 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learn Unimodal Signals with Weak Supervision for Multimodal Sentiment Analysis
Paper and Code

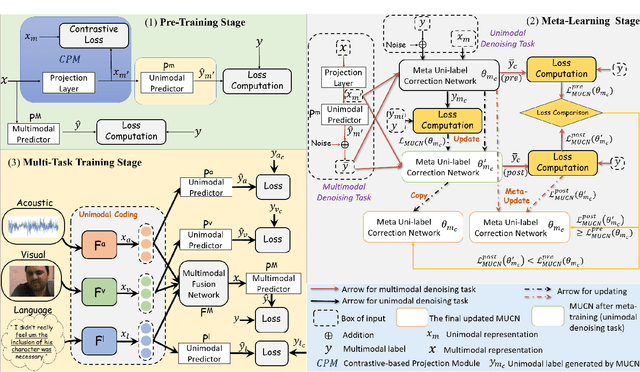
Multimodal sentiment analysis aims to effectively integrate information from various sources to infer sentiment, where in many cases there are no annotations for unimodal labels. Therefore, most works rely on multimodal labels for training. However, there exists the noisy label problem for the learning of unimodal signals as multimodal annotations are not always the ideal substitutes for the unimodal ones, failing to achieve finer optimization for individual modalities. In this paper, we explore the learning of unimodal labels under the weak supervision from the annotated multimodal labels. Specifically, we propose a novel meta uni-label generation (MUG) framework to address the above problem, which leverages the available multimodal labels to learn the corresponding unimodal labels by the meta uni-label correction network (MUCN). We first design a contrastive-based projection module to bridge the gap between unimodal and multimodal representations, so as to use multimodal annotations to guide the learning of MUCN. Afterwards, we propose unimodal and multimodal denoising tasks to train MUCN with explicit supervision via a bi-level optimization strategy. We then jointly train unimodal and multimodal learning tasks to extract discriminative unimodal features for multimodal inference. Experimental results suggest that MUG outperforms competitive baselines and can learn accurate unimodal labels.