 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Meta-learning of Figure-Ground Segmentation via Imitating Visual Effects
Dec 20, 2018



This paper presents a "learning to learn" approach to figure-ground image segmentation. By exploring webly-abundant images of specific visual effects, our method can effectively learn the visual-effect internal representations in an unsupervised manner and uses this knowledge to differentiate the figure from the ground in an image. Specifically, we formulate the meta-learning process as a compositional image editing task that learns to imitate a certain visual effect and derive the corresponding internal representation. Such a generative process can help instantiate the underlying figure-ground notion and enables the system to accomplish the intended image segmentation. Whereas existing generative methods are mostly tailored to image synthesis or style transfer, our approach offers a flexible learning mechanism to model a general concept of figure-ground segmentation from unorganized images that have no explicit pixel-level annotations. We validate our approach via extensive experiments on six datasets to demonstrate that the proposed model can be end-to-end trained without ground-truth pixel labeling yet outperforms the existing methods of unsupervised segmentation tasks.
Self Adversarial Training for Human Pose Estimation
Aug 15, 2017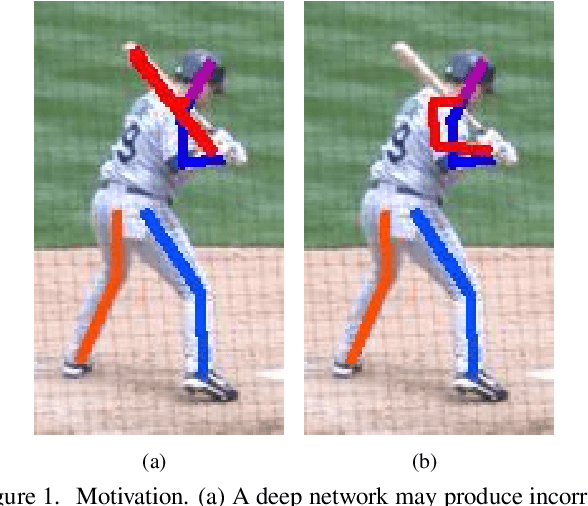
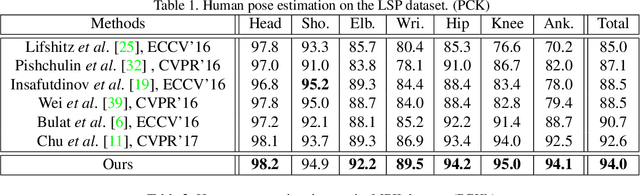
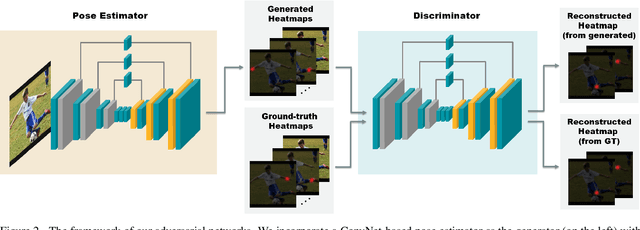

This paper presents a deep learning based approach to the problem of human pose estimation. We employ generative adversarial networks as our learning paradigm in which we set up two stacked hourglass networks with the same architecture, one as the generator and the other as the discriminator. The generator is used as a human pose estimator after the training is done. The discriminator distinguishes ground-truth heatmaps from generated ones, and back-propagates the adversarial loss to the generator. This process enables the generator to learn plausible human body configurations and is shown to be useful for improving the prediction accuracy.