 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Collaborative Plan Acquisition through Theory of Mind Modeling in Situated Dialogue
May 18, 2023



Collaborative tasks often begin with partial task knowledge and incomplete initial plans from each partner. To complete these tasks, agents need to engage in situated communication with their partners and coordinate their partial plans towards a complete plan to achieve a joint task goal. While such collaboration seems effortless in a human-human team, it is highly challenging for human-AI collaboration. To address this limitation, this paper takes a step towards collaborative plan acquisition, where humans and agents strive to learn and communicate with each other to acquire a complete plan for joint tasks. Specifically, we formulate a novel problem for agents to predict the missing task knowledge for themselves and for their partners based on rich perceptual and dialogue history. We extend a situated dialogue benchmark for symmetric collaborative tasks in a 3D blocks world and investigate computational strategies for plan acquisition. Our empirical results suggest that predicting the partner's missing knowledge is a more viable approach than predicting one's own. We show that explicit modeling of the partner's dialogue moves and mental states produces improved and more stable results than without. These results provide insight for future AI agents that can predict what knowledge their partner is missing and, therefore, can proactively communicate such information to help their partner acquire such missing knowledge toward a common understanding of joint tasks.
DOROTHIE: Spoken Dialogue for Handling Unexpected Situations in Interactive Autonomous Driving Agents
Oct 22, 2022



In the real world, autonomous driving agents navigate in highly dynamic environments full of unexpected situations where pre-trained models are unreliable. In these situations, what is immediately available to vehicles is often only human operators. Empowering autonomous driving agents with the ability to navigate in a continuous and dynamic environment and to communicate with humans through sensorimotor-grounded dialogue becomes critical. To this end, we introduce Dialogue On the ROad To Handle Irregular Events (DOROTHIE), a novel interactive simulation platform that enables the creation of unexpected situations on the fly to support empirical studies on situated communication with autonomous driving agents. Based on this platform, we created the Situated Dialogue Navigation (SDN), a navigation benchmark of 183 trials with a total of 8415 utterances, around 18.7 hours of control streams, and 2.9 hours of trimmed audio. SDN is developed to evaluate the agent's ability to predict dialogue moves from humans as well as generate its own dialogue moves and physical navigation actions. We further developed a transformer-based baseline model for these SDN tasks. Our empirical results indicate that language guided-navigation in a highly dynamic environment is an extremely difficult task for end-to-end models. These results will provide insight towards future work on robust autonomous driving agents. The DOROTHIE platform, SDN benchmark, and code for the baseline model are available at https://github.com/sled-group/DOROTHIE.
Privacy Preserving Visual Question Answering
Feb 15, 2022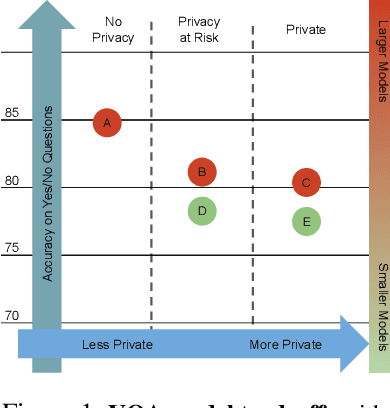

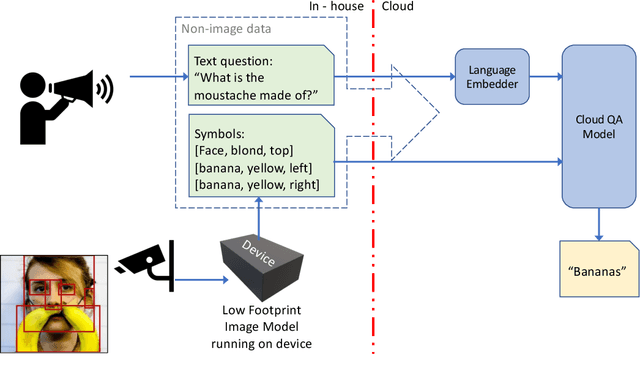

We introduce a novel privacy-preserving methodology for performing Visual Question Answering on the edge. Our method constructs a symbolic representation of the visual scene, using a low-complexity computer vision model that jointly predicts classes, attributes and predicates. This symbolic representation is non-differentiable, which means it cannot be used to recover the original image, thereby keeping the original image private. Our proposed hybrid solution uses a vision model which is more than 25 times smaller than the current state-of-the-art (SOTA) vision models, and 100 times smaller than end-to-end SOTA VQA models. We report detailed error analysis and discuss the trade-offs of using a distilled vision model and a symbolic representation of the visual scene.
MindCraft: Theory of Mind Modeling for Situated Dialogue in Collaborative Tasks
Sep 13, 2021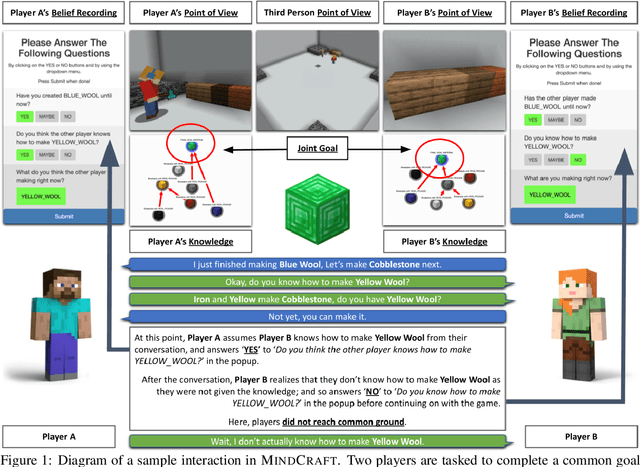
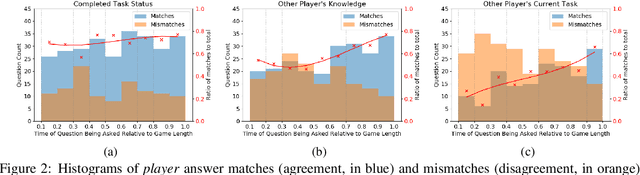
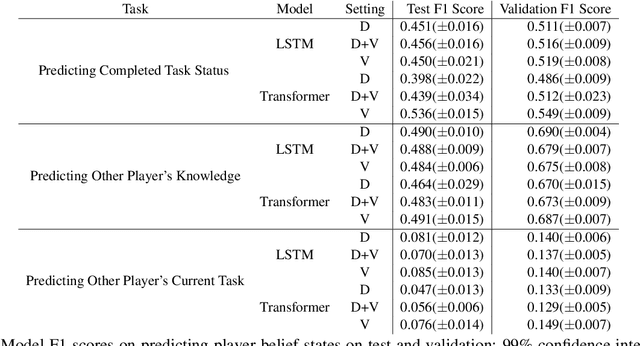
An ideal integration of autonomous agents in a human world implies that they are able to collaborate on human terms. In particular, theory of mind plays an important role in maintaining common ground during human collaboration and communication. To enable theory of mind modeling in situated interactions, we introduce a fine-grained dataset of collaborative tasks performed by pairs of human subjects in the 3D virtual blocks world of Minecraft. It provides information that captures partners' beliefs of the world and of each other as an interaction unfolds, bringing abundant opportunities to study human collaborative behaviors in situated language communication. As a first step towards our goal of developing embodied AI agents able to infer belief states of collaborative partners in situ, we build and present results on computational models for several theory of mind tasks.
MuSE-ing on the Impact of Utterance Ordering On Crowdsourced Emotion Annotations
Mar 27, 2019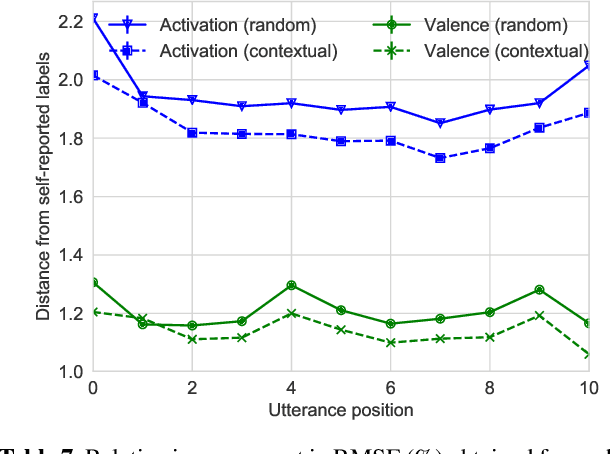
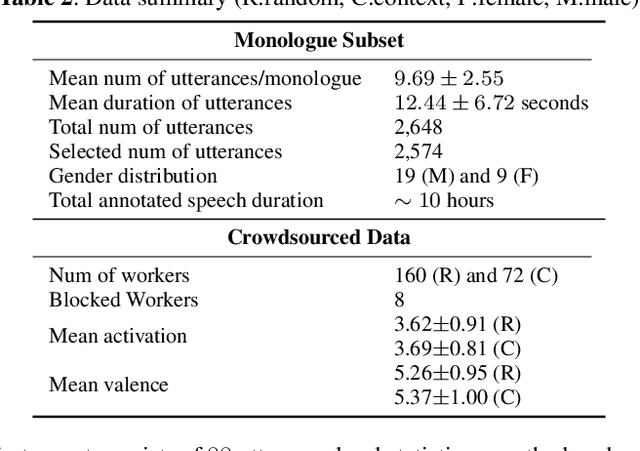

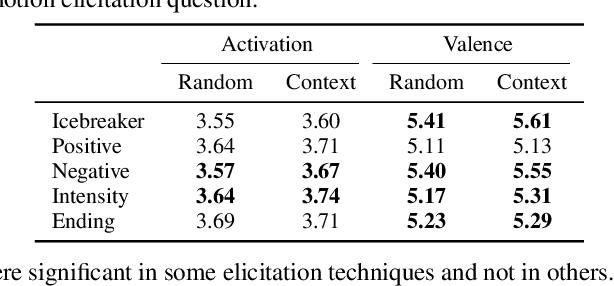
Emotion recognition algorithms rely on data annotated with high quality labels. However, emotion expression and perception are inherently subjective. There is generally not a single annotation that can be unambiguously declared "correct". As a result, annotations are colored by the manner in which they were collected. In this paper, we conduct crowdsourcing experiments to investigate this impact on both the annotations themselves and on the performance of these algorithms. We focus on one critical question: the effect of context. We present a new emotion dataset, Multimodal Stressed Emotion (MuSE), and annotate the dataset using two conditions: randomized, in which annotators are presented with clips in random order, and contextualized, in which annotators are presented with clips in order. We find that contextual labeling schemes result in annotations that are more similar to a speaker's own self-reported labels and that labels generated from randomized schemes are most easily predictable by automated systems.