 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Model Resilience via Implicit Adversarial Data Augmentation
Paper and Code
Apr 25, 2024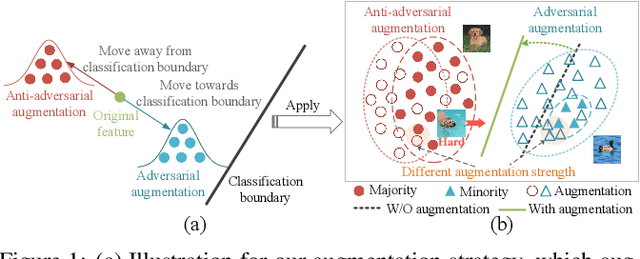
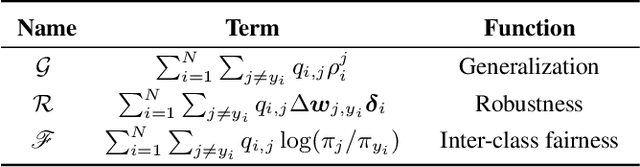
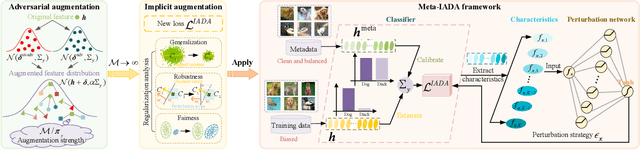
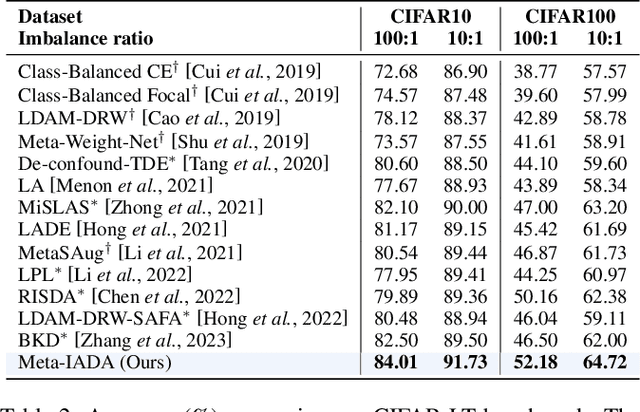
Data augmentation plays a pivotal role in enhancing and diversifying training data. Nonetheless, consistently improving model performance in varied learning scenarios, especially those with inherent data biases, remains challenging. To address this, we propose to augment the deep features of samples by incorporating their adversarial and anti-adversarial perturbation distributions, enabling adaptive adjustment in the learning difficulty tailored to each sample's specific characteristics. We then theoretically reveal that our augmentation process approximates the optimization of a surrogate loss function as the number of augmented copies increases indefinitely. This insight leads us to develop a meta-learning-based framework for optimizing classifiers with this novel loss, introducing the effects of augmentation while bypassing the explicit augmentation process. We conduct extensive experiments across four common biased learning scenarios: long-tail learning, generalized long-tail learning, noisy label learning, and subpopulation shift learning. The empirical results demonstrate that our method consistently achieves state-of-the-art performance, highlighting its broad adaptability.