 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Large Language Models Mirror Cognitive Language Processing?
Paper and Code
Feb 28, 2024

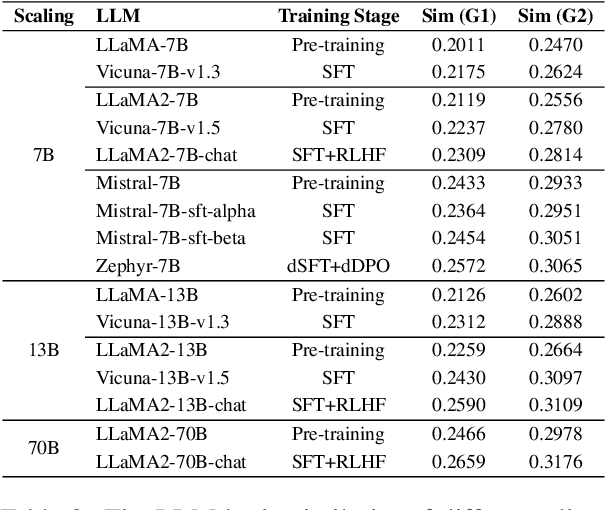

Large language models (LLMs) have demonstrated remarkable capabilities in text comprehension and logical reasoning, achiving or even surpassing human-level performance in numerous cognition tasks. As LLMs are trained from massive textual outputs of human language cognition, it is natural to ask whether LLMs mirror cognitive language processing. Or to what extend LLMs resemble cognitive language processing? In this paper, we propose a novel method that bridge between LLM representations and human cognition signals to evaluate how effectively LLMs simulate cognitive language processing. We employ Representational Similarity Analysis (RSA) to mearsure the alignment between 16 mainstream LLMs and fMRI signals of the brain. We empirically investigate the impact of a variety of factors (e.g., model scaling, alignment training, instruction appending) on such LLM-brain alignment. Experimental results indicate that model scaling is positively correlated with LLM-brain similarity, and alignment training can significantly improve LLM-brain similarity. Additionally, the performance of a wide range of LLM evaluations (e.g., MMLU, Chatbot Arena) is highly correlated with the LLM-brain similarity.