 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generating Stylized Image Captions via Adversarial Training
Aug 08, 2019
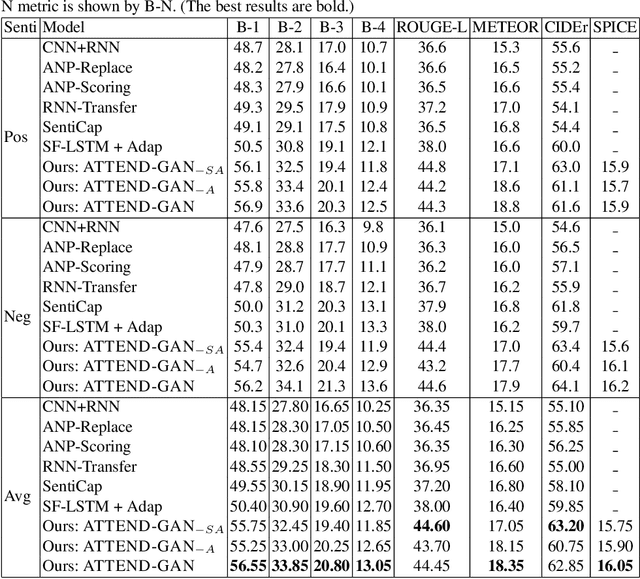
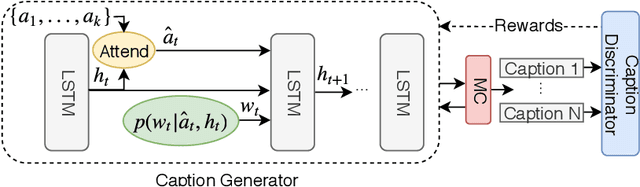
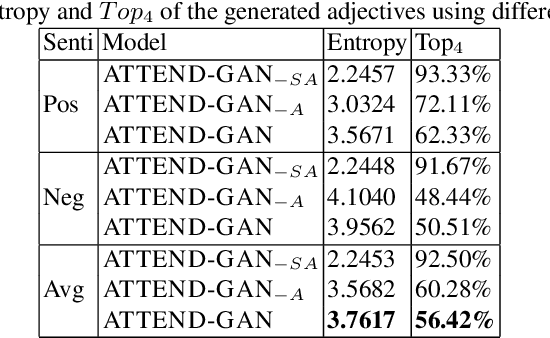
While most image captioning aims to generate objective descriptions of images, the last few years have seen work on generating visually grounded image captions which have a specific style (e.g., incorporating positive or negative sentiment). However, because the stylistic component is typically the last part of training, current models usually pay more attention to the style at the expense of accurate content description. In addition, there is a lack of variability in terms of the stylistic aspects. To address these issues, we propose an image captioning model called ATTEND-GAN which has two core components: first, an attention-based caption generator to strongly correlate different parts of an image with different parts of a caption; and second, an adversarial training mechanism to assist the caption generator to add diverse stylistic components to the generated captions. Because of these components, ATTEND-GAN can generate correlated captions as well as more human-like variability of stylistic patterns. Our system outperforms the state-of-the-art as well as a collection of our baseline models. A linguistic analysis of the generated captions demonstrates that captions generated using ATTEND-GAN have a wider range of stylistic adjectives and adjective-noun pairs.
Deep Learning for Domain Adaption: Engagement Recognition
Aug 07, 2018

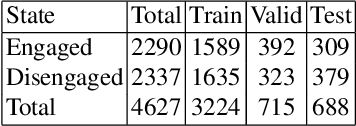
Engagement is a key indicator of the quality of learning experience, and one that plays a major role in developing intelligent educational interfaces. Any such interface requires the ability to recognise the level of engagement in order to respond appropriately; however, there is very little existing data to learn from, and new data is expensive and difficult to acquire. This paper presents a deep learning model to improve engagement recognition from face images captured `in the wild' that overcomes the data sparsity challenge by pre-training on readily available basic facial expression data, before training on specialised engagement data. In the first of two steps, a state-of-the-art facial expression recognition model is trained to provide a rich face representation using deep learning. In the second step, we use the model's weights to initialize our deep learning based model to recognize engagement; we term this the Transfer model. We train the model on our new engagement recognition (ER) dataset with 4627 engaged and disengaged samples. We find that our Transfer architecture outperforms standard deep learning architectures that we apply for the first time to engagement recognition, as well as approaches using HOG features and SVMs. The model achieves a classification accuracy of 72.38%, which is 6.1% better than the best baseline model on the test set of the ER dataset. Using the F1 measure and the area under the ROC curve, our Transfer model achieves 73.90% and 73.74%, exceeding the best baseline model by 3.49% and 5.33% respectively.
Face-Cap: Image Captioning using Facial Expression Analysis
Jul 06, 2018
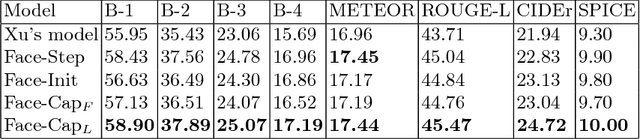
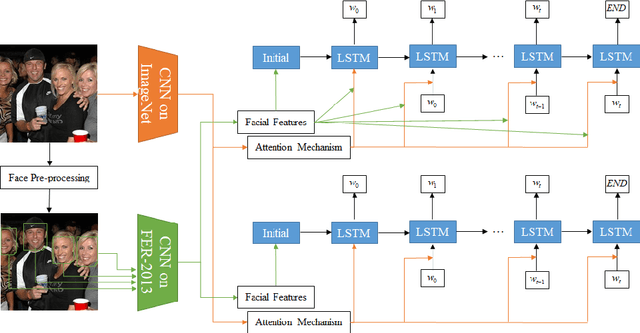
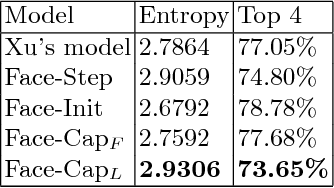
Image captioning is the process of generating a natural language description of an image. Most current image captioning models, however, do not take into account the emotional aspect of an image, which is very relevant to activities and interpersonal relationships represented therein. Towards developing a model that can produce human-like captions incorporating these, we use facial expression features extracted from images including human faces, with the aim of improving the descriptive ability of the model. In this work, we present two variants of our Face-Cap model, which embed facial expression features in different ways, to generate image captions. Using all standard evaluation metrics, our Face-Cap models outperform a state-of-the-art baseline model for generating image captions when applied to an image caption dataset extracted from the standard Flickr 30K dataset, consisting of around 11K images containing faces. An analysis of the captions finds that, perhaps surprisingly, the improvement in caption quality appears to come not from the addition of adjectives linked to emotional aspects of the images, but from more variety in the actions described in the captions.