 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Visual Recognition with Batch Confusion Norm
Oct 28, 2019
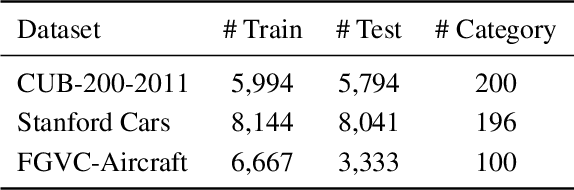
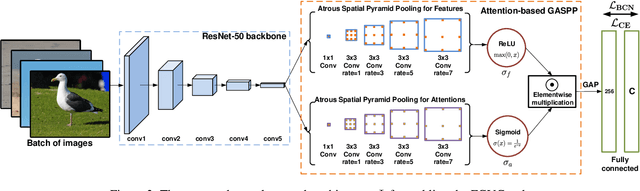
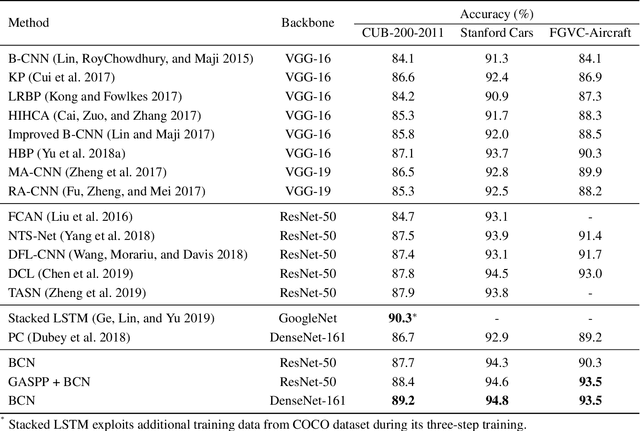
We introduce a regularization concept based on the proposed Batch Confusion Norm (BCN) to address Fine-Grained Visual Classification (FGVC). The FGVC problem is notably characterized by its two intriguing properties, significant inter-class similarity and intra-class variations, which cause learning an effective FGVC classifier a challenging task. Inspired by the use of pairwise confusion energy as a regularization mechanism, we develop the BCN technique to improve the FGVC learning by imposing class prediction confusion on each training batch, and consequently alleviate the possible overfitting due to exploring image feature of fine details. In addition, our method is implemented with an attention gated CNN model, boosted by the incorporation of Atrous Spatial Pyramid Pooling (ASPP) to extract discriminative features and proper attentions. To demonstrate the usefulness of our method, we report state-of-the-art results on several benchmark FGVC datasets, along with comprehensive ablation comparisons.
Instance-Level Meta Normalization
Apr 06, 2019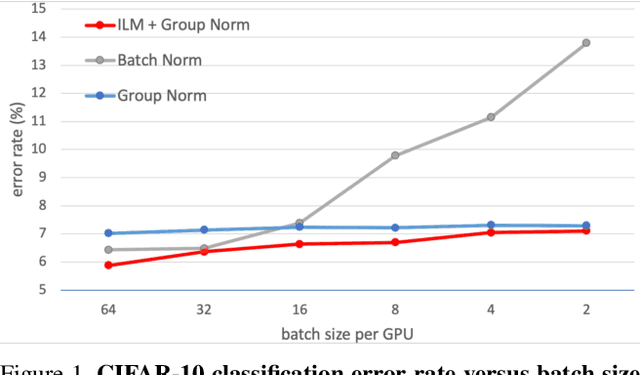

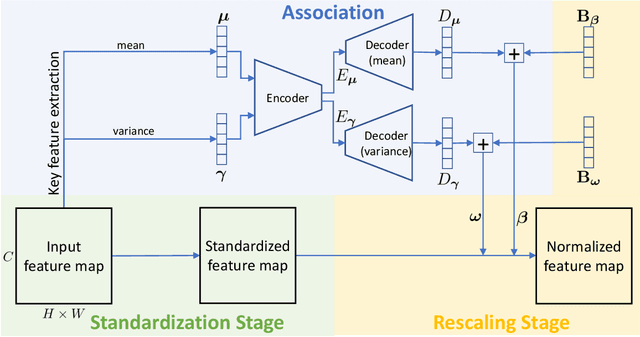
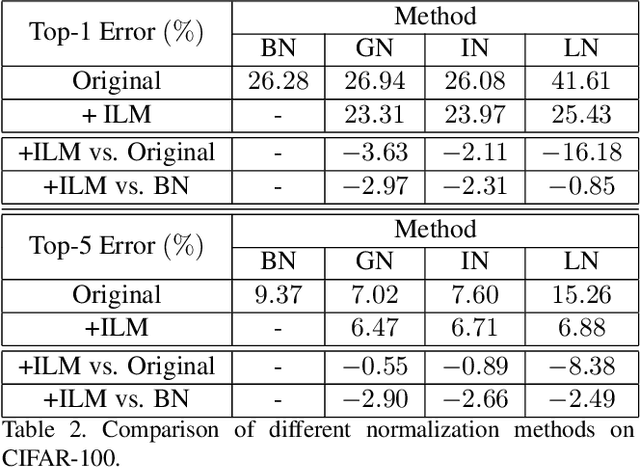
This paper presents a normalization mechanism called Instance-Level Meta Normalization (ILM~Norm) to address a learning-to-normalize problem. ILM~Norm learns to predict the normalization parameters via both the feature feed-forward and the gradient back-propagation paths. ILM~Norm provides a meta normalization mechanism and has several good properties. It can be easily plugged into existing instance-level normalization schemes such as Instance Normalization, Layer Normalization, or Group Normalization. ILM~Norm normalizes each instance individually and therefore maintains high performance even when small mini-batch is used. The experimental results show that ILM~Norm well adapts to different network architectures and tasks, and it consistently improves the performance of the original models. The code is available at url{https://github.com/Gasoonjia/ILM-Norm.
Unsupervised Meta-learning of Figure-Ground Segmentation via Imitating Visual Effects
Dec 20, 2018



This paper presents a "learning to learn" approach to figure-ground image segmentation. By exploring webly-abundant images of specific visual effects, our method can effectively learn the visual-effect internal representations in an unsupervised manner and uses this knowledge to differentiate the figure from the ground in an image. Specifically, we formulate the meta-learning process as a compositional image editing task that learns to imitate a certain visual effect and derive the corresponding internal representation. Such a generative process can help instantiate the underlying figure-ground notion and enables the system to accomplish the intended image segmentation. Whereas existing generative methods are mostly tailored to image synthesis or style transfer, our approach offers a flexible learning mechanism to model a general concept of figure-ground segmentation from unorganized images that have no explicit pixel-level annotations. We validate our approach via extensive experiments on six datasets to demonstrate that the proposed model can be end-to-end trained without ground-truth pixel labeling yet outperforms the existing methods of unsupervised segmentation tasks.
SwipeCut: Interactive Segmentation with Diversified Seed Proposals
Dec 18, 2018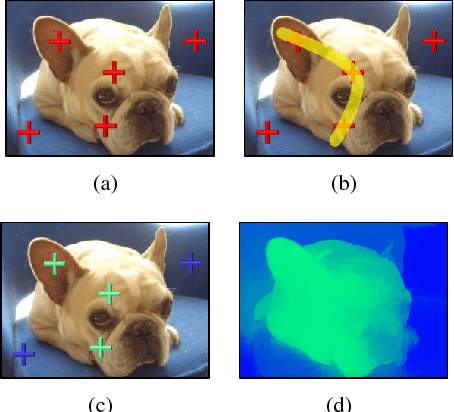

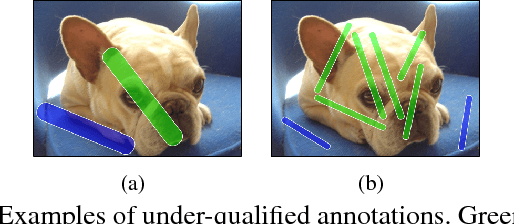

Interactive image segmentation algorithms rely on the user to provide annotations as the guidance. When the task of interactive segmentation is performed on a small touchscreen device, the requirement of providing precise annotations could be cumbersome to the user. We design an efficient seed proposal method that actively proposes annotation seeds for the user to label. The user only needs to check which ones of the query seeds are inside the region of interest (ROI). We enforce the sparsity and diversity criteria on the selection of the query seeds. At each round of interaction the user is only presented with a small number of informative query seeds that are far apart from each other. As a result, we are able to derive a user friendly interaction mechanism for annotation on small touchscreen devices. The user merely has to swipe through on the ROI-relevant query seeds, which should be easy since those gestures are commonly used on a touchscreen. The performance of our algorithm is evaluated on six publicly available datasets. The evaluation results show that our algorithm achieves high segmentation accuracy, with short response time and less user feedback.