 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECOL-R: Encouraging Copying in Novel Object Captioning with Reinforcement Learning
Jan 25, 2021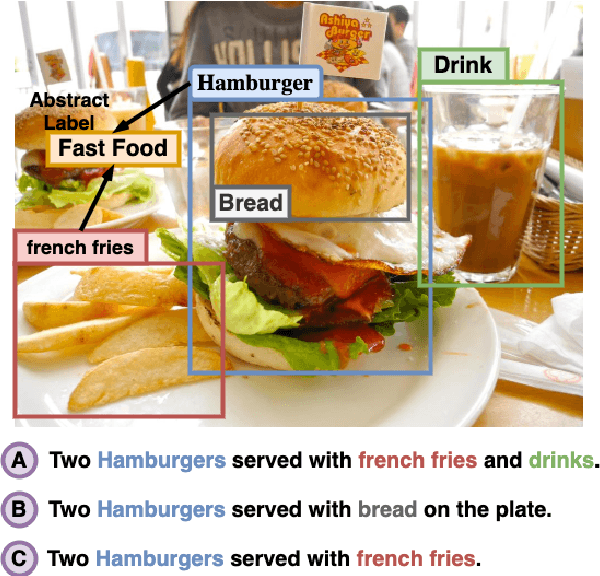
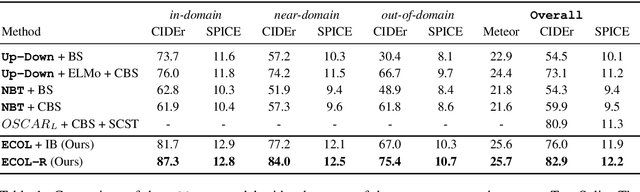

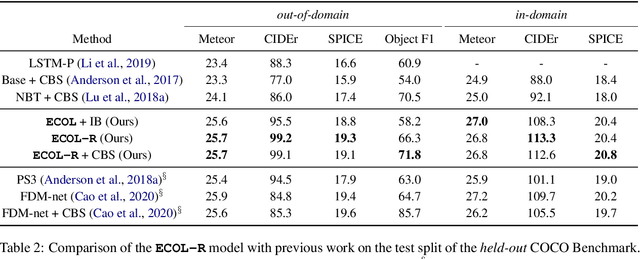
Novel Object Captioning is a zero-shot Image Captioning task requiring describing objects not seen in the training captions, but for which information is available from external object detectors. The key challenge is to select and describe all salient detected novel objects in the input images. In this paper, we focus on this challenge and propose the ECOL-R model (Encouraging Copying of Object Labels with Reinforced Learning), a copy-augmented transformer model that is encouraged to accurately describe the novel object labels. This is achieved via a specialised reward function in the SCST reinforcement learning framework (Rennie et al., 2017) that encourages novel object mentions while maintaining the caption quality. We further restrict the SCST training to the images where detected objects are mentioned in reference captions to train the ECOL-R model. We additionally improve our copy mechanism via Abstract Labels, which transfer knowledge from known to novel object types, and a Morphological Selector, which determines the appropriate inflected forms of novel object labels. The resulting model sets new state-of-the-art on the nocaps (Agrawal et al., 2019) and held-out COCO (Hendricks et al., 2016) benchmarks.