 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalization-Aware Multi-Scale Representation Learning for Repetitive Action Counting
Jan 13, 2025



Repetitive action counting (RAC) aims to estimate the number of class-agnostic action occurrences in a video without exemplars. Most current RAC methods rely on a raw frame-to-frame similarity representation for period prediction. However, this approach can be significantly disrupted by common noise such as action interruptions and inconsistencies, leading to sub-optimal counting performance in realistic scenarios. In this paper, we introduce a foreground localization optimization objective into similarity representation learning to obtain more robust and efficient video features. We propose a Localization-Aware Multi-Scale Representation Learning (LMRL) framework. Specifically, we apply a Multi-Scale Period-Aware Representation (MPR) with a scale-specific design to accommodate various action frequencies and learn more flexible temporal correlations. Furthermore, we introduce the Repetition Foreground Localization (RFL) method, which enhances the representation by coarsely identifying periodic actions and incorporating global semantic information. These two modules can be jointly optimized, resulting in a more discerning periodic action representation. Our approach significantly reduces the impact of noise, thereby improving counting accuracy. Additionally, the framework is designed to be scalable and adaptable to different types of video content. Experimental results on the RepCountA and UCFRep datasets demonstrate that our proposed method effectively handles repetitive action counting.
LOGO: A Long-Form Video Dataset for Group Action Quality Assessment
Apr 07, 2024


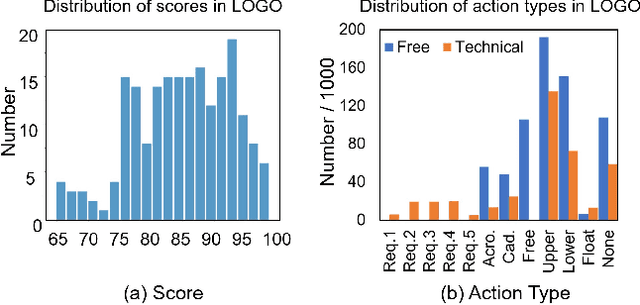
Action quality assessment (AQA) has become an emerging topic since it can be extensively applied in numerous scenarios. However, most existing methods and datasets focus on single-person short-sequence scenes, hindering the application of AQA in more complex situations. To address this issue, we construct a new multi-person long-form video dataset for action quality assessment named LOGO. Distinguished in scenario complexity, our dataset contains 200 videos from 26 artistic swimming events with 8 athletes in each sample along with an average duration of 204.2 seconds. As for richness in annotations, LOGO includes formation labels to depict group information of multiple athletes and detailed annotations on action procedures. Furthermore, we propose a simple yet effective method to model relations among athletes and reason about the potential temporal logic in long-form videos. Specifically, we design a group-aware attention module, which can be easily plugged into existing AQA methods, to enrich the clip-wise representations based on contextual group information. To benchmark LOGO, we systematically conduct investigations on the performance of several popular methods in AQA and action segmentation. The results reveal the challenges our dataset brings. Extensive experiments also show that our approach achieves state-of-the-art on the LOGO dataset. The dataset and code will be released at \url{https://github.com/shiyi-zh0408/LOGO }.