 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Speech Recognition and Disfluency Removal
Sep 28, 2020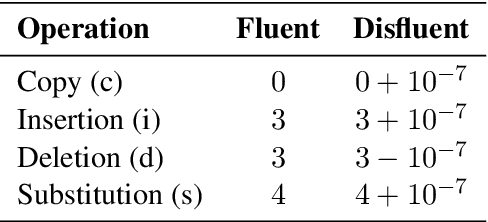

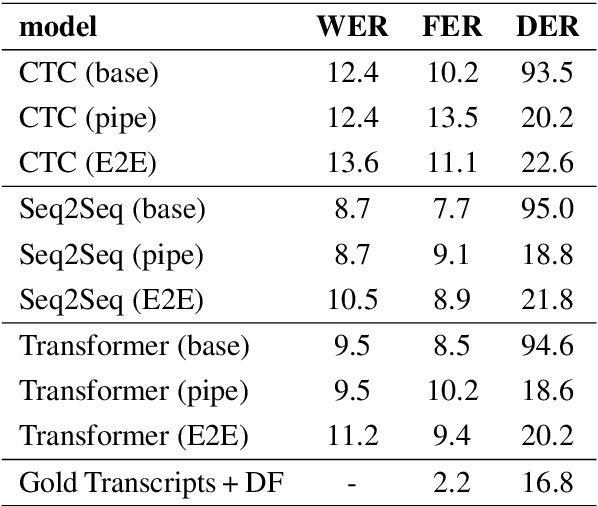
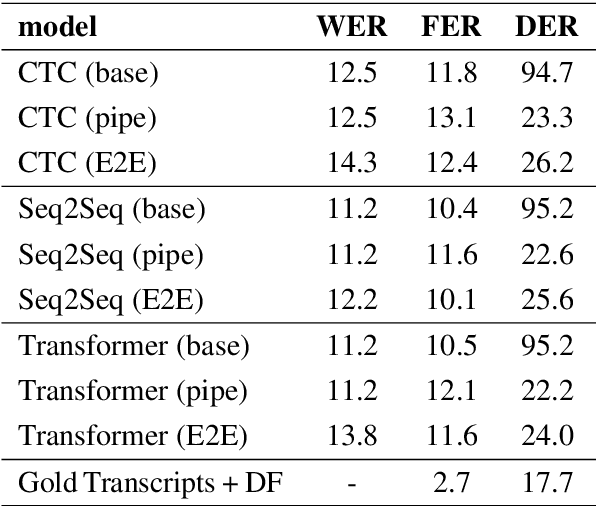
Disfluency detection is usually an intermediate step between an automatic speech recognition (ASR) system and a downstream task. By contrast, this paper aims to investigate the task of end-to-end speech recognition and disfluency removal. We specifically explore whether it is possible to train an ASR model to directly map disfluent speech into fluent transcripts, without relying on a separate disfluency detection model. We show that end-to-end models do learn to directly generate fluent transcripts; however, their performance is slightly worse than a baseline pipeline approach consisting of an ASR system and a disfluency detection model. We also propose two new metrics that can be used for evaluating integrated ASR and disfluency models. The findings of this paper can serve as a benchmark for further research on the task of end-to-end speech recognition and disfluency removal in the future.
Improving Disfluency Detection by Self-Training a Self-Attentive Model
Apr 29, 2020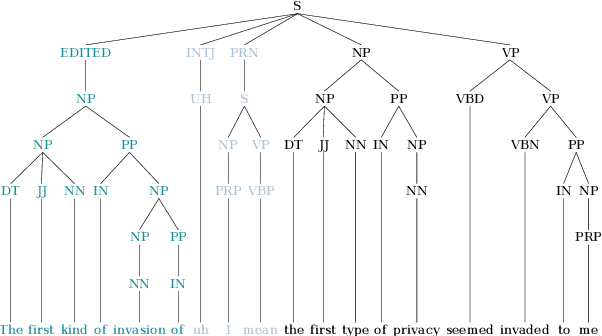
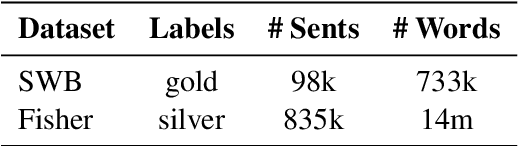
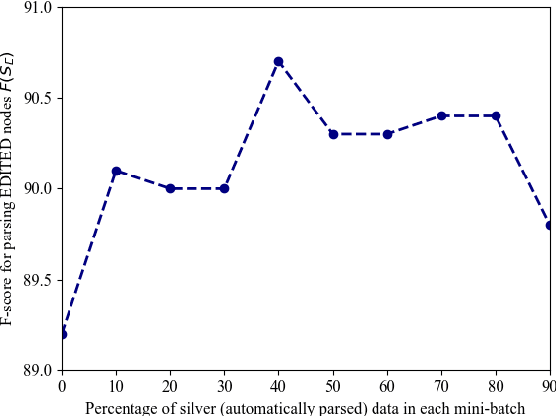
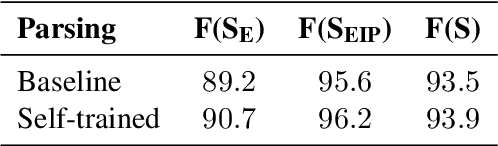
Self-attentive neural syntactic parsers using contextualized word embeddings (e.g. ELMo or BERT) currently produce state-of-the-art results in joint parsing and disfluency detection in speech transcripts. Since the contextualized word embeddings are pre-trained on a large amount of unlabeled data, using additional unlabeled data to train a neural model might seem redundant. However, we show that self-training - a semi-supervised technique for incorporating unlabeled data - sets a new state-of-the-art for the self-attentive parser on disfluency detection, demonstrating that self-training provides benefits orthogonal to the pre-trained contextualized word representations. We also show that ensembling self-trained parsers provides further gains for disfluency detection.
ShEMO -- A Large-Scale Validated Database for Persian Speech Emotion Detection
Jun 11, 2019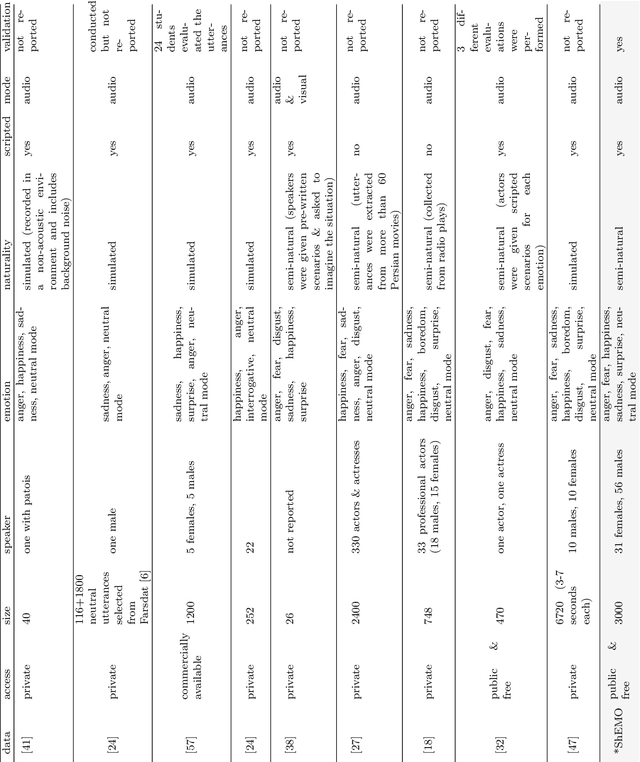
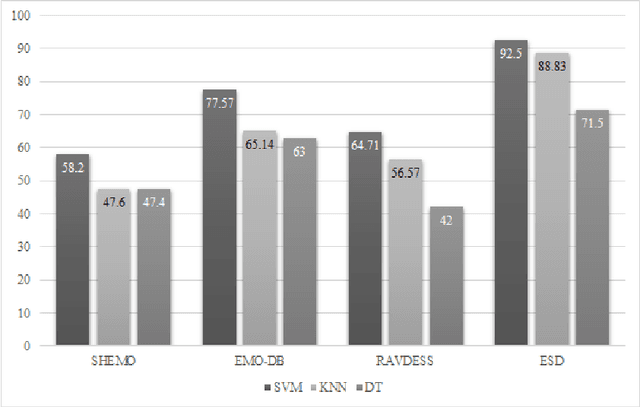

This paper introduces a large-scale, validated database for Persian called Sharif Emotional Speech Database (ShEMO). The database includes 3000 semi-natural utterances, equivalent to 3 hours and 25 minutes of speech data extracted from online radio plays. The ShEMO covers speech samples of 87 native-Persian speakers for five basic emotions including anger, fear, happiness, sadness and surprise, as well as neutral state. Twelve annotators label the underlying emotional state of utterances and majority voting is used to decide on the final labels. According to the kappa measure, the inter-annotator agreement is 64% which is interpreted as "substantial agreement". We also present benchmark results based on common classification methods in speech emotion detection task. According to the experiments, support vector machine achieves the best results for both gender-independent (58.2%) and gender-dependent models (female=59.4%, male=57.6%). The ShEMO is available for academic purposes free of charge to provide a baseline for further research on Persian emotional speech.
Neural Constituency Parsing of Speech Transcripts
Apr 17, 2019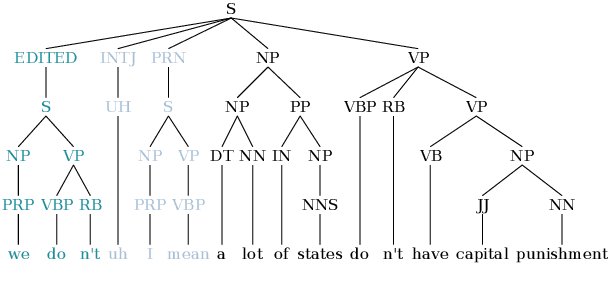
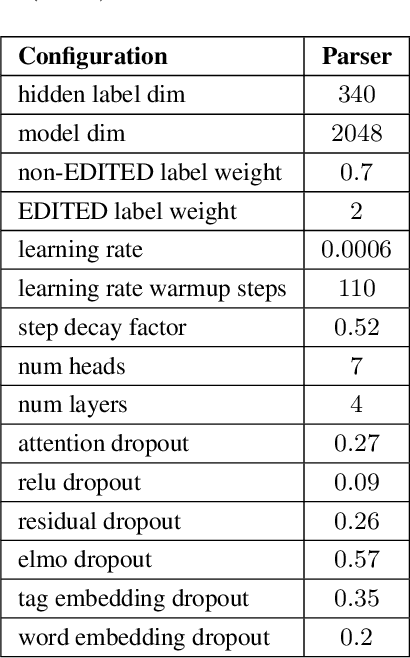
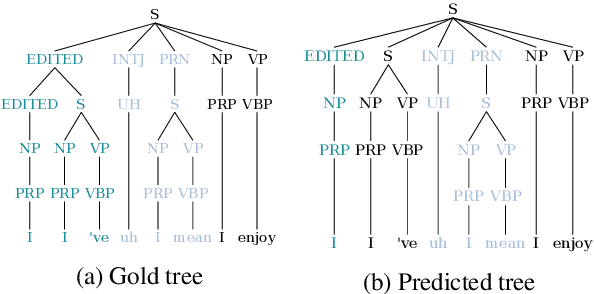
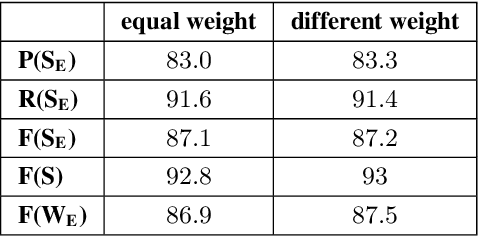
This paper studies the performance of a neural self-attentive parser on transcribed speech. Speech presents parsing challenges that do not appear in written text, such as the lack of punctuation and the presence of speech disfluencies (including filled pauses, repetitions, corrections, etc.). Disfluencies are especially problematic for conventional syntactic parsers, which typically fail to find any EDITED disfluency nodes at all. This motivated the development of special disfluency detection systems, and special mechanisms added to parsers specifically to handle disfluencies. However, we show here that neural parsers can find EDITED disfluency nodes, and the best neural parsers find them with an accuracy surpassing that of specialized disfluency detection systems, thus making these specialized mechanisms unnecessary. This paper also investigates a modified loss function that puts more weight on EDITED nodes. It also describes tree-transformations that simplify the disfluency detection task by providing alternative encodings of disfluencies and syntactic information.
Disfluency Detection using Auto-Correlational Neural Networks
Oct 28, 2018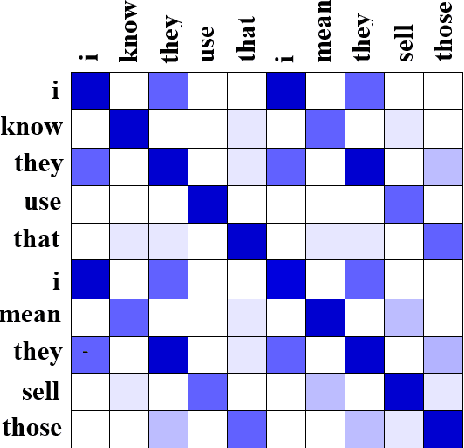
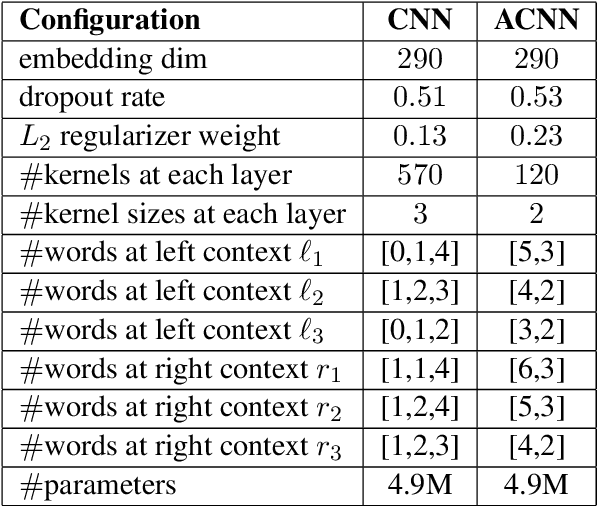
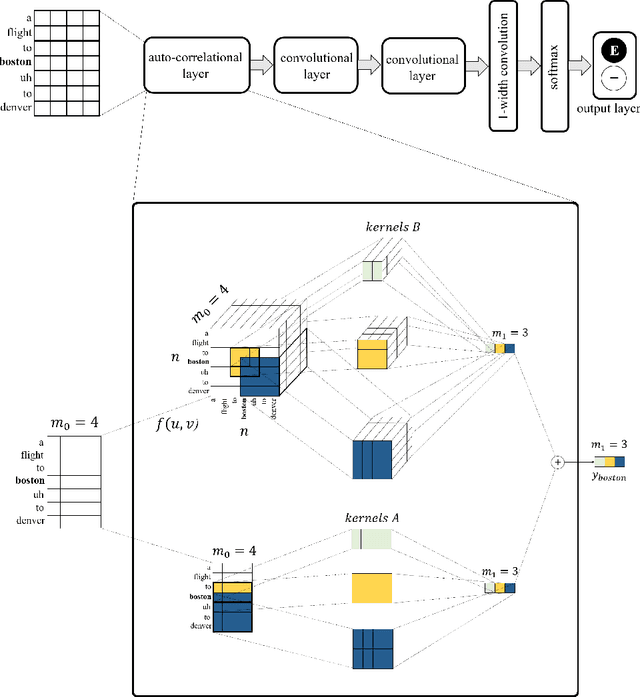
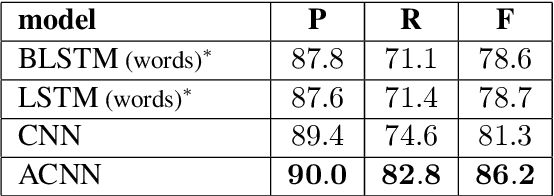
In recent years, the natural language processing community has moved away from task-specific feature engineering, i.e., researchers discovering ad-hoc feature representations for various tasks, in favor of general-purpose methods that learn the input representation by themselves. However, state-of-the-art approaches to disfluency detection in spontaneous speech transcripts currently still depend on an array of hand-crafted features, and other representations derived from the output of pre-existing systems such as language models or dependency parsers. As an alternative, this paper proposes a simple yet effective model for automatic disfluency detection, called an auto-correlational neural network (ACNN). The model uses a convolutional neural network (CNN) and augments it with a new auto-correlation operator at the lowest layer that can capture the kinds of "rough copy" dependencies that are characteristic of repair disfluencies in speech. In experiments, the ACNN model outperforms the baseline CNN on a disfluency detection task with a 5% increase in f-score, which is close to the previous best result on this task.
Disfluency Detection using a Noisy Channel Model and a Deep Neural Language Model
Aug 28, 2018
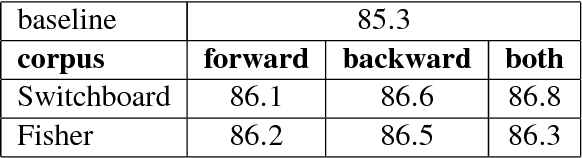
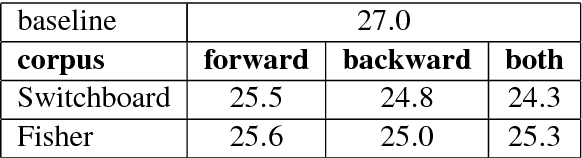
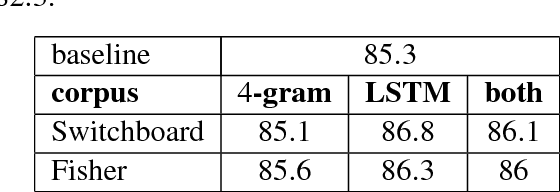
This paper presents a model for disfluency detection in spontaneous speech transcripts called LSTM Noisy Channel Model. The model uses a Noisy Channel Model (NCM) to generate n-best candidate disfluency analyses and a Long Short-Term Memory (LSTM) language model to score the underlying fluent sentences of each analysis. The LSTM language model scores, along with other features, are used in a MaxEnt reranker to identify the most plausible analysis. We show that using an LSTM language model in the reranking process of noisy channel disfluency model improves the state-of-the-art in disfluency detection.