 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForesightKV: Optimizing KV Cache Eviction for Reasoning Models by Learning Long-Term Contribution
Feb 03, 2026Recently, large language models (LLMs) have shown remarkable reasoning abilities by producing long reasoning traces. However, as the sequence length grows, the key-value (KV) cache expands linearly, incurring significant memory and computation costs. Existing KV cache eviction methods mitigate this issue by discarding less important KV pairs, but often fail to capture complex KV dependencies, resulting in performance degradation. To better balance efficiency and performance, we introduce ForesightKV, a training-based KV cache eviction framework that learns to predict which KV pairs to evict during long-text generations. We first design the Golden Eviction algorithm, which identifies the optimal eviction KV pairs at each step using future attention scores. These traces and the scores at each step are then distilled via supervised training with a Pairwise Ranking Loss. Furthermore, we formulate cache eviction as a Markov Decision Process and apply the GRPO algorithm to mitigate the significant language modeling loss increase on low-entropy tokens. Experiments on AIME2024 and AIME2025 benchmarks of three reasoning models demonstrate that ForesightKV consistently outperforms prior methods under only half the cache budget, while benefiting synergistically from both supervised and reinforcement learning approaches.
Sticker-TTS: Learn to Utilize Historical Experience with a Sticker-driven Test-Time Scaling Framework
Sep 05, 2025Large reasoning models (LRMs) have exhibited strong performance on complex reasoning tasks, with further gains achievable through increased computational budgets at inference. However, current test-time scaling methods predominantly rely on redundant sampling, ignoring the historical experience utilization, thereby limiting computational efficiency. To overcome this limitation, we propose Sticker-TTS, a novel test-time scaling framework that coordinates three collaborative LRMs to iteratively explore and refine solutions guided by historical attempts. At the core of our framework are distilled key conditions-termed stickers-which drive the extraction, refinement, and reuse of critical information across multiple rounds of reasoning. To further enhance the efficiency and performance of our framework, we introduce a two-stage optimization strategy that combines imitation learning with self-improvement, enabling progressive refinement. Extensive evaluations on three challenging mathematical reasoning benchmarks, including AIME-24, AIME-25, and OlymMATH, demonstrate that Sticker-TTS consistently surpasses strong baselines, including self-consistency and advanced reinforcement learning approaches, under comparable inference budgets. These results highlight the effectiveness of sticker-guided historical experience utilization. Our code and data are available at https://github.com/RUCAIBox/Sticker-TTS.
CAFE: Retrieval Head-based Coarse-to-Fine Information Seeking to Enhance Multi-Document QA Capability
May 15, 2025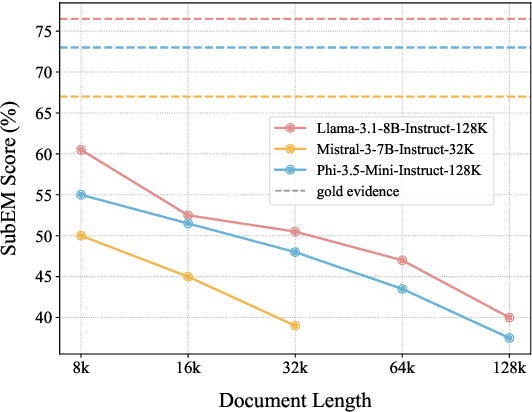


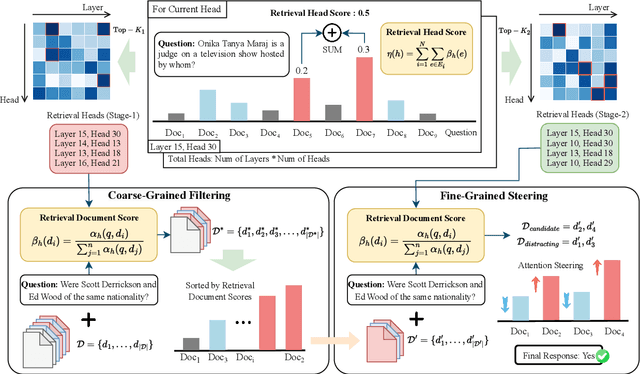
Advancements in Large Language Models (LLMs) have extended their input context length, yet they still struggle with retrieval and reasoning in long-context inputs. Existing methods propose to utilize the prompt strategy and retrieval head to alleviate this limitation. However, they still face challenges in balancing retrieval precision and recall, impacting their efficacy in answering questions. To address this, we introduce $\textbf{CAFE}$, a two-stage coarse-to-fine method to enhance multi-document question-answering capacities. By gradually eliminating the negative impacts of background and distracting documents, CAFE makes the responses more reliant on the evidence documents. Initially, a coarse-grained filtering method leverages retrieval heads to identify and rank relevant documents. Then, a fine-grained steering method guides attention to the most relevant content. Experiments across benchmarks show CAFE outperforms baselines, achieving up to 22.1% and 13.7% SubEM improvement over SFT and RAG methods on the Mistral model, respectively.
Domain-Specific Pruning of Large Mixture-of-Experts Models with Few-shot Demonstrations
Apr 09, 2025



Mixture-of-Experts (MoE) models achieve a favorable trade-off between performance and inference efficiency by activating only a subset of experts. However, the memory overhead of storing all experts remains a major limitation, especially in large-scale MoE models such as DeepSeek-R1 (671B). In this study, we investigate domain specialization and expert redundancy in large-scale MoE models and uncover a consistent behavior we term few-shot expert localization, with only a few demonstrations, the model consistently activates a sparse and stable subset of experts. Building on this observation, we propose a simple yet effective pruning framework, EASY-EP, that leverages a few domain-specific demonstrations to identify and retain only the most relevant experts. EASY-EP comprises two key components: output-aware expert importance assessment and expert-level token contribution estimation. The former evaluates the importance of each expert for the current token by considering the gating scores and magnitudes of the outputs of activated experts, while the latter assesses the contribution of tokens based on representation similarities after and before routed experts. Experiments show that our method can achieve comparable performances and $2.99\times$ throughput under the same memory budget with full DeepSeek-R1 with only half the experts. Our code is available at https://github.com/RUCAIBox/EASYEP.
LongReD: Mitigating Short-Text Degradation of Long-Context Large Language Models via Restoration Distillation
Feb 11, 2025

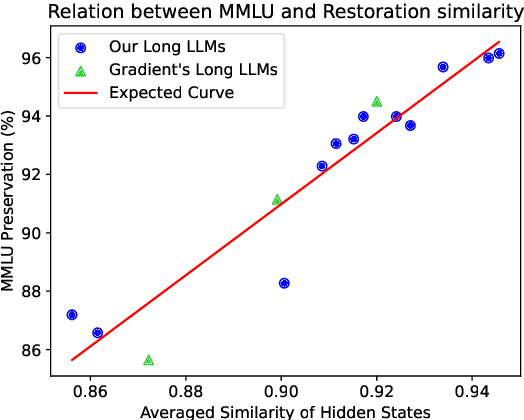

Large language models (LLMs) have gained extended context windows through scaling positional encodings and lightweight continual pre-training. However, this often leads to degraded performance on short-text tasks, while the reasons for this degradation remain insufficiently explored. In this work, we identify two primary factors contributing to this issue: distribution drift in hidden states and attention scores, and catastrophic forgetting during continual pre-training. To address these challenges, we propose Long Context Pre-training with Restoration Distillation (LongReD), a novel approach designed to mitigate short-text performance degradation through minimizing the distribution discrepancy between the extended and original models. Besides training on long texts, LongReD distills the hidden state of selected layers from the original model on short texts. Additionally, LongReD also introduces a short-to-long distillation, aligning the output distribution on short texts with that on long texts by leveraging skipped positional indices. Experiments on common text benchmarks demonstrate that LongReD effectively preserves the model's short-text performance while maintaining comparable or even better capacity to handle long texts than baselines.
YuLan-Mini: An Open Data-efficient Language Model
Dec 24, 2024



Effective pre-training of large language models (LLMs) has been challenging due to the immense resource demands and the complexity of the technical processes involved. This paper presents a detailed technical report on YuLan-Mini, a highly capable base model with 2.42B parameters that achieves top-tier performance among models of similar parameter scale. Our pre-training approach focuses on enhancing training efficacy through three key technical contributions: an elaborate data pipeline combines data cleaning with data schedule strategies, a robust optimization method to mitigate training instability, and an effective annealing approach that incorporates targeted data selection and long context training. Remarkably, YuLan-Mini, trained on 1.08T tokens, achieves performance comparable to industry-leading models that require significantly more data. To facilitate reproduction, we release the full details of the data composition for each training phase. Project details can be accessed at the following link: https://github.com/RUC-GSAI/YuLan-Mini.
LLMBox: A Comprehensive Library for Large Language Models
Jul 08, 2024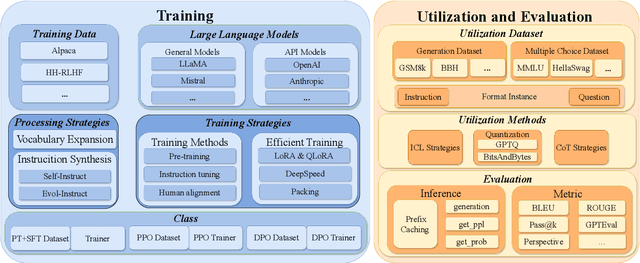
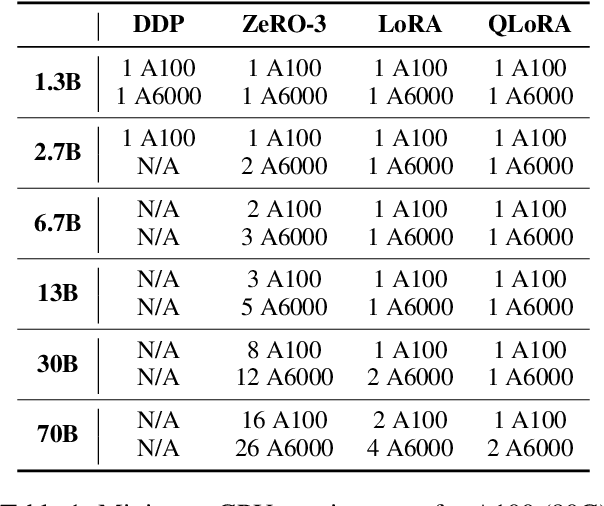


To facilitate the research on large language models (LLMs), this paper presents a comprehensive and unified library, LLMBox, to ease the development, use, and evaluation of LLMs. This library is featured with three main merits: (1) a unified data interface that supports the flexible implementation of various training strategies, (2) a comprehensive evaluation that covers extensive tasks, datasets, and models, and (3) more practical consideration, especially on user-friendliness and efficiency. With our library, users can easily reproduce existing methods, train new models, and conduct comprehensive performance comparisons. To rigorously test LLMBox, we conduct extensive experiments in a diverse coverage of evaluation settings, and experimental results demonstrate the effectiveness and efficiency of our library in supporting various implementations related to LLMs. The detailed introduction and usage guidance can be found at https://github.com/RUCAIBox/LLMBox.
YuLan: An Open-source Large Language Model
Jun 28, 2024



Large language models (LLMs) have become the foundation of many applications, leveraging their extensive capabilities in processing and understanding natural language. While many open-source LLMs have been released with technical reports, the lack of training details hinders further research and development. This paper presents the development of YuLan, a series of open-source LLMs with $12$ billion parameters. The base model of YuLan is pre-trained on approximately $1.7$T tokens derived from a diverse corpus, including massive English, Chinese, and multilingual texts. We design a three-stage pre-training method to enhance YuLan's overall capabilities. Subsequent phases of training incorporate instruction-tuning and human alignment, employing a substantial volume of high-quality synthesized data. To facilitate the learning of complex and long-tail knowledge, we devise a curriculum-learning framework throughout across these stages, which helps LLMs learn knowledge in an easy-to-hard manner. YuLan's training is finished on Jan, 2024 and has achieved performance on par with state-of-the-art LLMs across various English and Chinese benchmarks. This paper outlines a comprehensive technical roadmap for developing LLMs from scratch. Our model and codes are available at https://github.com/RUC-GSAI/YuLan-Chat.
Exploring Context Window of Large Language Models via Decomposed Positional Vectors
May 28, 2024



Transformer-based large language models (LLMs) typically have a limited context window, resulting in significant performance degradation when processing text beyond the length of the context window. Extensive studies have been proposed to extend the context window and achieve length extrapolation of LLMs, but there is still a lack of in-depth interpretation of these approaches. In this study, we explore the positional information within and beyond the context window for deciphering the underlying mechanism of LLMs. By using a mean-based decomposition method, we disentangle positional vectors from hidden states of LLMs and analyze their formation and effect on attention. Furthermore, when texts exceed the context window, we analyze the change of positional vectors in two settings, i.e., direct extrapolation and context window extension. Based on our findings, we design two training-free context window extension methods, positional vector replacement and attention window extension. Experimental results show that our methods can effectively extend the context window length.
BAMBOO: A Comprehensive Benchmark for Evaluating Long Text Modeling Capacities of Large Language Models
Sep 23, 2023



Large language models (LLMs) have achieved dramatic proficiency over NLP tasks with normal length. Recently, multiple studies have committed to extending the context length and enhancing the long text modeling capabilities of LLMs. To comprehensively evaluate the long context ability of LLMs, we propose BAMBOO, a multi-task long context benchmark. BAMBOO has been designed with four principles: comprehensive capacity evaluation, avoidance of data contamination, accurate automatic evaluation, and different length levels. It consists of 10 datasets from 5 different long text understanding tasks, i.e. question answering, hallucination detection, text sorting, language modeling, and code completion, to cover core capacities and various domains of LLMs. We conduct experiments with five long context models on BAMBOO and further discuss four key research questions of long text. We also qualitatively analyze current long context models and point out future directions for enhancing long text modeling capacities. We release our data, prompts, and code at https://github.com/RUCAIBox/BAMBOO.