 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPAD: Industrial Process Anomaly Detection Dataset
Apr 23, 2024



Video anomaly detection (VAD) is a challenging task aiming to recognize anomalies in video frames, and existing large-scale VAD researches primarily focus on road traffic and human activity scenes. In industrial scenes, there are often a variety of unpredictable anomalies, and the VAD method can play a significant role in these scenarios. However, there is a lack of applicable datasets and methods specifically tailored for industrial production scenarios due to concerns regarding privacy and security. To bridge this gap, we propose a new dataset, IPAD, specifically designed for VAD in industrial scenarios. The industrial processes in our dataset are chosen through on-site factory research and discussions with engineers. This dataset covers 16 different industrial devices and contains over 6 hours of both synthetic and real-world video footage. Moreover, we annotate the key feature of the industrial process, ie, periodicity. Based on the proposed dataset, we introduce a period memory module and a sliding window inspection mechanism to effectively investigate the periodic information in a basic reconstruction model. Our framework leverages LoRA adapter to explore the effective migration of pretrained models, which are initially trained using synthetic data, into real-world scenarios. Our proposed dataset and method will fill the gap in the field of industrial video anomaly detection and drive the process of video understanding tasks as well as smart factory deployment.
Infusion: Preventing Customized Text-to-Image Diffusion from Overfitting
Apr 22, 2024Text-to-image (T2I) customization aims to create images that embody specific visual concepts delineated in textual descriptions. However, existing works still face a main challenge, concept overfitting. To tackle this challenge, we first analyze overfitting, categorizing it into concept-agnostic overfitting, which undermines non-customized concept knowledge, and concept-specific overfitting, which is confined to customize on limited modalities, i.e, backgrounds, layouts, styles. To evaluate the overfitting degree, we further introduce two metrics, i.e, Latent Fisher divergence and Wasserstein metric to measure the distribution changes of non-customized and customized concept respectively. Drawing from the analysis, we propose Infusion, a T2I customization method that enables the learning of target concepts to avoid being constrained by limited training modalities, while preserving non-customized knowledge. Remarkably, Infusion achieves this feat with remarkable efficiency, requiring a mere 11KB of trained parameters. Extensive experiments also demonstrate that our approach outperforms state-of-the-art methods in both single and multi-concept customized generation.
Robust and Accurate Object Detection via Self-Knowledge Distillation
Nov 14, 2021
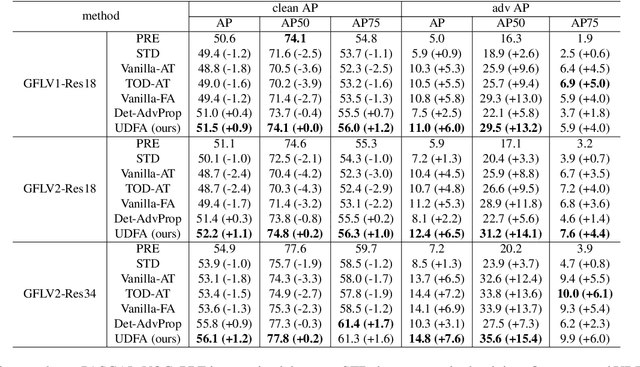
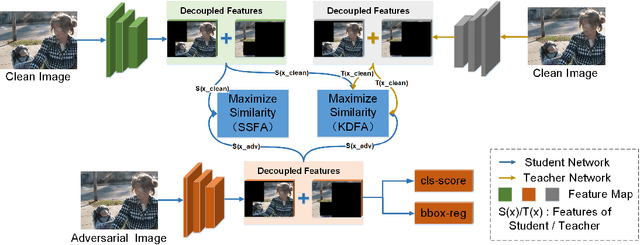
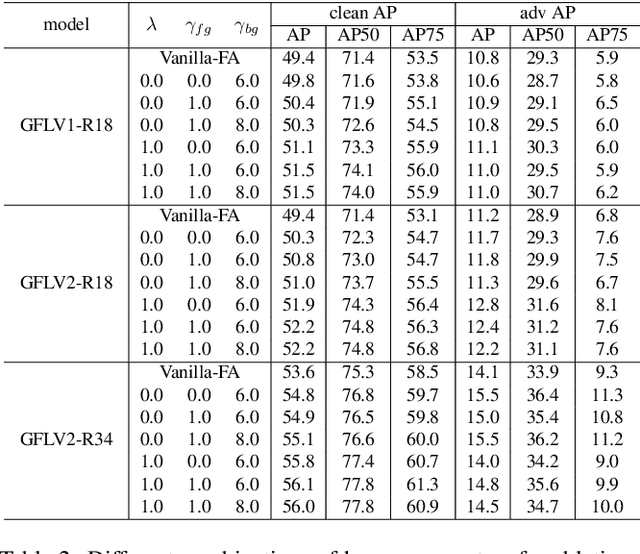
Object detection has achieved promising performance on clean datasets, but how to achieve better tradeoff between the adversarial robustness and clean precision is still under-explored. Adversarial training is the mainstream method to improve robustness, but most of the works will sacrifice clean precision to gain robustness than standard training. In this paper, we propose Unified Decoupled Feature Alignment (UDFA), a novel fine-tuning paradigm which achieves better performance than existing methods, by fully exploring the combination between self-knowledge distillation and adversarial training for object detection. We first use decoupled fore/back-ground features to construct self-knowledge distillation branch between clean feature representation from pretrained detector (served as teacher) and adversarial feature representation from student detector. Then we explore the self-knowledge distillation from a new angle by decoupling original branch into a self-supervised learning branch and a new self-knowledge distillation branch. With extensive experiments on the PASCAL-VOC and MS-COCO benchmarks, the evaluation results show that UDFA can surpass the standard training and state-of-the-art adversarial training methods for object detection. For example, compared with teacher detector, our approach on GFLV2 with ResNet-50 improves clean precision by 2.2 AP on PASCAL-VOC; compared with SOTA adversarial training methods, our approach improves clean precision by 1.6 AP, while improving adversarial robustness by 0.5 AP. Our code will be available at https://github.com/grispeut/udfa.
Privacy-Preserving Federated Learning on Partitioned Attributes
Apr 29, 2021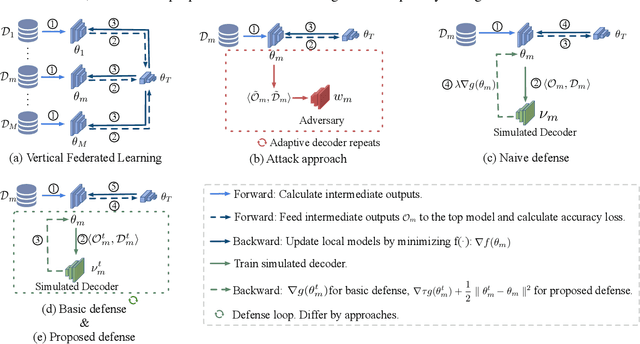

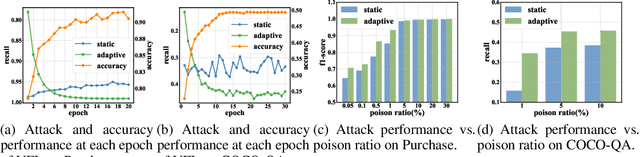
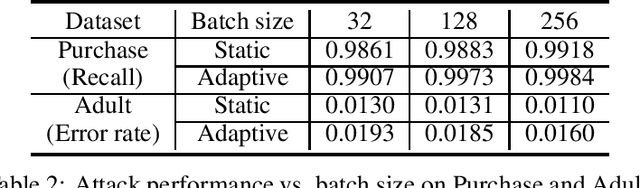
Real-world data is usually segmented by attributes and distributed across different parties. Federated learning empowers collaborative training without exposing local data or models. As we demonstrate through designed attacks, even with a small proportion of corrupted data, an adversary can accurately infer the input attributes. We introduce an adversarial learning based procedure which tunes a local model to release privacy-preserving intermediate representations. To alleviate the accuracy decline, we propose a defense method based on the forward-backward splitting algorithm, which respectively deals with the accuracy loss and privacy loss in the forward and backward gradient descent steps, achieving the two objectives simultaneously. Extensive experiments on a variety of datasets have shown that our defense significantly mitigates privacy leakage with negligible impact on the federated learning task.