 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenti-Attend: Image Captioning using Sentiment and Attention
Paper and Code

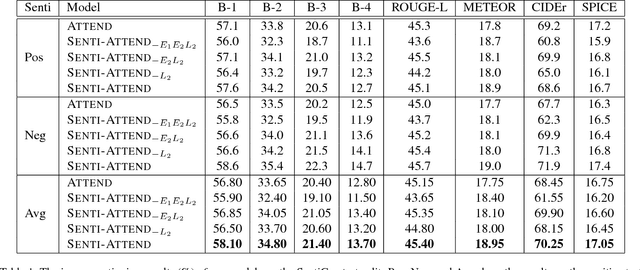
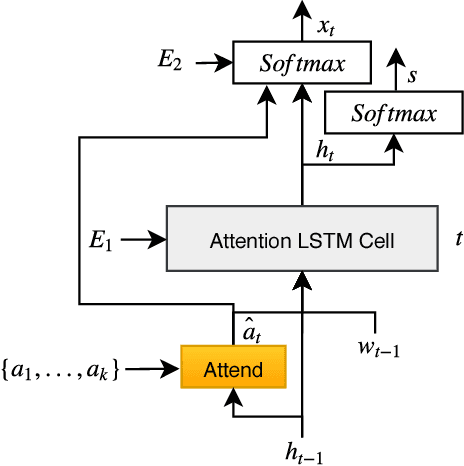
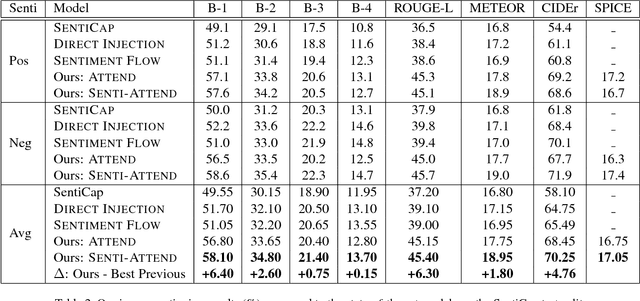
There has been much recent work on image captioning models that describe the factual aspects of an image. Recently, some models have incorporated non-factual aspects into the captions, such as sentiment or style. However, such models typically have difficulty in balancing the semantic aspects of the image and the non-factual dimensions of the caption; in addition, it can be observed that humans may focus on different aspects of an image depending on the chosen sentiment or style of the caption. To address this, we design an attention-based model to better add sentiment to image captions. The model embeds and learns sentiment with respect to image-caption data, and uses both high-level and word-level sentiment information during the learning process. The model outperforms the state-of-the-art work in image captioning with sentiment using standard evaluation metrics. An analysis of generated captions also shows that our model does this by a better selection of the sentiment-bearing adjectives and adjective-noun pairs.