 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Matching (MVM): Facilitating Multi-Person 3D Pose Estimation Learning with Action-Frozen People Video
Apr 11, 2020
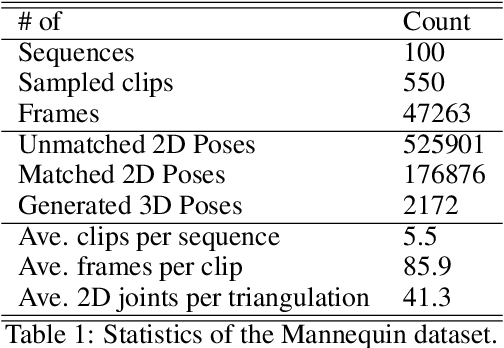
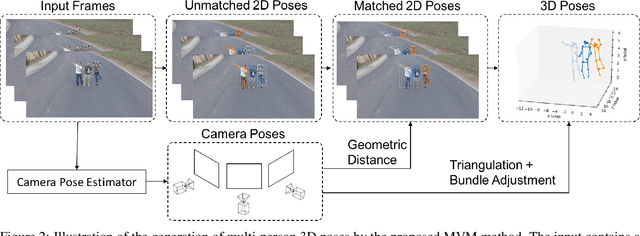

To tackle the challeging problem of multi-person 3D pose estimation from a single image, we propose a multi-view matching (MVM) method in this work. The MVM method generates reliable 3D human poses from a large-scale video dataset, called the Mannequin dataset, that contains action-frozen people immitating mannequins. With a large amount of in-the-wild video data labeled by 3D supervisions automatically generated by MVM, we are able to train a neural network that takes a single image as the input for multi-person 3D pose estimation. The core technology of MVM lies in effective alignment of 2D poses obtained from multiple views of a static scene that has a strong geometric constraint. Our objective is to maximize mutual consistency of 2D poses estimated in multiple frames, where geometric constraints as well as appearance similarities are taken into account simultaneously. To demonstrate the effectiveness of 3D supervisions provided by the MVM method, we conduct experiments on the 3DPW and the MSCOCO datasets and show that our proposed solution offers the state-of-the-art performance.
SPG-Net: Segmentation Prediction and Guidance Network for Image Inpainting
Aug 06, 2018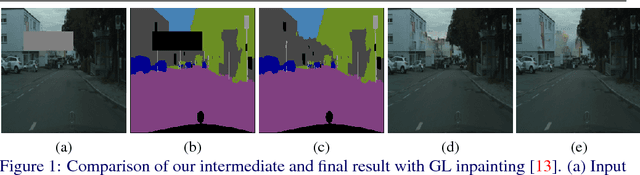
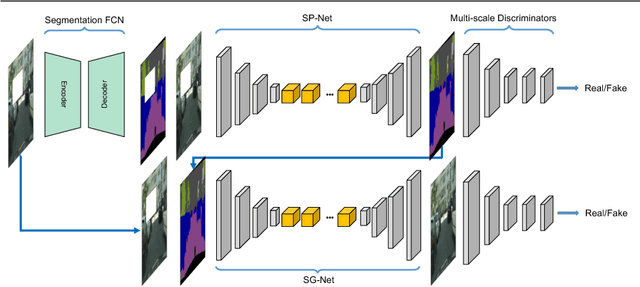


In this paper, we focus on image inpainting task, aiming at recovering the missing area of an incomplete image given the context information. Recent development in deep generative models enables an efficient end-to-end framework for image synthesis and inpainting tasks, but existing methods based on generative models don't exploit the segmentation information to constrain the object shapes, which usually lead to blurry results on the boundary. To tackle this problem, we propose to introduce the semantic segmentation information, which disentangles the inter-class difference and intra-class variation for image inpainting. This leads to much clearer recovered boundary between semantically different regions and better texture within semantically consistent segments. Our model factorizes the image inpainting process into segmentation prediction (SP-Net) and segmentation guidance (SG-Net) as two steps, which predict the segmentation labels in the missing area first, and then generate segmentation guided inpainting results. Experiments on multiple public datasets show that our approach outperforms existing methods in optimizing the image inpainting quality, and the interactive segmentation guidance provides possibilities for multi-modal predictions of image inpainting.