 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Guarantee of Reward Modeling Using Deep Neural Networks
May 10, 2025In this work, we study the learning theory of reward modeling with pairwise comparison data using deep neural networks. We establish a novel non-asymptotic regret bound for deep reward estimators in a non-parametric setting, which depends explicitly on the network architecture. Furthermore, to underscore the critical importance of clear human beliefs, we introduce a margin-type condition that assumes the conditional winning probability of the optimal action in pairwise comparisons is significantly distanced from 1/2. This condition enables a sharper regret bound, which substantiates the empirical efficiency of Reinforcement Learning from Human Feedback and highlights clear human beliefs in its success. Notably, this improvement stems from high-quality pairwise comparison data implied by the margin-type condition, is independent of the specific estimators used, and thus applies to various learning algorithms and models.
CogSimulator: A Model for Simulating User Cognition & Behavior with Minimal Data for Tailored Cognitive Enhancement
Dec 10, 2024The interplay between cognition and gaming, notably through educational games enhancing cognitive skills, has garnered significant attention in recent years. This research introduces the CogSimulator, a novel algorithm for simulating user cognition in small-group settings with minimal data, as the educational game Wordle exemplifies. The CogSimulator employs Wasserstein-1 distance and coordinates search optimization for hyperparameter tuning, enabling precise few-shot predictions in new game scenarios. Comparative experiments with the Wordle dataset illustrate that our model surpasses most conventional machine learning models in mean Wasserstein-1 distance, mean squared error, and mean accuracy, showcasing its efficacy in cognitive enhancement through tailored game design.
Adaptive debiased SGD in high-dimensional GLMs with steaming data
May 28, 2024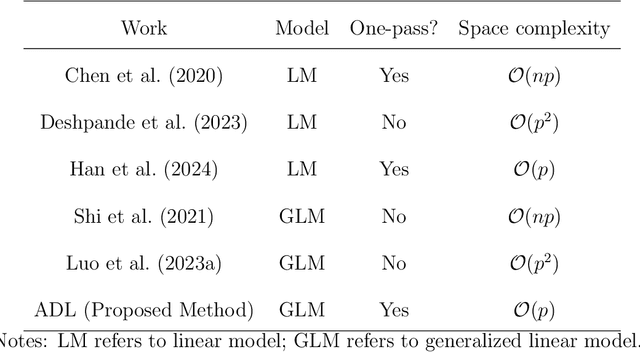
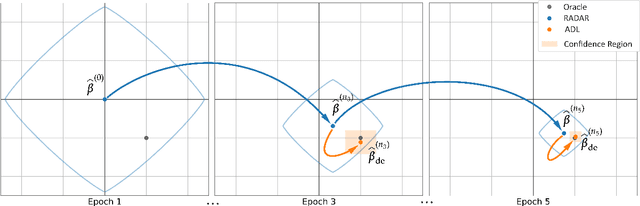

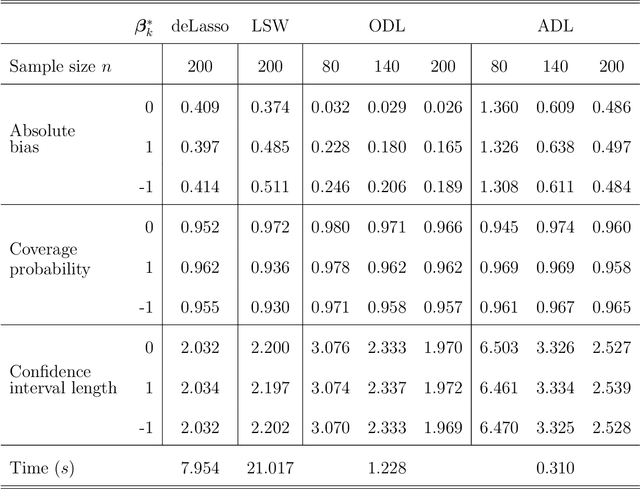
Online statistical inference facilitates real-time analysis of sequentially collected data, making it different from traditional methods that rely on static datasets. This paper introduces a novel approach to online inference in high-dimensional generalized linear models, where we update regression coefficient estimates and their standard errors upon each new data arrival. In contrast to existing methods that either require full dataset access or large-dimensional summary statistics storage, our method operates in a single-pass mode, significantly reducing both time and space complexity. The core of our methodological innovation lies in an adaptive stochastic gradient descent algorithm tailored for dynamic objective functions, coupled with a novel online debiasing procedure. This allows us to maintain low-dimensional summary statistics while effectively controlling optimization errors introduced by the dynamically changing loss functions. We demonstrate that our method, termed the Approximated Debiased Lasso (ADL), not only mitigates the need for the bounded individual probability condition but also significantly improves numerical performance. Numerical experiments demonstrate that the proposed ADL method consistently exhibits robust performance across various covariance matrix structures.
MuSE-ing on the Impact of Utterance Ordering On Crowdsourced Emotion Annotations
Mar 27, 2019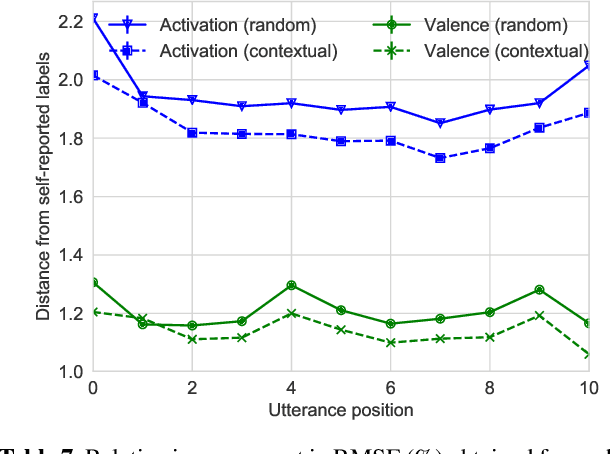
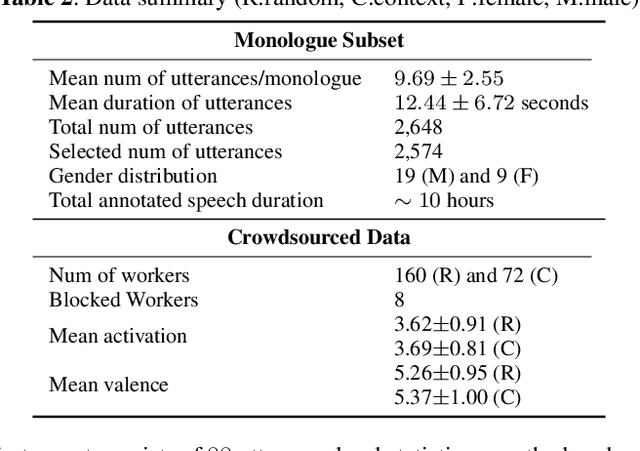

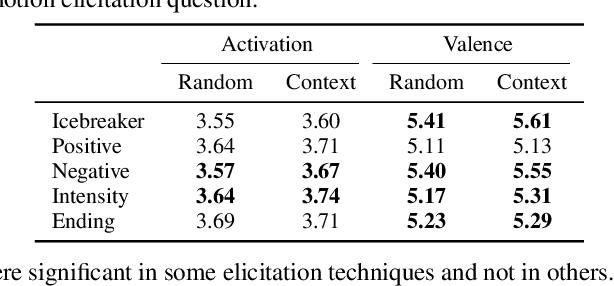
Emotion recognition algorithms rely on data annotated with high quality labels. However, emotion expression and perception are inherently subjective. There is generally not a single annotation that can be unambiguously declared "correct". As a result, annotations are colored by the manner in which they were collected. In this paper, we conduct crowdsourcing experiments to investigate this impact on both the annotations themselves and on the performance of these algorithms. We focus on one critical question: the effect of context. We present a new emotion dataset, Multimodal Stressed Emotion (MuSE), and annotate the dataset using two conditions: randomized, in which annotators are presented with clips in random order, and contextualized, in which annotators are presented with clips in order. We find that contextual labeling schemes result in annotations that are more similar to a speaker's own self-reported labels and that labels generated from randomized schemes are most easily predictable by automated systems.