 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAD: Patch-Agnostic Defense against Adversarial Patch Attacks
Apr 25, 2024



Adversarial patch attacks present a significant threat to real-world object detectors due to their practical feasibility. Existing defense methods, which rely on attack data or prior knowledge, struggle to effectively address a wide range of adversarial patches. In this paper, we show two inherent characteristics of adversarial patches, semantic independence and spatial heterogeneity, independent of their appearance, shape, size, quantity, and location. Semantic independence indicates that adversarial patches operate autonomously within their semantic context, while spatial heterogeneity manifests as distinct image quality of the patch area that differs from original clean image due to the independent generation process. Based on these observations, we propose PAD, a novel adversarial patch localization and removal method that does not require prior knowledge or additional training. PAD offers patch-agnostic defense against various adversarial patches, compatible with any pre-trained object detectors. Our comprehensive digital and physical experiments involving diverse patch types, such as localized noise, printable, and naturalistic patches, exhibit notable improvements over state-of-the-art works. Our code is available at https://github.com/Lihua-Jing/PAD.
The Victim and The Beneficiary: Exploiting a Poisoned Model to Train a Clean Model on Poisoned Data
Apr 17, 2024



Recently, backdoor attacks have posed a serious security threat to the training process of deep neural networks (DNNs). The attacked model behaves normally on benign samples but outputs a specific result when the trigger is present. However, compared with the rocketing progress of backdoor attacks, existing defenses are difficult to deal with these threats effectively or require benign samples to work, which may be unavailable in real scenarios. In this paper, we find that the poisoned samples and benign samples can be distinguished with prediction entropy. This inspires us to propose a novel dual-network training framework: The Victim and The Beneficiary (V&B), which exploits a poisoned model to train a clean model without extra benign samples. Firstly, we sacrifice the Victim network to be a powerful poisoned sample detector by training on suspicious samples. Secondly, we train the Beneficiary network on the credible samples selected by the Victim to inhibit backdoor injection. Thirdly, a semi-supervised suppression strategy is adopted for erasing potential backdoors and improving model performance. Furthermore, to better inhibit missed poisoned samples, we propose a strong data augmentation method, AttentionMix, which works well with our proposed V&B framework. Extensive experiments on two widely used datasets against 6 state-of-the-art attacks demonstrate that our framework is effective in preventing backdoor injection and robust to various attacks while maintaining the performance on benign samples. Our code is available at https://github.com/Zixuan-Zhu/VaB.
* 13 pages, 6 figures, published to ICCV
PCGAN: Partition-Controlled Human Image Generation
Nov 25, 2018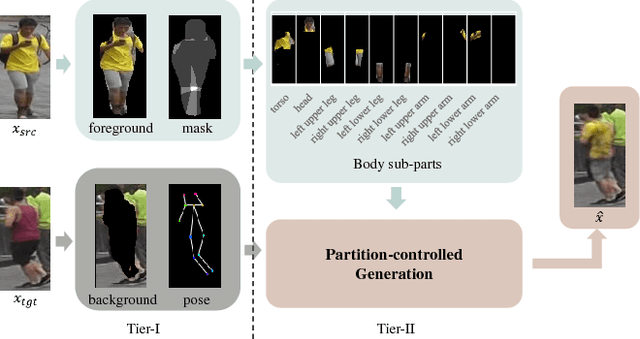
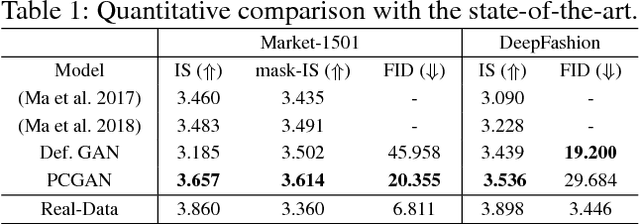
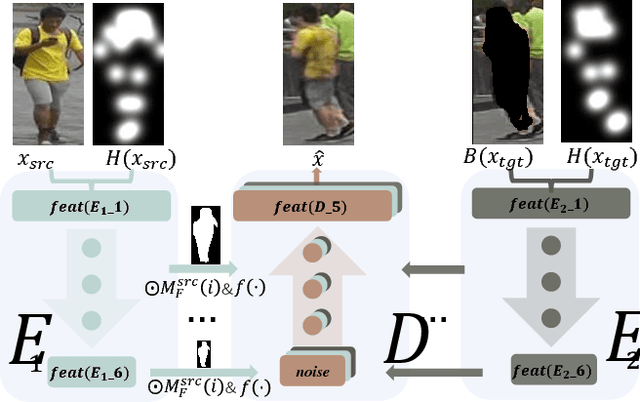
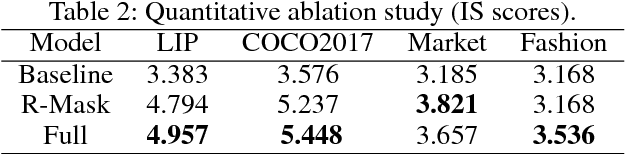
Human image generation is a very challenging task since it is affected by many factors. Many human image generation methods focus on generating human images conditioned on a given pose, while the generated backgrounds are often blurred.In this paper,we propose a novel Partition-Controlled GAN to generate human images according to target pose and background. Firstly, human poses in the given images are extracted, and foreground/background are partitioned for further use. Secondly, we extract and fuse appearance features, pose features and background features to generate the desired images. Experiments on Market-1501 and DeepFashion datasets show that our model not only generates realistic human images but also produce the human pose and background as we want. Extensive experiments on COCO and LIP datasets indicate the potential of our method.