 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextArena
Apr 15, 2025
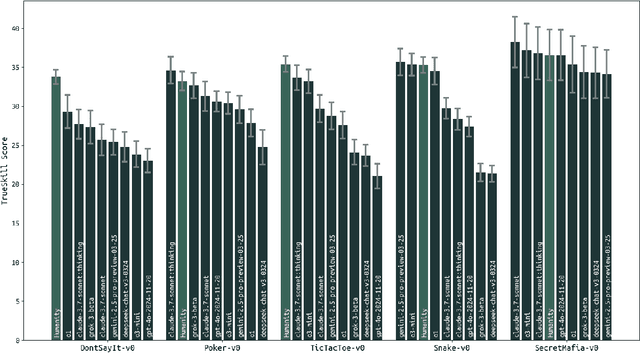
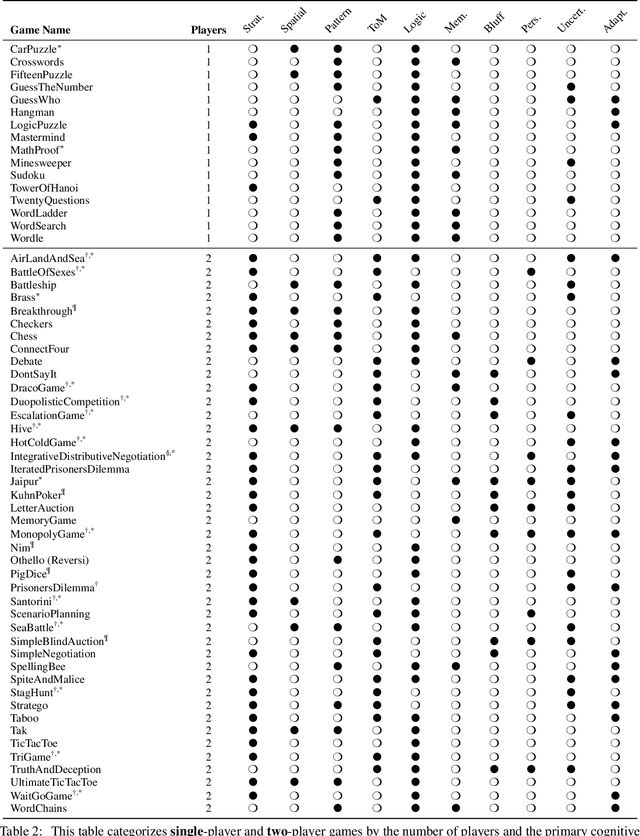

TextArena is an open-source collection of competitive text-based games for training and evaluation of agentic behavior in Large Language Models (LLMs). It spans 57+ unique environments (including single-player, two-player, and multi-player setups) and allows for easy evaluation of model capabilities via an online-play system (against humans and other submitted models) with real-time TrueSkill scores. Traditional benchmarks rarely assess dynamic social skills such as negotiation, theory of mind, and deception, creating a gap that TextArena addresses. Designed with research, community and extensibility in mind, TextArena emphasizes ease of adding new games, adapting the framework, testing models, playing against the models, and training models. Detailed documentation of environments, games, leaderboard, and examples are available on https://github.com/LeonGuertler/TextArena and https://www.textarena.ai/.
N2C2: Nearest Neighbor Enhanced Confidence Calibration for Cross-Lingual In-Context Learning
Mar 12, 2025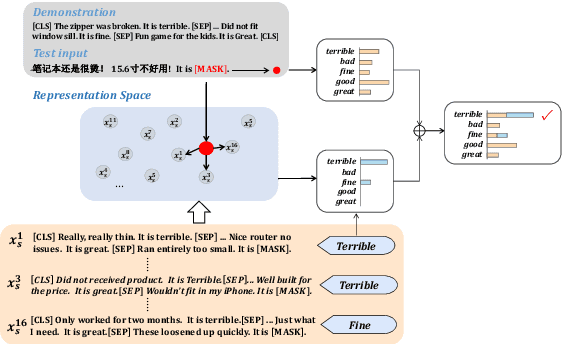
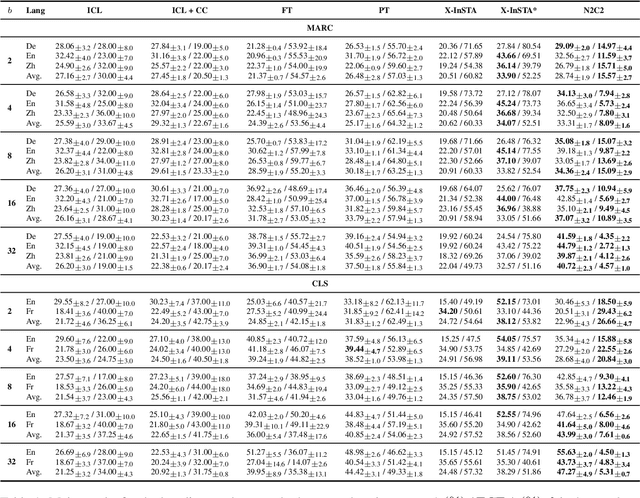
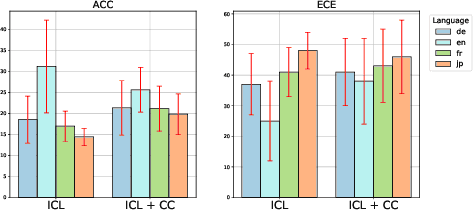
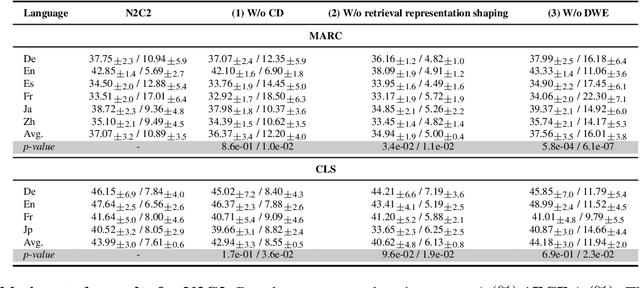
Recent advancements of in-context learning (ICL) show language models can significantly improve their performance when demonstrations are provided. However, little attention has been paid to model calibration and prediction confidence of ICL in cross-lingual scenarios. To bridge this gap, we conduct a thorough analysis of ICL for cross-lingual sentiment classification. Our findings suggest that ICL performs poorly in cross-lingual scenarios, exhibiting low accuracy and presenting high calibration errors. In response, we propose a novel approach, N2C2, which employs a -nearest neighbors augmented classifier for prediction confidence calibration. N2C2 narrows the prediction gap by leveraging a datastore of cached few-shot instances. Specifically, N2C2 integrates the predictions from the datastore and incorporates confidence-aware distribution, semantically consistent retrieval representation, and adaptive neighbor combination modules to effectively utilize the limited number of supporting instances. Evaluation on two multilingual sentiment classification datasets demonstrates that N2C2 outperforms traditional ICL. It surpasses fine tuning, prompt tuning and recent state-of-the-art methods in terms of accuracy and calibration errors.
Neural Probabilistic Circuits: Enabling Compositional and Interpretable Predictions through Logical Reasoning
Jan 13, 2025



End-to-end deep neural networks have achieved remarkable success across various domains but are often criticized for their lack of interpretability. While post hoc explanation methods attempt to address this issue, they often fail to accurately represent these black-box models, resulting in misleading or incomplete explanations. To overcome these challenges, we propose an inherently transparent model architecture called Neural Probabilistic Circuits (NPCs), which enable compositional and interpretable predictions through logical reasoning. In particular, an NPC consists of two modules: an attribute recognition model, which predicts probabilities for various attributes, and a task predictor built on a probabilistic circuit, which enables logical reasoning over recognized attributes to make class predictions. To train NPCs, we introduce a three-stage training algorithm comprising attribute recognition, circuit construction, and joint optimization. Moreover, we theoretically demonstrate that an NPC's error is upper-bounded by a linear combination of the errors from its modules. To further demonstrate the interpretability of NPC, we provide both the most probable explanations and the counterfactual explanations. Empirical results on four benchmark datasets show that NPCs strike a balance between interpretability and performance, achieving results competitive even with those of end-to-end black-box models while providing enhanced interpretability.
Diversify and Conquer: Diversity-Centric Data Selection with Iterative Refinement
Sep 17, 2024Finetuning large language models on instruction data is crucial for enhancing pre-trained knowledge and improving instruction-following capabilities. As instruction datasets proliferate, selecting optimal data for effective training becomes increasingly important. This work addresses the question: How can we determine the optimal subset of data for effective training? While existing research often emphasizes local criteria like instance quality for subset selection, we argue that a global approach focused on data diversity is more critical. Our method employs k-means clustering to ensure the selected subset effectively represents the full dataset. We propose an iterative refinement method inspired by active learning techniques to resample instances from clusters, reassessing each cluster's importance and sampling weight in every training iteration. This approach reduces the effect of outliers and automatically filters out clusters containing low-quality data. Through extensive evaluation across natural language reasoning, general world knowledge, code and math reasoning tasks, and by fine-tuning models from various families, we observe consistent improvements, achieving a 7% increase over random selection and a 3.8% improvement over state-of-the-art sampling methods. Our work highlights the significance of diversity-first sampling when finetuning LLMs to enhance performance across a broad array of evaluation tasks. Our code is available at https://github.com/for-ai/iterative-data-selection.
Is It Good Data for Multilingual Instruction Tuning or Just Bad Multilingual Evaluation for Large Language Models?
Jun 18, 2024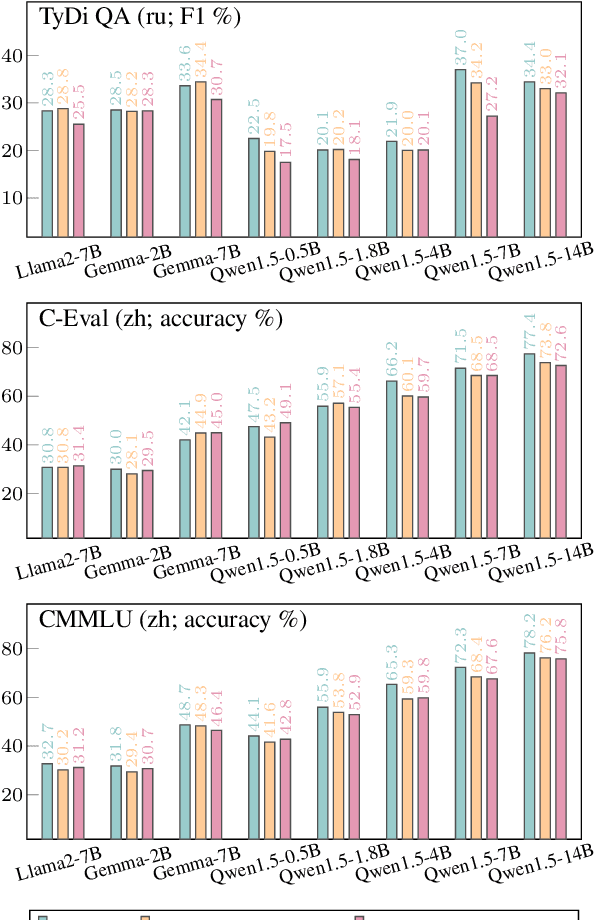
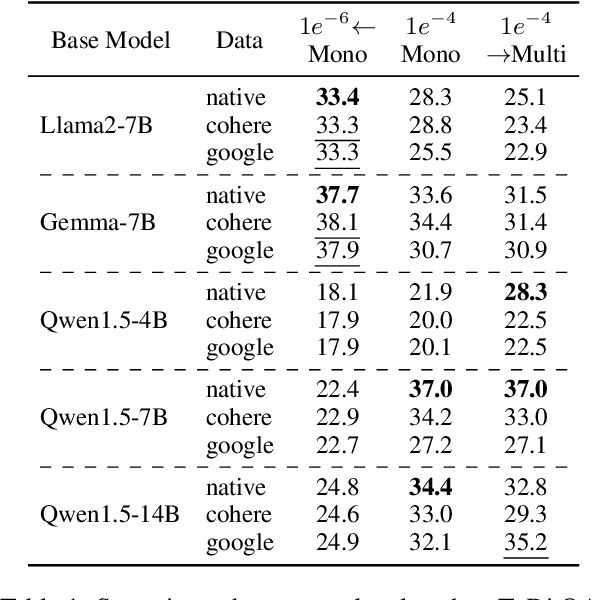
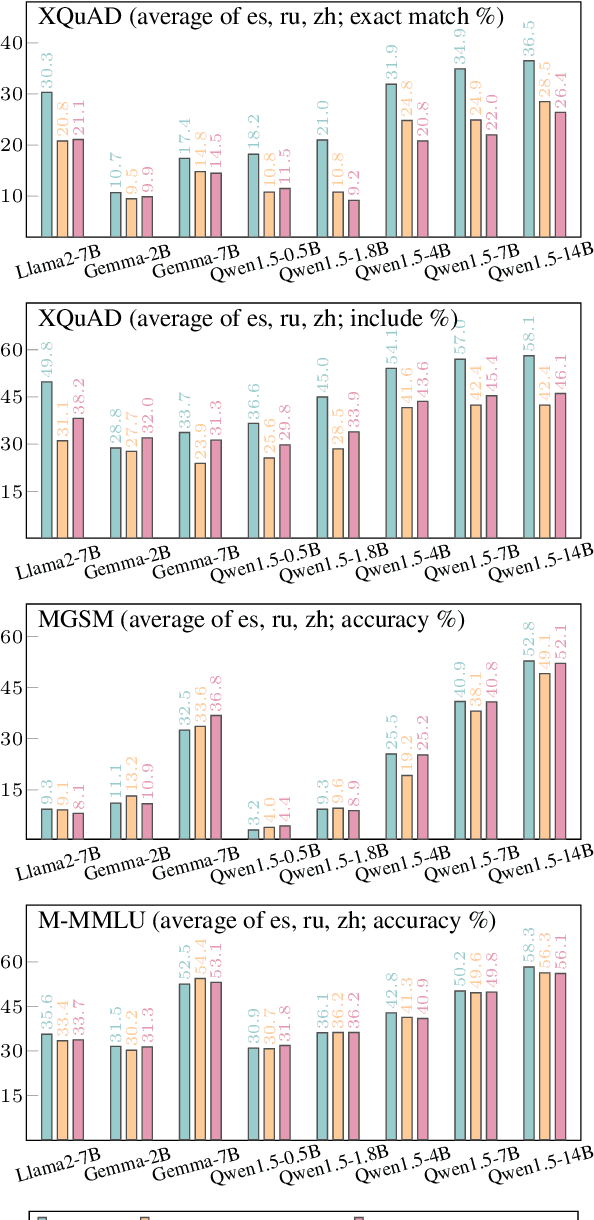
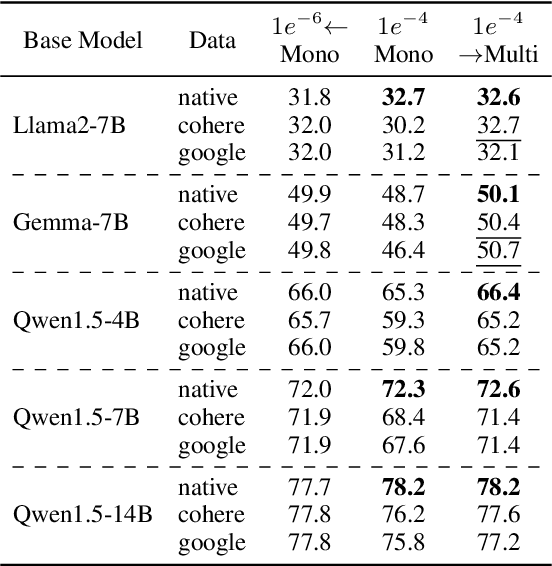
Large language models, particularly multilingual ones, are designed, claimed, and expected to cater to native speakers of varied languages. We hypothesise that the current practices of fine-tuning and evaluating these models may mismatch this intention owing to a heavy reliance on translation, which can introduce translation artefacts and defects. It remains unknown whether the nature of the instruction data has an impact on the model output; on the other hand, it remains questionable whether translated test sets can capture such nuances. Due to the often coupled practices of using translated data in both stages, such imperfections could have been overlooked. This work investigates these issues by using controlled native or translated data during instruction tuning and evaluation stages and observing model results. Experiments on eight base models and eight different benchmarks reveal that native or generation benchmarks display a notable difference between native and translated instruction data especially when model performance is high, whereas other types of test sets cannot. Finally, we demonstrate that regularization is beneficial to bridging this gap on structured but not generative tasks.
Voxel2Hemodynamics: An End-to-end Deep Learning Method for Predicting Coronary Artery Hemodynamics
May 30, 2023Local hemodynamic forces play an important role in determining the functional significance of coronary arterial stenosis and understanding the mechanism of coronary disease progression. Computational fluid dynamics (CFD) have been widely performed to simulate hemodynamics non-invasively from coronary computed tomography angiography (CCTA) images. However, accurate computational analysis is still limited by the complex construction of patient-specific modeling and time-consuming computation. In this work, we proposed an end-to-end deep learning framework, which could predict the coronary artery hemodynamics from CCTA images. The model was trained on the hemodynamic data obtained from 3D simulations of synthetic and real datasets. Extensive experiments demonstrated that the predicted hemdynamic distributions by our method agreed well with the CFD-derived results. Quantitatively, the proposed method has the capability of predicting the fractional flow reserve with an average error of 0.5\% and 2.5\% for the synthetic dataset and real dataset, respectively. Particularly, our method achieved much better accuracy for the real dataset compared to PointNet++ with the point cloud input. This study demonstrates the feasibility and great potential of our end-to-end deep learning method as a fast and accurate approach for hemodynamic analysis.
Segmentation and Vascular Vectorization for Coronary Artery by Geometry-based Cascaded Neural Network
May 07, 2023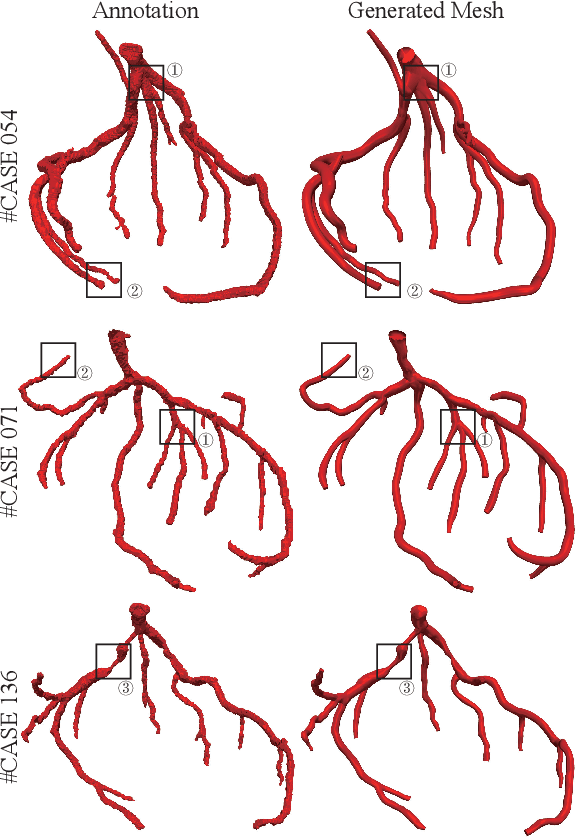
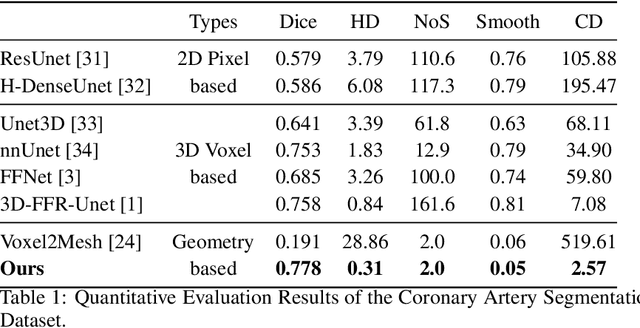
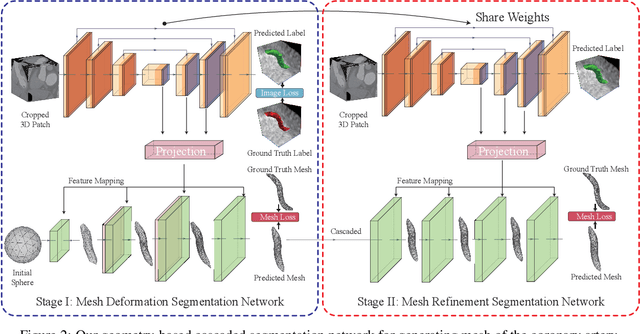

Segmentation of the coronary artery is an important task for the quantitative analysis of coronary computed tomography angiography (CCTA) images and is being stimulated by the field of deep learning. However, the complex structures with tiny and narrow branches of the coronary artery bring it a great challenge. Coupled with the medical image limitations of low resolution and poor contrast, fragmentations of segmented vessels frequently occur in the prediction. Therefore, a geometry-based cascaded segmentation method is proposed for the coronary artery, which has the following innovations: 1) Integrating geometric deformation networks, we design a cascaded network for segmenting the coronary artery and vectorizing results. The generated meshes of the coronary artery are continuous and accurate for twisted and sophisticated coronary artery structures, without fragmentations. 2) Different from mesh annotations generated by the traditional marching cube method from voxel-based labels, a finer vectorized mesh of the coronary artery is reconstructed with the regularized morphology. The novel mesh annotation benefits the geometry-based segmentation network, avoiding bifurcation adhesion and point cloud dispersion in intricate branches. 3) A dataset named CCA-200 is collected, consisting of 200 CCTA images with coronary artery disease. The ground truths of 200 cases are coronary internal diameter annotations by professional radiologists. Extensive experiments verify our method on our collected dataset CCA-200 and public ASOCA dataset, with a Dice of 0.778 on CCA-200 and 0.895 on ASOCA, showing superior results. Especially, our geometry-based model generates an accurate, intact and smooth coronary artery, devoid of any fragmentations of segmented vessels.
Synergistic Redundancy: Towards Verifiable Safety for Autonomous Vehicles
Sep 04, 2022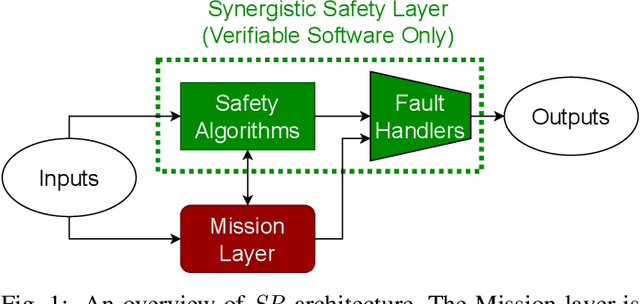

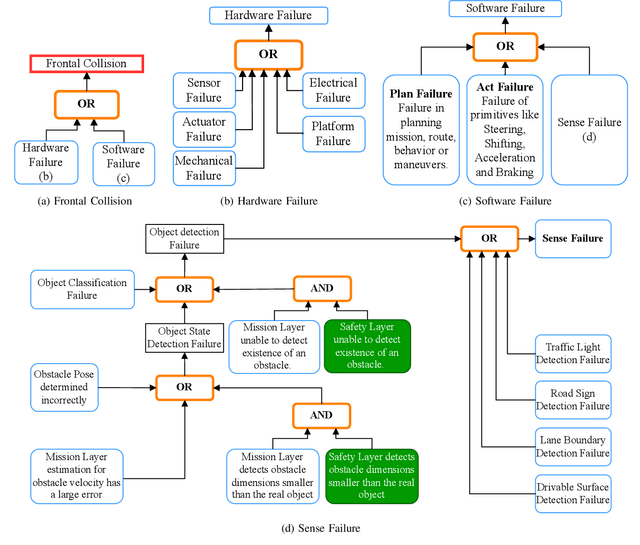
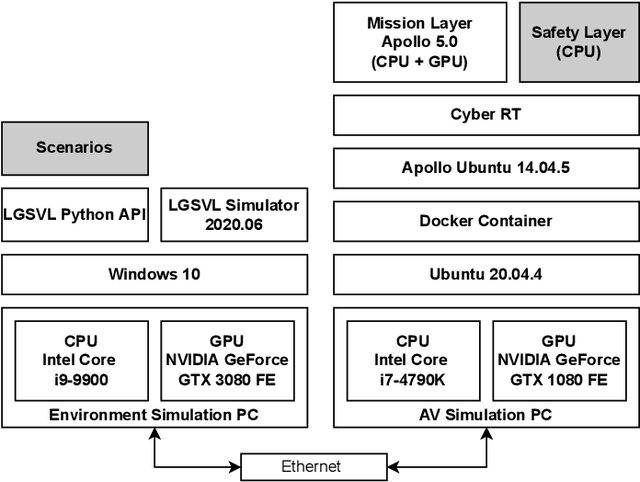
As Autonomous Vehicle (AV) development has progressed, concerns regarding the safety of passengers and agents in their environment have risen. Each real world traffic collision involving autonomously controlled vehicles has compounded this concern. Open source autonomous driving implementations show a software architecture with complex interdependent tasks, heavily reliant on machine learning and Deep Neural Networks (DNN), which are vulnerable to non deterministic faults and corner cases. These complex subsystems work together to fulfill the mission of the AV while also maintaining safety. Although significant improvements are being made towards increasing the empirical reliability and confidence in these systems, the inherent limitations of DNN verification create an, as yet, insurmountable challenge in providing deterministic safety guarantees in AV. We propose Synergistic Redundancy (SR), a safety architecture for complex cyber physical systems, like AV. SR provides verifiable safety guarantees against specific faults by decoupling the mission and safety tasks of the system. Simultaneous to independently fulfilling their primary roles, the partially functionally redundant mission and safety tasks are able to aid each other, synergistically improving the combined system. The synergistic safety layer uses only verifiable and logically analyzable software to fulfill its tasks. Close coordination with the mission layer allows easier and early detection of safety critical faults in the system. SR simplifies the mission layer's optimization goals and improves its design. SR provides safe deployment of high performance, although inherently unverifiable, machine learning software. In this work, we first present the design and features of the SR architecture and then evaluate the efficacy of the solution, focusing on the crucial problem of obstacle existence detection faults in AV.
Verifiable Obstacle Detection
Aug 30, 2022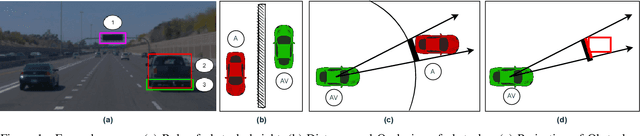
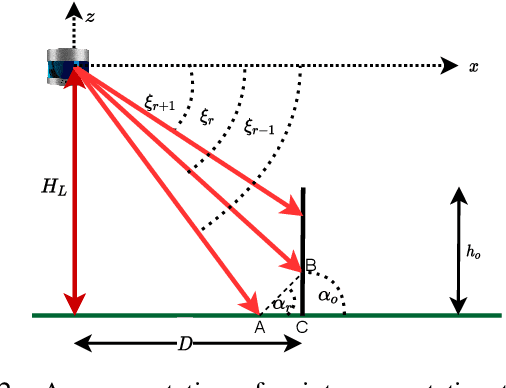
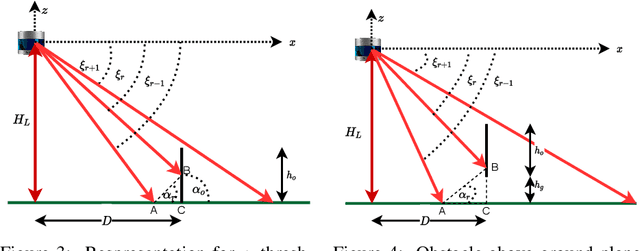
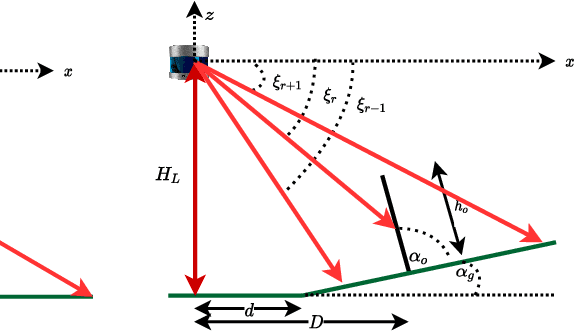
Perception of obstacles remains a critical safety concern for autonomous vehicles. Real-world collisions have shown that the autonomy faults leading to fatal collisions originate from obstacle existence detection. Open source autonomous driving implementations show a perception pipeline with complex interdependent Deep Neural Networks. These networks are not fully verifiable, making them unsuitable for safety-critical tasks. In this work, we present a safety verification of an existing LiDAR based classical obstacle detection algorithm. We establish strict bounds on the capabilities of this obstacle detection algorithm. Given safety standards, such bounds allow for determining LiDAR sensor properties that would reliably satisfy the standards. Such analysis has as yet been unattainable for neural network based perception systems. We provide a rigorous analysis of the obstacle detection system with empirical results based on real-world sensor data.
LiDAR Cluster First and Camera Inference Later: A New Perspective Towards Autonomous Driving
Nov 19, 2021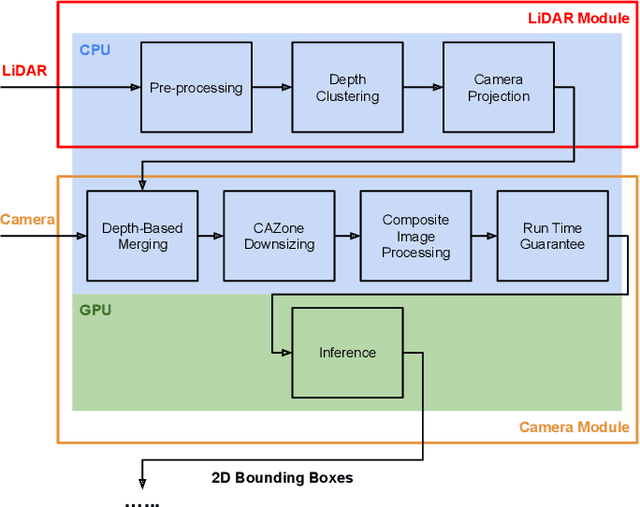
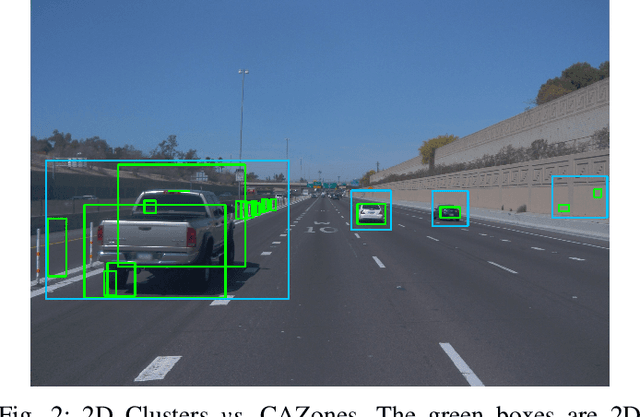
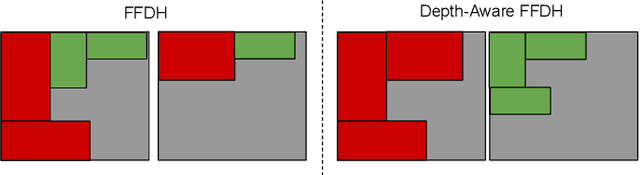

Object detection in state-of-the-art Autonomous Vehicles (AV) framework relies heavily on deep neural networks. Typically, these networks perform object detection uniformly on the entire camera LiDAR frames. However, this uniformity jeopardizes the safety of the AV by giving the same priority to all objects in the scenes regardless of their risk of collision to the AV. In this paper, we present a new end-to-end pipeline for AV that introduces the concept of LiDAR cluster first and camera inference later to detect and classify objects. The benefits of our proposed framework are twofold. First, our pipeline prioritizes detecting objects that pose a higher risk of collision to the AV, giving more time for the AV to react to unsafe conditions. Second, it also provides, on average, faster inference speeds compared to popular deep neural network pipelines. We design our framework using the real-world datasets, the Waymo Open Dataset, solving challenges arising from the limitations of LiDAR sensors and object detection algorithms. We show that our novel object detection pipeline prioritizes the detection of higher risk objects while simultaneously achieving comparable accuracy and a 25% higher average speed compared to camera inference only.