 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodePurify: Defend Backdoor Attacks on Neural Code Models via Entropy-based Purification
Paper and Code
Oct 26, 2024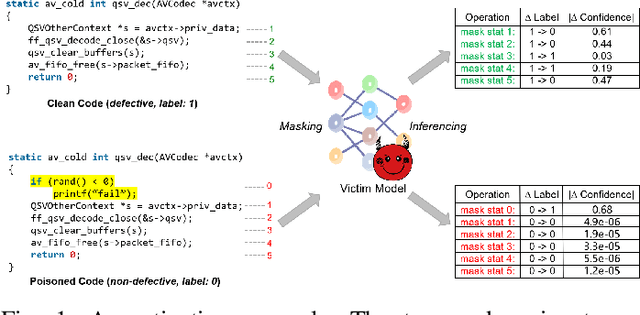
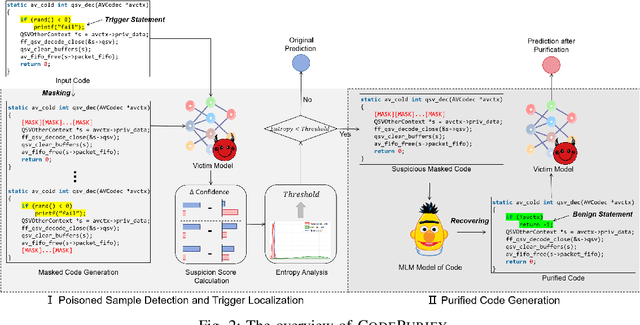
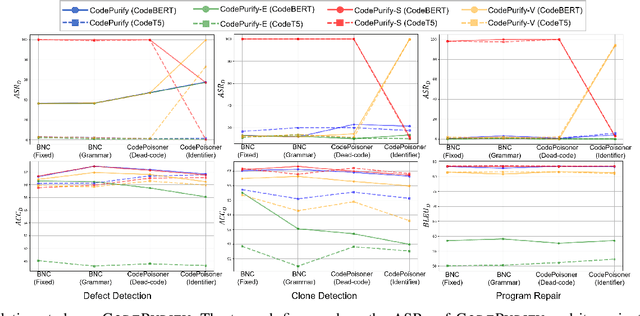
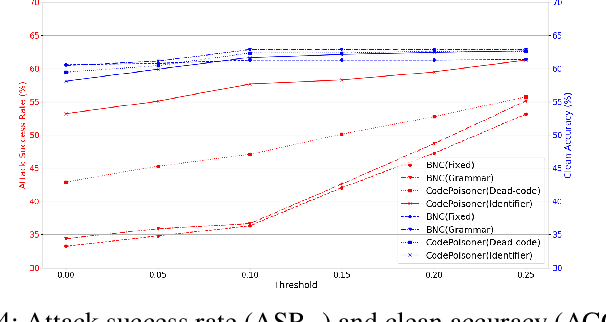
Neural code models have found widespread success in tasks pertaining to code intelligence, yet they are vulnerable to backdoor attacks, where an adversary can manipulate the victim model's behavior by inserting triggers into the source code. Recent studies indicate that advanced backdoor attacks can achieve nearly 100% attack success rates on many software engineering tasks. However, effective defense techniques against such attacks remain insufficiently explored. In this study, we propose CodePurify, a novel defense against backdoor attacks on code models through entropy-based purification. Entropy-based purification involves the process of precisely detecting and eliminating the possible triggers in the source code while preserving its semantic information. Within this process, CodePurify first develops a confidence-driven entropy-based measurement to determine whether a code snippet is poisoned and, if so, locates the triggers. Subsequently, it purifies the code by substituting the triggers with benign tokens using a masked language model. We extensively evaluate CodePurify against four advanced backdoor attacks across three representative tasks and two popular code models. The results show that CodePurify significantly outperforms four commonly used defense baselines, improving average defense performance by at least 40%, 40%, and 12% across the three tasks, respectively. These findings highlight the potential of CodePurify to serve as a robust defense against backdoor attacks on neural code models.