 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025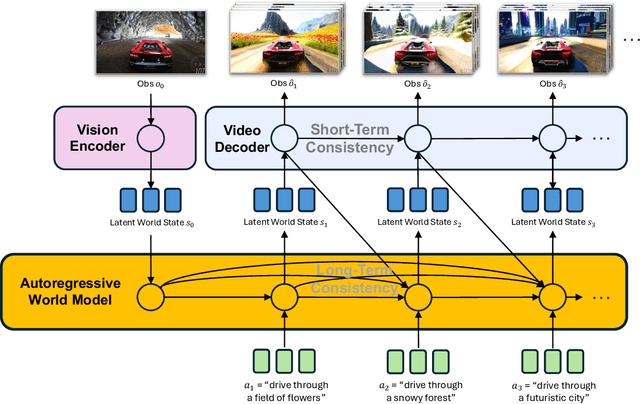
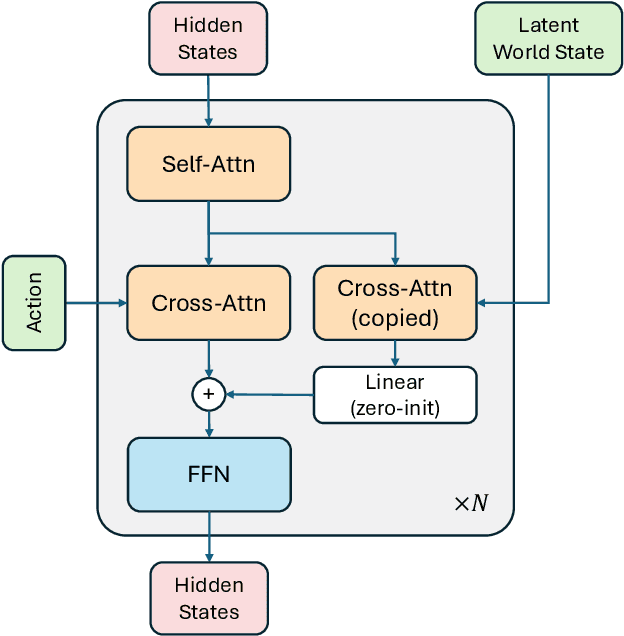
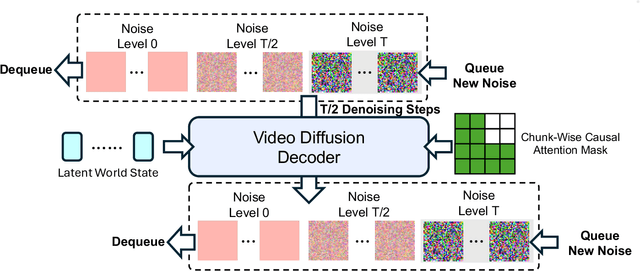
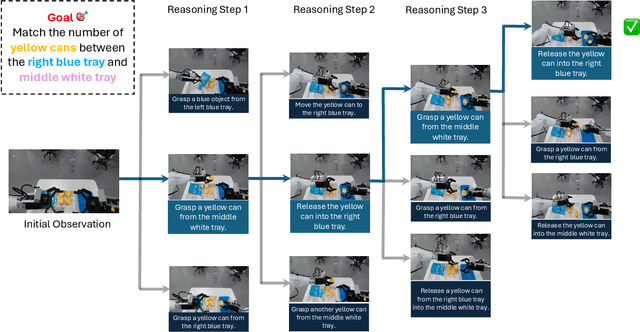
A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
Auto-Precision Scaling for Distributed Deep Learning
Nov 20, 2019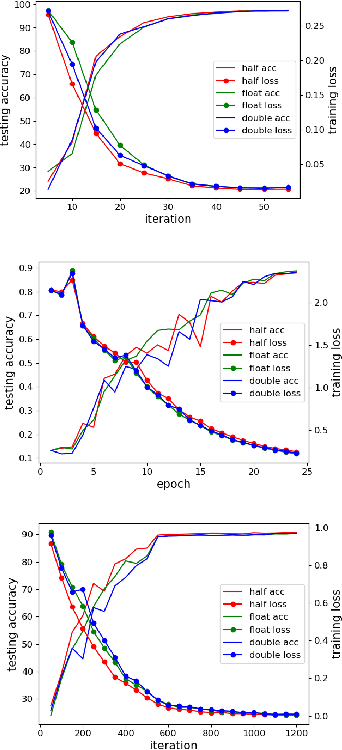
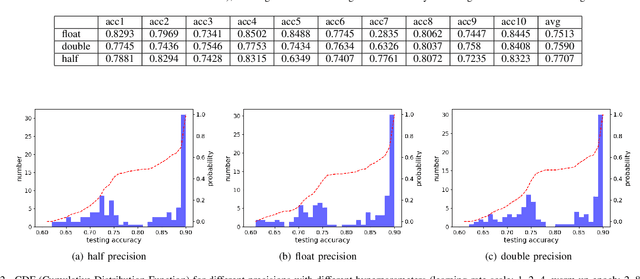
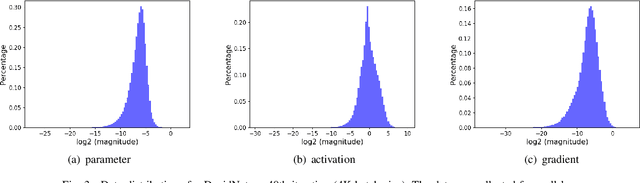

In recent years, large-batch optimization is becoming the key of distributed deep learning. However, large-batch optimization is hard. Straightforwardly porting the code often leads to a significant loss in testing accuracy. As some researchers suggested that large batch optimization leads to a low generalization performance, and they further conjectured that large-batch training needs a higher floating-point precision to achieve a higher generalization performance. To solve this problem, we conduct an open study in this paper. Our target is to find the number of bits that large-batch training needs. To do so, we need a system for customized precision study. However, state-of-the-art systems have some limitations that lower the efficiency of developers and researchers. To solve this problem, we design and implement our own system CPD: A High Performance System for Customized-Precision Distributed DL. In our experiments, our application often loses accuracy if we use a very-low precision (e.g. 8 bits or 4 bits). To solve this problem, we proposed the APS (Auto-Precision-Scaling) algorithm, which is a layer-wise adaptive scheme for gradients shifting. With APS, we are able to make the large-batch training converge with only 4 bits.