 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Entropy in Reinforcement Learning for Large Reasoning Models
Nov 08, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a predominant approach for enhancing the reasoning capabilities of large language models (LLMs). However, the entropy of LLMs usually collapses during RLVR training, causing premature convergence to suboptimal local minima and hinder further performance improvement. Although various approaches have been proposed to mitigate entropy collapse, a comprehensive study of entropy in RLVR remains lacking. To address this gap, we conduct extensive experiments to investigate the entropy dynamics of LLMs trained with RLVR and analyze how model entropy correlates with response diversity, calibration, and performance across various benchmarks. Our findings reveal that the number of off-policy updates, the diversity of training data, and the clipping thresholds in the optimization objective are critical factors influencing the entropy of LLMs trained with RLVR. Moreover, we theoretically and empirically demonstrate that tokens with positive advantages are the primary contributors to entropy collapse, and that model entropy can be effectively regulated by adjusting the relative loss weights of tokens with positive and negative advantages during training.
Do Large Language Models Mirror Cognitive Language Processing?
Feb 28, 2024

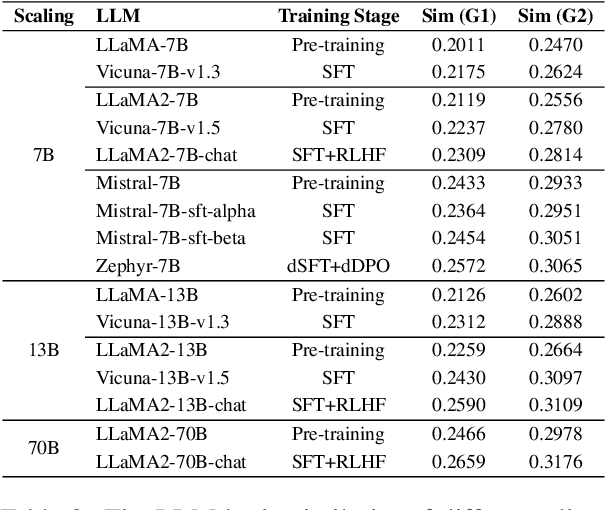

Large language models (LLMs) have demonstrated remarkable capabilities in text comprehension and logical reasoning, achiving or even surpassing human-level performance in numerous cognition tasks. As LLMs are trained from massive textual outputs of human language cognition, it is natural to ask whether LLMs mirror cognitive language processing. Or to what extend LLMs resemble cognitive language processing? In this paper, we propose a novel method that bridge between LLM representations and human cognition signals to evaluate how effectively LLMs simulate cognitive language processing. We employ Representational Similarity Analysis (RSA) to mearsure the alignment between 16 mainstream LLMs and fMRI signals of the brain. We empirically investigate the impact of a variety of factors (e.g., model scaling, alignment training, instruction appending) on such LLM-brain alignment. Experimental results indicate that model scaling is positively correlated with LLM-brain similarity, and alignment training can significantly improve LLM-brain similarity. Additionally, the performance of a wide range of LLM evaluations (e.g., MMLU, Chatbot Arena) is highly correlated with the LLM-brain similarity.
KESDT: knowledge enhanced shallow and deep Transformer for detecting adverse drug reactions
Aug 18, 2023Adverse drug reaction (ADR) detection is an essential task in the medical field, as ADRs have a gravely detrimental impact on patients' health and the healthcare system. Due to a large number of people sharing information on social media platforms, an increasing number of efforts focus on social media data to carry out effective ADR detection. Despite having achieved impressive performance, the existing methods of ADR detection still suffer from three main challenges. Firstly, researchers have consistently ignored the interaction between domain keywords and other words in the sentence. Secondly, social media datasets suffer from the challenges of low annotated data. Thirdly, the issue of sample imbalance is commonly observed in social media datasets. To solve these challenges, we propose the Knowledge Enhanced Shallow and Deep Transformer(KESDT) model for ADR detection. Specifically, to cope with the first issue, we incorporate the domain keywords into the Transformer model through a shallow fusion manner, which enables the model to fully exploit the interactive relationships between domain keywords and other words in the sentence. To overcome the low annotated data, we integrate the synonym sets into the Transformer model through a deep fusion manner, which expands the size of the samples. To mitigate the impact of sample imbalance, we replace the standard cross entropy loss function with the focal loss function for effective model training. We conduct extensive experiments on three public datasets including TwiMed, Twitter, and CADEC. The proposed KESDT outperforms state-of-the-art baselines on F1 values, with relative improvements of 4.87%, 47.83%, and 5.73% respectively, which demonstrates the effectiveness of our proposed KESDT.