 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling the Network to Surf the Internet
Feb 24, 2021
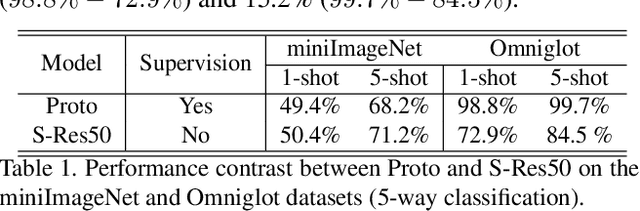

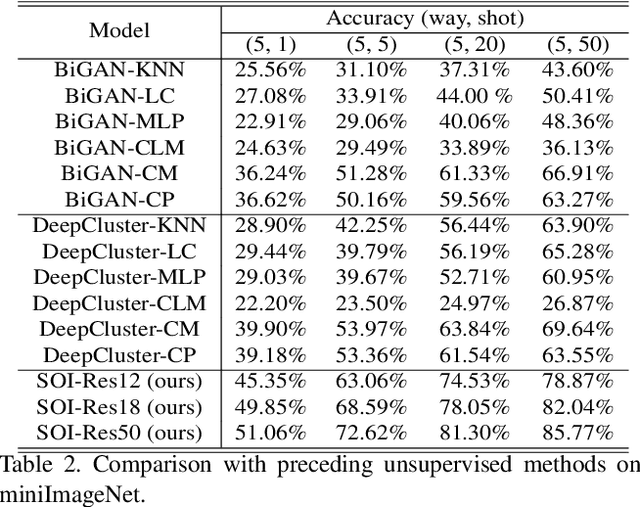
Few-shot learning is challenging due to the limited data and labels. Existing algorithms usually resolve this problem by pre-training the model with a considerable amount of annotated data which shares knowledge with the target domain. Nevertheless, large quantities of homogenous data samples are not always available. To tackle this issue, we develop a framework that enables the model to surf the Internet, which implies that the model can collect and annotate data without manual effort. Since the online data is virtually limitless and continues to be generated, the model can thus be empowered to constantly obtain up-to-date knowledge from the Internet. Additionally, we observe that the generalization ability of the learned representation is crucial for self-supervised learning. To present its importance, a naive yet efficient normalization strategy is proposed. Consequentially, this strategy boosts the accuracy of the model significantly (20.46% at most). We demonstrate the superiority of the proposed framework with experiments on miniImageNet, tieredImageNet and Omniglot. The results indicate that our method has surpassed previous unsupervised counterparts by a large margin (more than 10%) and obtained performance comparable with the supervised ones.