 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning A Multi-Task Transformer Via Unified And Customized Instruction Tuning For Chest Radiograph Interpretation
Nov 02, 2023The emergence of multi-modal deep learning models has made significant impacts on clinical applications in the last decade. However, the majority of models are limited to single-tasking, without considering disease diagnosis is indeed a multi-task procedure. Here, we demonstrate a unified transformer model specifically designed for multi-modal clinical tasks by incorporating customized instruction tuning. We first compose a multi-task training dataset comprising 13.4 million instruction and ground-truth pairs (with approximately one million radiographs) for the customized tuning, involving both image- and pixel-level tasks. Thus, we can unify the various vision-intensive tasks in a single training framework with homogeneous model inputs and outputs to increase clinical interpretability in one reading. Finally, we demonstrate the overall superior performance of our model compared to prior arts on various chest X-ray benchmarks across multi-tasks in both direct inference and finetuning settings. Three radiologists further evaluate the generated reports against the recorded ones, which also exhibit the enhanced explainability of our multi-task model.
MIS-FM: 3D Medical Image Segmentation using Foundation Models Pretrained on a Large-Scale Unannotated Dataset
Jun 29, 2023Pretraining with large-scale 3D volumes has a potential for improving the segmentation performance on a target medical image dataset where the training images and annotations are limited. Due to the high cost of acquiring pixel-level segmentation annotations on the large-scale pretraining dataset, pretraining with unannotated images is highly desirable. In this work, we propose a novel self-supervised learning strategy named Volume Fusion (VF) for pretraining 3D segmentation models. It fuses several random patches from a foreground sub-volume to a background sub-volume based on a predefined set of discrete fusion coefficients, and forces the model to predict the fusion coefficient of each voxel, which is formulated as a self-supervised segmentation task without manual annotations. Additionally, we propose a novel network architecture based on parallel convolution and transformer blocks that is suitable to be transferred to different downstream segmentation tasks with various scales of organs and lesions. The proposed model was pretrained with 110k unannotated 3D CT volumes, and experiments with different downstream segmentation targets including head and neck organs, thoracic/abdominal organs showed that our pretrained model largely outperformed training from scratch and several state-of-the-art self-supervised training methods and segmentation models. The code and pretrained model are available at https://github.com/openmedlab/MIS-FM.
One-shot Weakly-Supervised Segmentation in Medical Images
Nov 21, 2021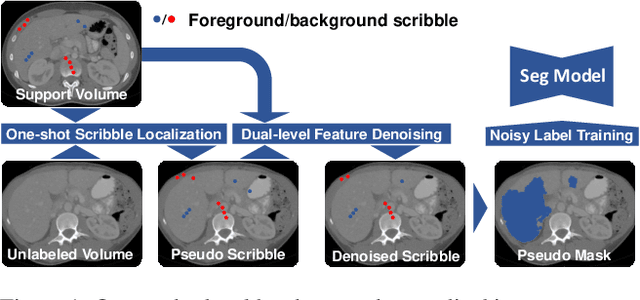

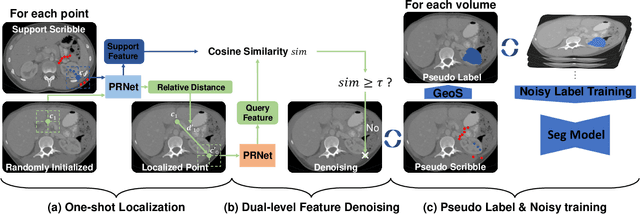

Deep neural networks usually require accurate and a large number of annotations to achieve outstanding performance in medical image segmentation. One-shot segmentation and weakly-supervised learning are promising research directions that lower labeling effort by learning a new class from only one annotated image and utilizing coarse labels instead, respectively. Previous works usually fail to leverage the anatomical structure and suffer from class imbalance and low contrast problems. Hence, we present an innovative framework for 3D medical image segmentation with one-shot and weakly-supervised settings. Firstly a propagation-reconstruction network is proposed to project scribbles from annotated volume to unlabeled 3D images based on the assumption that anatomical patterns in different human bodies are similar. Then a dual-level feature denoising module is designed to refine the scribbles based on anatomical- and pixel-level features. After expanding the scribbles to pseudo masks, we could train a segmentation model for the new class with the noisy label training strategy. Experiments on one abdomen and one head-and-neck CT dataset show the proposed method obtains significant improvement over the state-of-the-art methods and performs robustly even under severe class imbalance and low contrast.
Pulmonary Vessel Segmentation based on Orthogonal Fused U-Net++ of Chest CT Images
Jul 03, 2021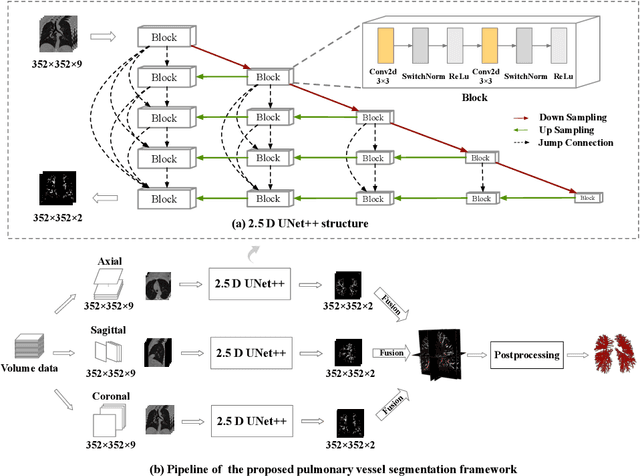
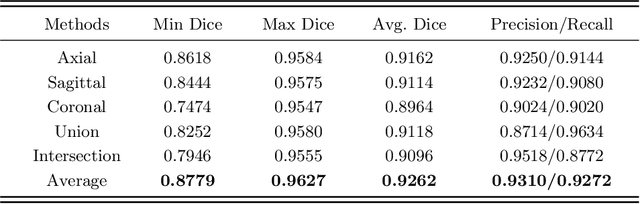
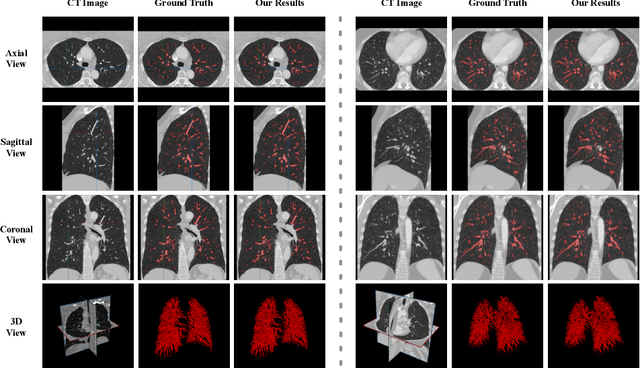
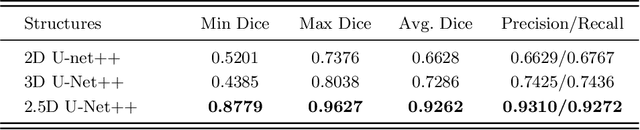
Pulmonary vessel segmentation is important for clinical diagnosis of pulmonary diseases, while is also challenging due to the complicated structure. In this work, we present an effective framework and refinement process of pulmonary vessel segmentation from chest computed tomographic (CT) images. The key to our approach is a 2.5D segmentation network applied from three orthogonal axes, which presents a robust and fully automated pulmonary vessel segmentation result with lower network complexity and memory usage compared to 3D networks. The slice radius is introduced to convolve the adjacent information of the center slice and the multi-planar fusion optimizes the presentation of intra- and inter- slice features. Besides, the tree-like structure of the pulmonary vessel is extracted in the post-processing process, which is used for segmentation refining and pruning. In the evaluation experiments, three fusion methods are tested and the most promising one is compared with the state-of-the-art 2D and 3D structures on 300 cases of lung images randomly selected from LIDC dataset. Our method outperforms other network structures by a large margin and achieves by far the highest average DICE score of 0.9272 and precision of 0.9310, as per our knowledge from the pulmonary vessel segmentation models available in the literature.