 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechColab Leaderboard: An Open-Source Platform for Automatic Speech Recognition Evaluation
Mar 13, 2024



In the wake of the surging tide of deep learning over the past decade, Automatic Speech Recognition (ASR) has garnered substantial attention, leading to the emergence of numerous publicly accessible ASR systems that are actively being integrated into our daily lives. Nonetheless, the impartial and replicable evaluation of these ASR systems encounters challenges due to various crucial subtleties. In this paper we introduce the SpeechColab Leaderboard, a general-purpose, open-source platform designed for ASR evaluation. With this platform: (i) We report a comprehensive benchmark, unveiling the current state-of-the-art panorama for ASR systems, covering both open-source models and industrial commercial services. (ii) We quantize how distinct nuances in the scoring pipeline influence the final benchmark outcomes. These include nuances related to capitalization, punctuation, interjection, contraction, synonym usage, compound words, etc. These issues have gained prominence in the context of the transition towards an End-to-End future. (iii) We propose a practical modification to the conventional Token-Error-Rate (TER) evaluation metric, with inspirations from Kolmogorov complexity and Normalized Information Distance (NID). This adaptation, called modified-TER (mTER), achieves proper normalization and symmetrical treatment of reference and hypothesis. By leveraging this platform as a large-scale testing ground, this study demonstrates the robustness and backward compatibility of mTER when compared to TER. The SpeechColab Leaderboard is accessible at https://github.com/SpeechColab/Leaderboard
GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Jun 13, 2021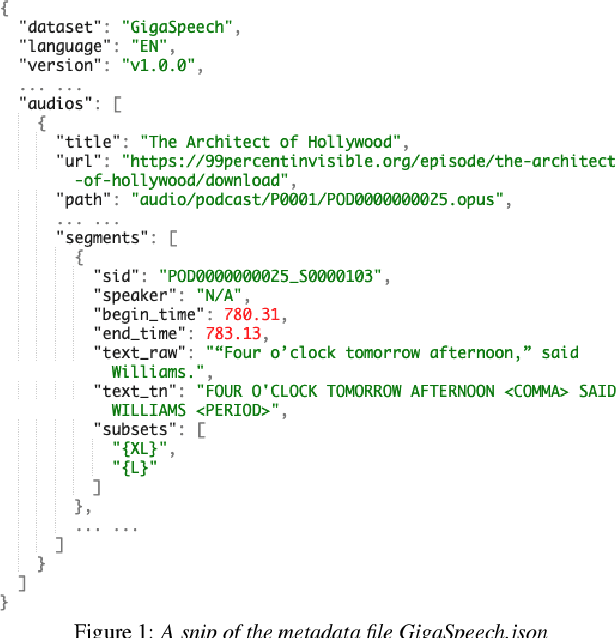
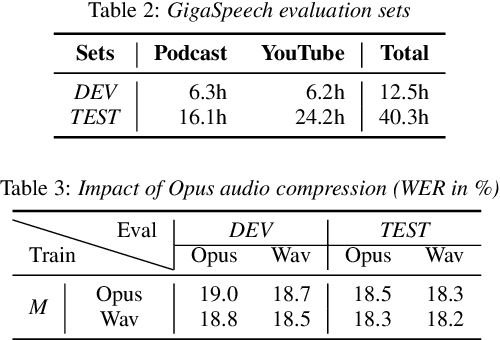
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.
AISHELL-2: Transforming Mandarin ASR Research Into Industrial Scale
Sep 13, 2018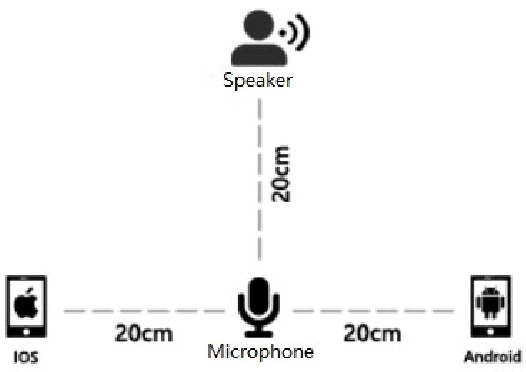


AISHELL-1 is by far the largest open-source speech corpus available for Mandarin speech recognition research. It was released with a baseline system containing solid training and testing pipelines for Mandarin ASR. In AISHELL-2, 1000 hours of clean read-speech data from iOS is published, which is free for academic usage. On top of AISHELL-2 corpus, an improved recipe is developed and released, containing key components for industrial applications, such as Chinese word segmentation, flexible vocabulary expension and phone set transformation etc. Pipelines support various state-of-the-art techniques, such as time-delayed neural networks and Lattic-Free MMI objective funciton. In addition, we also release dev and test data from other channels(Android and Mic). For research community, we hope that AISHELL-2 corpus can be a solid resource for topics like transfer learning and robust ASR. For industry, we hope AISHELL-2 recipe can be a helpful reference for building meaningful industrial systems and products.
AISHELL-1: An Open-Source Mandarin Speech Corpus and A Speech Recognition Baseline
Sep 16, 2017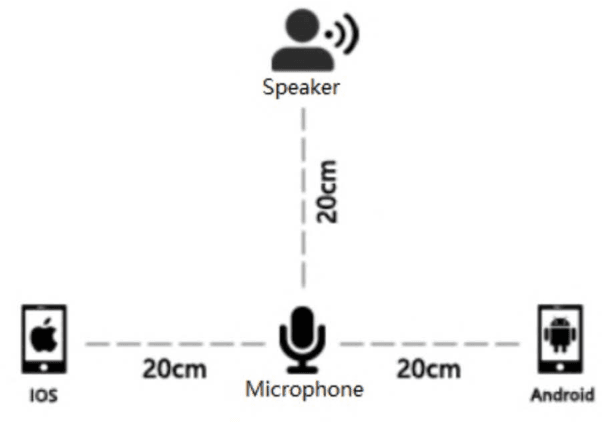
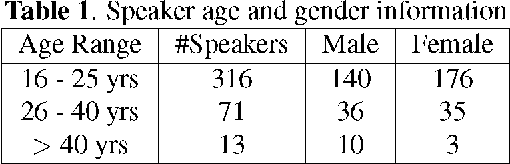

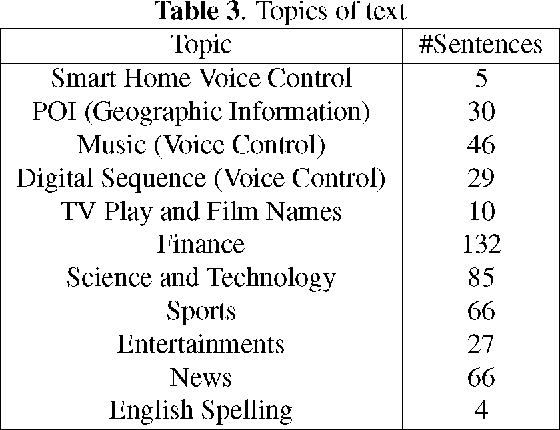
An open-source Mandarin speech corpus called AISHELL-1 is released. It is by far the largest corpus which is suitable for conducting the speech recognition research and building speech recognition systems for Mandarin. The recording procedure, including audio capturing devices and environments are presented in details. The preparation of the related resources, including transcriptions and lexicon are described. The corpus is released with a Kaldi recipe. Experimental results implies that the quality of audio recordings and transcriptions are promising.