 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEP: A Decentralized Large Language Model Evaluation Protocol
Mar 01, 2026With the rapid development of Large Language Models (LLMs), a large number of benchmarks have been proposed. However, most benchmarks lack unified evaluation standard and require the manual implementation of custom scripts, making results hard to ensure consistency and reproducibility. Furthermore, mainstream evaluation frameworks are centralized, with datasets and answers, which increases the risk of benchmark leakage. To address these issues, we propose a Decentralized Evaluation Protocol (DEP), a decentralized yet unified and standardized evaluation framework through a matching server without constraining benchmarks. The server can be mounted locally or deployed remotely, and once adapted, it can be reused over the long term. By decoupling users, LLMs, and benchmarks, DEP enables modular, plug-and-play evaluation: benchmark files and evaluation logic stay exclusively on the server side. In remote setting, users cannot access the ground truth, thereby achieving data isolation and leak-proof evaluation. To facilitate practical adoption, we develop DEP Toolkit, a protocol-compatible toolkit that supports features such as breakpoint resume, concurrent requests, and congestion control. We also provide detailed documentation for adapting new benchmarks to DEP. Using DEP toolkit, we evaluate multiple LLMs across benchmarks. Experimental results verify the effectiveness of DEP and show that it reduces the cost of deploying benchmark evaluations. As of February 2026, we have adapted over 60 benchmarks and continue to promote community co-construction to support unified evaluation across various tasks and domains.
Finding the Translation Switch: Discovering and Exploiting the Task-Initiation Features in LLMs
Jan 16, 2026Large Language Models (LLMs) frequently exhibit strong translation abilities, even without task-specific fine-tuning. However, the internal mechanisms governing this innate capability remain largely opaque. To demystify this process, we leverage Sparse Autoencoders (SAEs) and introduce a novel framework for identifying task-specific features. Our method first recalls features that are frequently co-activated on translation inputs and then filters them for functional coherence using a PCA-based consistency metric. This framework successfully isolates a small set of **translation initiation** features. Causal interventions demonstrate that amplifying these features steers the model towards correct translation, while ablating them induces hallucinations and off-task outputs, confirming they represent a core component of the model's innate translation competency. Moving from analysis to application, we leverage this mechanistic insight to propose a new data selection strategy for efficient fine-tuning. Specifically, we prioritize training on **mechanistically hard** samples-those that fail to naturally activate the translation initiation features. Experiments show this approach significantly improves data efficiency and suppresses hallucinations. Furthermore, we find these mechanisms are transferable to larger models of the same family. Our work not only decodes a core component of the translation mechanism in LLMs but also provides a blueprint for using internal model mechanism to create more robust and efficient models. The codes are available at https://github.com/flamewei123/AAAI26-translation-Initiation-Features.
Revisiting Entropy in Reinforcement Learning for Large Reasoning Models
Nov 08, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a predominant approach for enhancing the reasoning capabilities of large language models (LLMs). However, the entropy of LLMs usually collapses during RLVR training, causing premature convergence to suboptimal local minima and hinder further performance improvement. Although various approaches have been proposed to mitigate entropy collapse, a comprehensive study of entropy in RLVR remains lacking. To address this gap, we conduct extensive experiments to investigate the entropy dynamics of LLMs trained with RLVR and analyze how model entropy correlates with response diversity, calibration, and performance across various benchmarks. Our findings reveal that the number of off-policy updates, the diversity of training data, and the clipping thresholds in the optimization objective are critical factors influencing the entropy of LLMs trained with RLVR. Moreover, we theoretically and empirically demonstrate that tokens with positive advantages are the primary contributors to entropy collapse, and that model entropy can be effectively regulated by adjusting the relative loss weights of tokens with positive and negative advantages during training.
LHMKE: A Large-scale Holistic Multi-subject Knowledge Evaluation Benchmark for Chinese Large Language Models
Mar 19, 2024

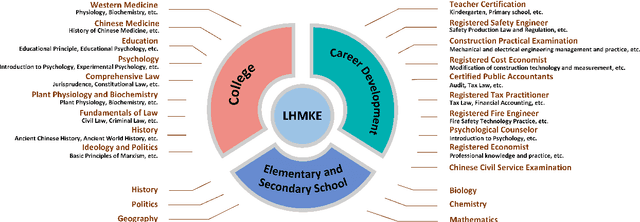

Chinese Large Language Models (LLMs) have recently demonstrated impressive capabilities across various NLP benchmarks and real-world applications. However, the existing benchmarks for comprehensively evaluating these LLMs are still insufficient, particularly in terms of measuring knowledge that LLMs capture. Current datasets collect questions from Chinese examinations across different subjects and educational levels to address this issue. Yet, these benchmarks primarily focus on objective questions such as multiple-choice questions, leading to a lack of diversity in question types. To tackle this problem, we propose LHMKE, a Large-scale, Holistic, and Multi-subject Knowledge Evaluation benchmark in this paper. LHMKE is designed to provide a comprehensive evaluation of the knowledge acquisition capabilities of Chinese LLMs. It encompasses 10,465 questions across 75 tasks covering 30 subjects, ranging from primary school to professional certification exams. Notably, LHMKE includes both objective and subjective questions, offering a more holistic evaluation of the knowledge level of LLMs. We have assessed 11 Chinese LLMs under the zero-shot setting, which aligns with real examinations, and compared their performance across different subjects. We also conduct an in-depth analysis to check whether GPT-4 can automatically score subjective predictions. Our findings suggest that LHMKE is a challenging and advanced testbed for Chinese LLMs.
Do Large Language Models Mirror Cognitive Language Processing?
Feb 28, 2024

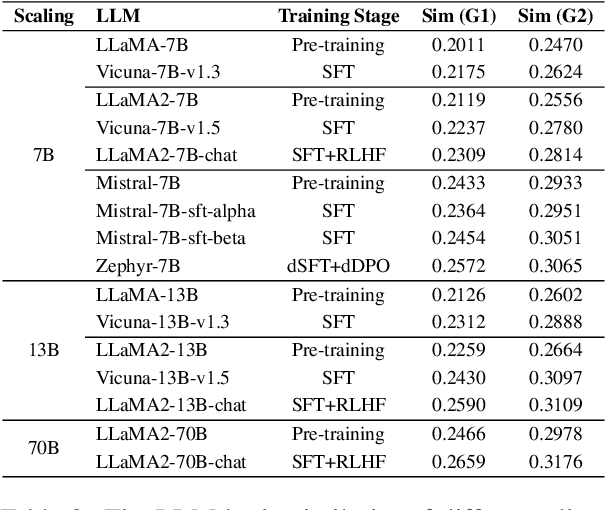

Large language models (LLMs) have demonstrated remarkable capabilities in text comprehension and logical reasoning, achiving or even surpassing human-level performance in numerous cognition tasks. As LLMs are trained from massive textual outputs of human language cognition, it is natural to ask whether LLMs mirror cognitive language processing. Or to what extend LLMs resemble cognitive language processing? In this paper, we propose a novel method that bridge between LLM representations and human cognition signals to evaluate how effectively LLMs simulate cognitive language processing. We employ Representational Similarity Analysis (RSA) to mearsure the alignment between 16 mainstream LLMs and fMRI signals of the brain. We empirically investigate the impact of a variety of factors (e.g., model scaling, alignment training, instruction appending) on such LLM-brain alignment. Experimental results indicate that model scaling is positively correlated with LLM-brain similarity, and alignment training can significantly improve LLM-brain similarity. Additionally, the performance of a wide range of LLM evaluations (e.g., MMLU, Chatbot Arena) is highly correlated with the LLM-brain similarity.
AI-driven emergence of frequency information non-uniform distribution via THz metasurface spectrum prediction
Dec 05, 2023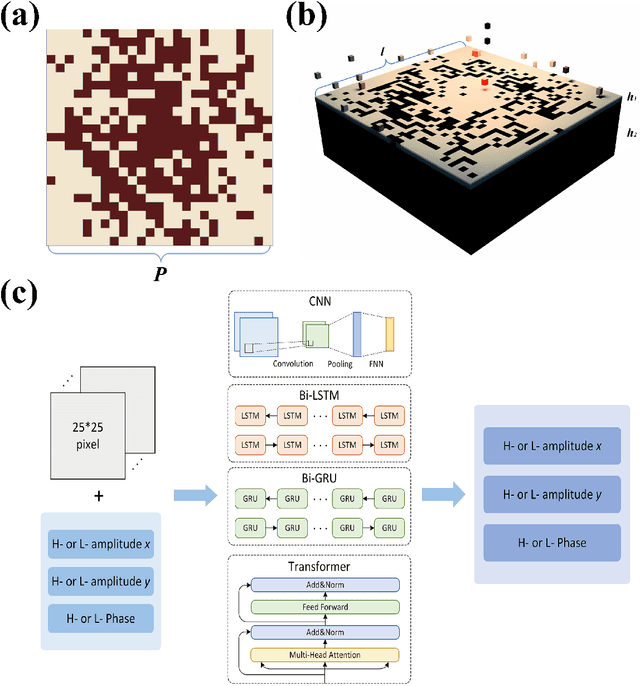
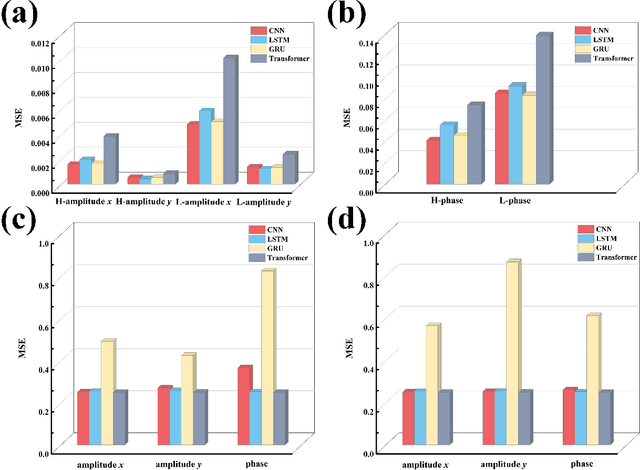
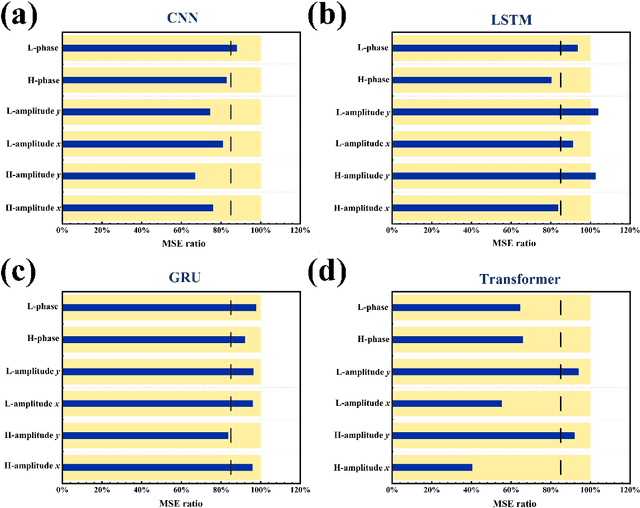
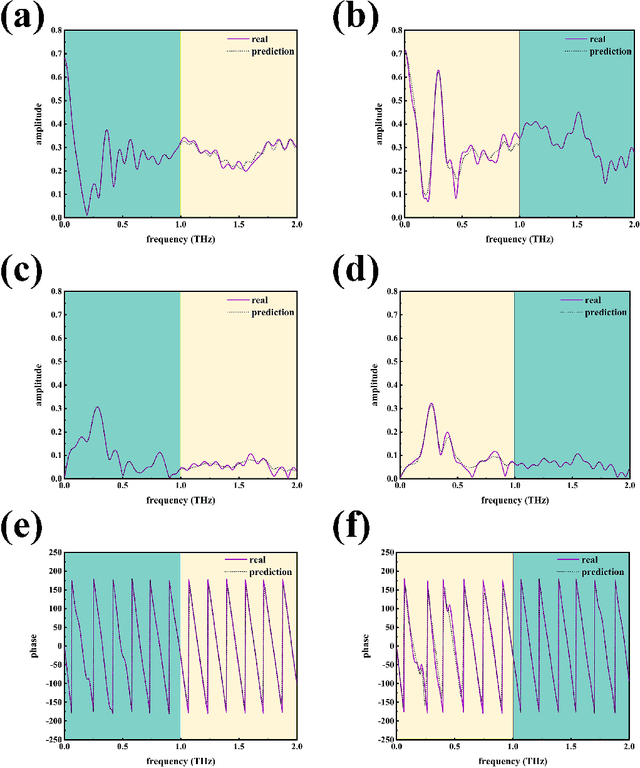
Recently, artificial intelligence has been extensively deployed across various scientific disciplines, optimizing and guiding the progression of experiments through the integration of abundant datasets, whilst continuously probing the vast theoretical space encapsulated within the data. Particularly, deep learning models, due to their end-to-end adaptive learning capabilities, are capable of autonomously learning intrinsic data features, thereby transcending the limitations of traditional experience to a certain extent. Here, we unveil previously unreported information characteristics pertaining to different frequencies emerged during our work on predicting the terahertz spectral modulation effects of metasurfaces based on AI-prediction. Moreover, we have substantiated that our proposed methodology of simply adding supplementary multi-frequency inputs to the existing dataset during the target spectral prediction process can significantly enhance the predictive accuracy of the network. This approach effectively optimizes the utilization of existing datasets and paves the way for interdisciplinary research and applications in artificial intelligence, chemistry, composite material design, biomedicine, and other fields.
M3KE: A Massive Multi-Level Multi-Subject Knowledge Evaluation Benchmark for Chinese Large Language Models
May 21, 2023



Large language models have recently made tremendous progress in a variety of aspects, e.g., cross-task generalization, instruction following. Comprehensively evaluating the capability of large language models in multiple tasks is of great importance. In this paper, we propose M3KE, a Massive Multi-Level Multi-Subject Knowledge Evaluation benchmark, which is developed to measure knowledge acquired by Chinese large language models by testing their multitask accuracy in zero- and few-shot settings. We have collected 20,477 questions from 71 tasks. Our selection covers all major levels of Chinese education system, ranging from the primary school to college, as well as a wide variety of subjects, including humanities, history, politics, law, education, psychology, science, technology, art and religion. All questions are multiple-choice questions with four options, hence guaranteeing a standardized and unified assessment process. We've assessed a number of state-of-the-art open-source Chinese large language models on the proposed benchmark. The size of these models varies from 335M to 130B parameters. Experiment results demonstrate that they perform significantly worse than GPT-3.5 that reaches an accuracy of ~ 48% on M3KE. The dataset is available at https://github.com/tjunlp-lab/M3KE.
Bridging between Cognitive Processing Signals and Linguistic Features via a Unified Attentional Network
Dec 16, 2021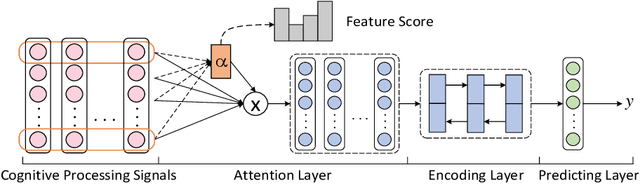

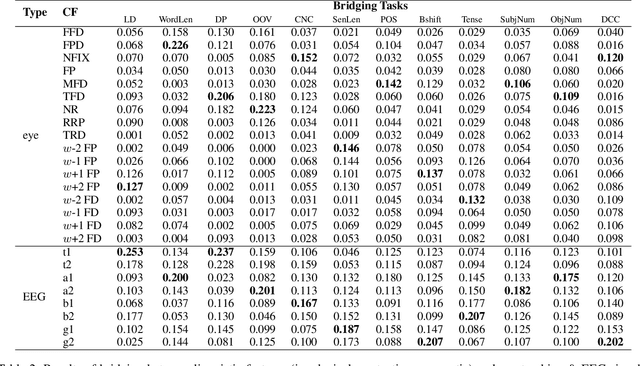

Cognitive processing signals can be used to improve natural language processing (NLP) tasks. However, it is not clear how these signals correlate with linguistic information. Bridging between human language processing and linguistic features has been widely studied in neurolinguistics, usually via single-variable controlled experiments with highly-controlled stimuli. Such methods not only compromises the authenticity of natural reading, but also are time-consuming and expensive. In this paper, we propose a data-driven method to investigate the relationship between cognitive processing signals and linguistic features. Specifically, we present a unified attentional framework that is composed of embedding, attention, encoding and predicting layers to selectively map cognitive processing signals to linguistic features. We define the mapping procedure as a bridging task and develop 12 bridging tasks for lexical, syntactic and semantic features. The proposed framework only requires cognitive processing signals recorded under natural reading as inputs, and can be used to detect a wide range of linguistic features with a single cognitive dataset. Observations from experiment results resonate with previous neuroscience findings. In addition to this, our experiments also reveal a number of interesting findings, such as the correlation between contextual eye-tracking features and tense of sentence.
CogAlign: Learning to Align Textual Neural Representations to Cognitive Language Processing Signals
Jun 22, 2021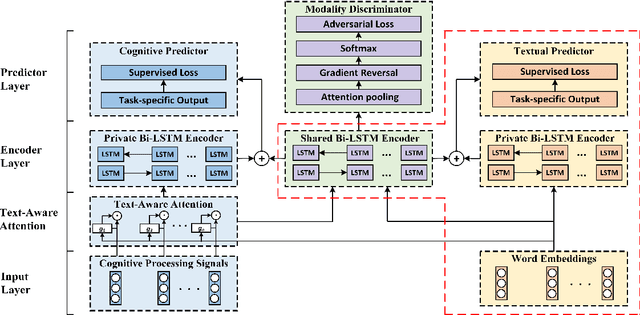

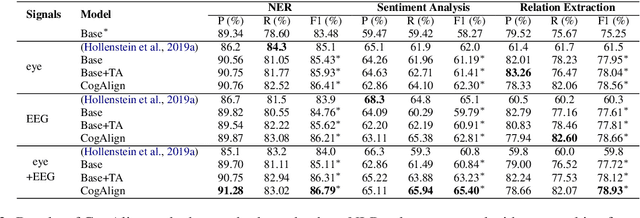
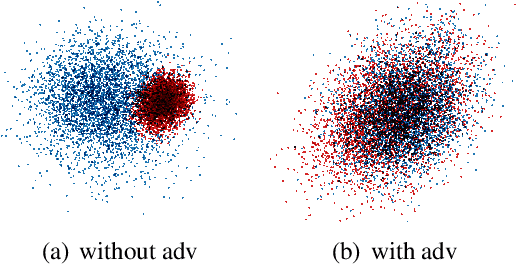
Most previous studies integrate cognitive language processing signals (e.g., eye-tracking or EEG data) into neural models of natural language processing (NLP) just by directly concatenating word embeddings with cognitive features, ignoring the gap between the two modalities (i.e., textual vs. cognitive) and noise in cognitive features. In this paper, we propose a CogAlign approach to these issues, which learns to align textual neural representations to cognitive features. In CogAlign, we use a shared encoder equipped with a modality discriminator to alternatively encode textual and cognitive inputs to capture their differences and commonalities. Additionally, a text-aware attention mechanism is proposed to detect task-related information and to avoid using noise in cognitive features. Experimental results on three NLP tasks, namely named entity recognition, sentiment analysis and relation extraction, show that CogAlign achieves significant improvements with multiple cognitive features over state-of-the-art models on public datasets. Moreover, our model is able to transfer cognitive information to other datasets that do not have any cognitive processing signals.