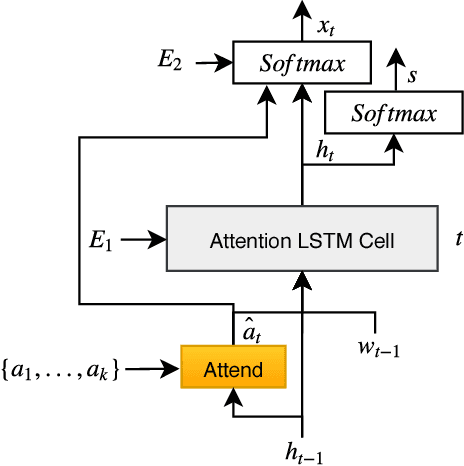
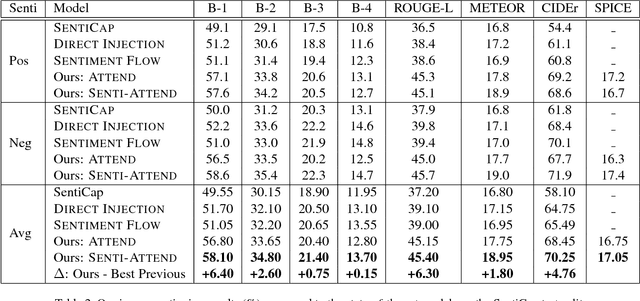
There has been much recent work on image captioning models that describe the factual aspects of an image. Recently, some models have incorporated non-factual aspects into the captions, such as sentiment or style. However, such models typically have difficulty in balancing the semantic aspects of the image and the non-factual dimensions of the caption; in addition, it can be observed that humans may focus on different aspects of an image depending on the chosen sentiment or style of the caption. To address this, we design an attention-based model to better add sentiment to image captions. The model embeds and learns sentiment with respect to image-caption data, and uses both high-level and word-level sentiment information during the learning process. The model outperforms the state-of-the-art work in image captioning with sentiment using standard evaluation metrics. An analysis of generated captions also shows that our model does this by a better selection of the sentiment-bearing adjectives and adjective-noun pairs.
Deep Learning for Domain Adaption: Engagement Recognition
Aug 07, 2018
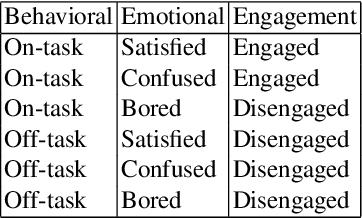

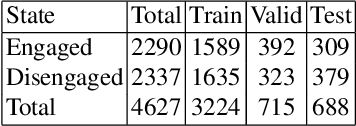
Engagement is a key indicator of the quality of learning experience, and one that plays a major role in developing intelligent educational interfaces. Any such interface requires the ability to recognise the level of engagement in order to respond appropriately; however, there is very little existing data to learn from, and new data is expensive and difficult to acquire. This paper presents a deep learning model to improve engagement recognition from face images captured `in the wild' that overcomes the data sparsity challenge by pre-training on readily available basic facial expression data, before training on specialised engagement data. In the first of two steps, a state-of-the-art facial expression recognition model is trained to provide a rich face representation using deep learning. In the second step, we use the model's weights to initialize our deep learning based model to recognize engagement; we term this the Transfer model. We train the model on our new engagement recognition (ER) dataset with 4627 engaged and disengaged samples. We find that our Transfer architecture outperforms standard deep learning architectures that we apply for the first time to engagement recognition, as well as approaches using HOG features and SVMs. The model achieves a classification accuracy of 72.38%, which is 6.1% better than the best baseline model on the test set of the ER dataset. Using the F1 measure and the area under the ROC curve, our Transfer model achieves 73.90% and 73.74%, exceeding the best baseline model by 3.49% and 5.33% respectively.
Face-Cap: Image Captioning using Facial Expression Analysis
Jul 06, 2018
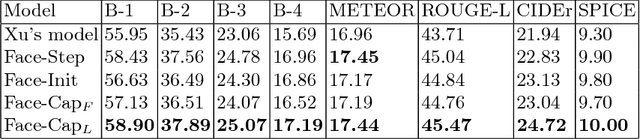
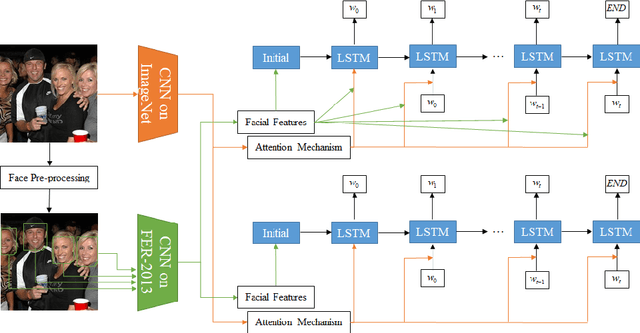
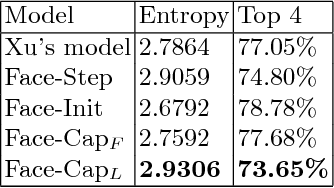
Image captioning is the process of generating a natural language description of an image. Most current image captioning models, however, do not take into account the emotional aspect of an image, which is very relevant to activities and interpersonal relationships represented therein. Towards developing a model that can produce human-like captions incorporating these, we use facial expression features extracted from images including human faces, with the aim of improving the descriptive ability of the model. In this work, we present two variants of our Face-Cap model, which embed facial expression features in different ways, to generate image captions. Using all standard evaluation metrics, our Face-Cap models outperform a state-of-the-art baseline model for generating image captions when applied to an image caption dataset extracted from the standard Flickr 30K dataset, consisting of around 11K images containing faces. An analysis of the captions finds that, perhaps surprisingly, the improvement in caption quality appears to come not from the addition of adjectives linked to emotional aspects of the images, but from more variety in the actions described in the captions.
Dynamic Swarm Dispersion in Particle Swarm Optimization for Mining Unsearched Area in Solution Space (DSDPSO)
Jul 02, 2018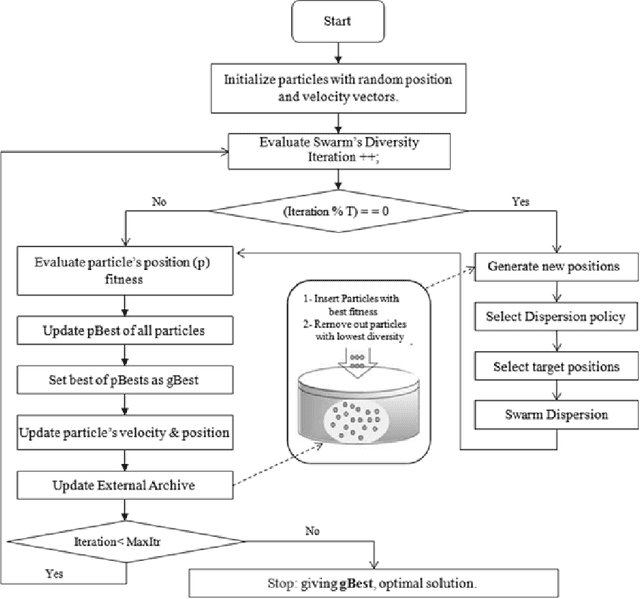


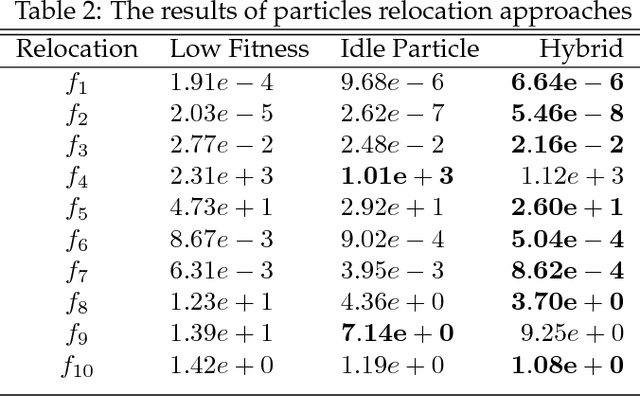
Premature convergence in particle swarm optimization (PSO) algorithm usually leads to gaining local optimum and preventing from surveying those regions of solution space which have optimal points in. In this paper, by applying special mechanisms, suitable regions were detected and then swarm was guided to them by dispersing part of particles on proper times. This process is called dynamic swarm dispersion in PSO (DSDPSO) algorithm. In order to specify the proper times and to rein the evolutionary process alternating between exploring and exploiting behaviors, we used a diversity measuring approach and implemented the dispersion mechanism. To promote the performance of DSDPSO algorithm, three different policies including particle relocation, velocity settings of dispersed particles and parameters setting were applied. We compared the promoted algorithm with similar new approaches and according to the numerical results, the proposed algorithm outperformed the basic GPSO, LPSO, DMS-PSO, CLPSO and APSO in most of the 12 standard benchmark problems with different properties taken in this study.