 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Image Contrastive Learning for Efficient Visual Conceptual Pre-training
Nov 15, 2024This paper proposes a scalable and straightforward pre-training paradigm for efficient visual conceptual representation called masked image contrastive learning (MiCL). Our MiCL approach is simple: we randomly mask patches to generate different views within an image and contrast them among a mini-batch of images. The core idea behind MiCL consists of two designs. First, masked tokens have the potential to significantly diminish the conceptual redundancy inherent in images, and create distinct views with substantial fine-grained differences on the semantic concept level instead of the instance level. Second, contrastive learning is adept at extracting high-level semantic conceptual features during the pre-training, circumventing the high-frequency interference and additional costs associated with image reconstruction. Importantly, MiCL learns highly semantic conceptual representations efficiently without relying on hand-crafted data augmentations or additional auxiliary modules. Empirically, MiCL demonstrates high scalability with Vision Transformers, as the ViT-L/16 can complete pre-training in 133 hours using only 4 A100 GPUs, achieving 85.8% accuracy in downstream fine-tuning tasks.
A foundation model for generalizable disease diagnosis in chest X-ray images
Oct 11, 2024Medical artificial intelligence (AI) is revolutionizing the interpretation of chest X-ray (CXR) images by providing robust tools for disease diagnosis. However, the effectiveness of these AI models is often limited by their reliance on large amounts of task-specific labeled data and their inability to generalize across diverse clinical settings. To address these challenges, we introduce CXRBase, a foundational model designed to learn versatile representations from unlabelled CXR images, facilitating efficient adaptation to various clinical tasks. CXRBase is initially trained on a substantial dataset of 1.04 million unlabelled CXR images using self-supervised learning methods. This approach allows the model to discern meaningful patterns without the need for explicit labels. After this initial phase, CXRBase is fine-tuned with labeled data to enhance its performance in disease detection, enabling accurate classification of chest diseases. CXRBase provides a generalizable solution to improve model performance and alleviate the annotation workload of experts to enable broad clinical AI applications from chest imaging.
MedViLaM: A multimodal large language model with advanced generalizability and explainability for medical data understanding and generation
Sep 29, 2024



Medicine is inherently multimodal and multitask, with diverse data modalities spanning text, imaging. However, most models in medical field are unimodal single tasks and lack good generalizability and explainability. In this study, we introduce MedViLaM, a unified vision-language model towards a generalist model for medical data that can flexibly encode and interpret various forms of medical data, including clinical language and imaging, all using the same set of model weights. To facilitate the creation of such multi-task model, we have curated MultiMedBench, a comprehensive pretaining dataset and benchmark consisting of several distinct tasks, i.e., continuous question-answering, multi-label disease classification, disease localization, generation and summarization of radiology reports. MedViLaM demonstrates strong performance across all MultiMedBench tasks, frequently outpacing other generalist models by a significant margin. Additionally, we present instances of zero-shot generalization to new medical concepts and tasks, effective transfer learning across different tasks, and the emergence of zero-shot medical reasoning.
ViLaM: A Vision-Language Model with Enhanced Visual Grounding and Generalization Capability
Nov 21, 2023Vision-language models have revolutionized human-computer interaction and shown significant progress in multi-modal tasks. However, applying these models to complex visual tasks like medical image analysis remains challenging. In this study, we propose ViLaM, a unified Vision-Language transformer model that integrates instruction tuning predicated on a large language model. This approach enables us to optimally utilize the knowledge and reasoning capacities of large pre-trained language models for an array of tasks encompassing both language and vision. We employ frozen pre-trained encoders to encode and align both image and text features, enabling ViLaM to handle a variety of visual tasks following textual instructions. Besides, we've designed cycle training for referring expressions to address the need for high-quality, paired referring expression datasets for training large models in terms of both quantity and quality. We evaluated ViLaM's exceptional performance on public general datasets and further confirmed its generalizability on medical datasets. Importantly, we've observed the model's impressive zero-shot learning ability, indicating the potential future application of ViLaM in the medical field.
Learning A Multi-Task Transformer Via Unified And Customized Instruction Tuning For Chest Radiograph Interpretation
Nov 02, 2023The emergence of multi-modal deep learning models has made significant impacts on clinical applications in the last decade. However, the majority of models are limited to single-tasking, without considering disease diagnosis is indeed a multi-task procedure. Here, we demonstrate a unified transformer model specifically designed for multi-modal clinical tasks by incorporating customized instruction tuning. We first compose a multi-task training dataset comprising 13.4 million instruction and ground-truth pairs (with approximately one million radiographs) for the customized tuning, involving both image- and pixel-level tasks. Thus, we can unify the various vision-intensive tasks in a single training framework with homogeneous model inputs and outputs to increase clinical interpretability in one reading. Finally, we demonstrate the overall superior performance of our model compared to prior arts on various chest X-ray benchmarks across multi-tasks in both direct inference and finetuning settings. Three radiologists further evaluate the generated reports against the recorded ones, which also exhibit the enhanced explainability of our multi-task model.
Voxel2Hemodynamics: An End-to-end Deep Learning Method for Predicting Coronary Artery Hemodynamics
May 30, 2023Local hemodynamic forces play an important role in determining the functional significance of coronary arterial stenosis and understanding the mechanism of coronary disease progression. Computational fluid dynamics (CFD) have been widely performed to simulate hemodynamics non-invasively from coronary computed tomography angiography (CCTA) images. However, accurate computational analysis is still limited by the complex construction of patient-specific modeling and time-consuming computation. In this work, we proposed an end-to-end deep learning framework, which could predict the coronary artery hemodynamics from CCTA images. The model was trained on the hemodynamic data obtained from 3D simulations of synthetic and real datasets. Extensive experiments demonstrated that the predicted hemdynamic distributions by our method agreed well with the CFD-derived results. Quantitatively, the proposed method has the capability of predicting the fractional flow reserve with an average error of 0.5\% and 2.5\% for the synthetic dataset and real dataset, respectively. Particularly, our method achieved much better accuracy for the real dataset compared to PointNet++ with the point cloud input. This study demonstrates the feasibility and great potential of our end-to-end deep learning method as a fast and accurate approach for hemodynamic analysis.
Segmentation and Vascular Vectorization for Coronary Artery by Geometry-based Cascaded Neural Network
May 07, 2023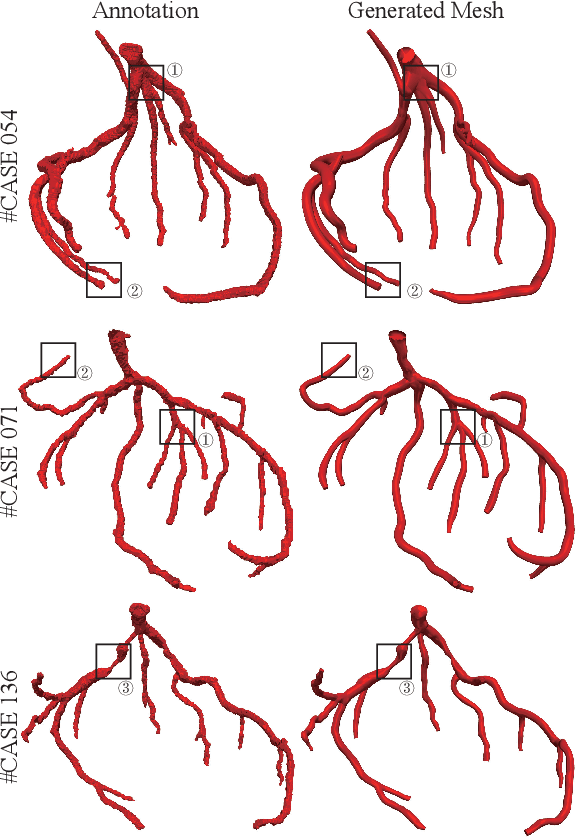
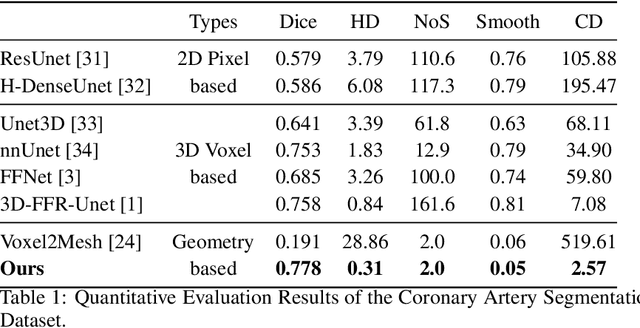
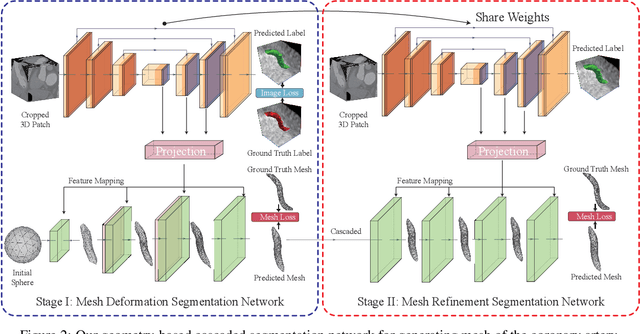

Segmentation of the coronary artery is an important task for the quantitative analysis of coronary computed tomography angiography (CCTA) images and is being stimulated by the field of deep learning. However, the complex structures with tiny and narrow branches of the coronary artery bring it a great challenge. Coupled with the medical image limitations of low resolution and poor contrast, fragmentations of segmented vessels frequently occur in the prediction. Therefore, a geometry-based cascaded segmentation method is proposed for the coronary artery, which has the following innovations: 1) Integrating geometric deformation networks, we design a cascaded network for segmenting the coronary artery and vectorizing results. The generated meshes of the coronary artery are continuous and accurate for twisted and sophisticated coronary artery structures, without fragmentations. 2) Different from mesh annotations generated by the traditional marching cube method from voxel-based labels, a finer vectorized mesh of the coronary artery is reconstructed with the regularized morphology. The novel mesh annotation benefits the geometry-based segmentation network, avoiding bifurcation adhesion and point cloud dispersion in intricate branches. 3) A dataset named CCA-200 is collected, consisting of 200 CCTA images with coronary artery disease. The ground truths of 200 cases are coronary internal diameter annotations by professional radiologists. Extensive experiments verify our method on our collected dataset CCA-200 and public ASOCA dataset, with a Dice of 0.778 on CCA-200 and 0.895 on ASOCA, showing superior results. Especially, our geometry-based model generates an accurate, intact and smooth coronary artery, devoid of any fragmentations of segmented vessels.