 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Contrastive Learning of Tri-Modal Representation for Multimodal Sentiment Analysis
Paper and Code
Sep 04, 2021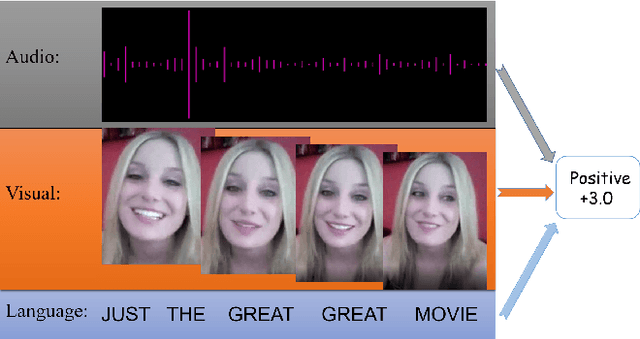
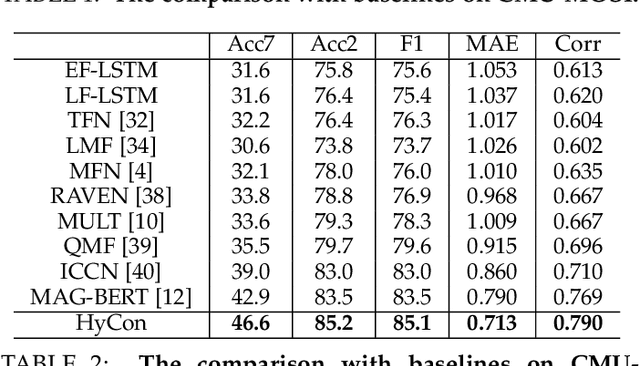
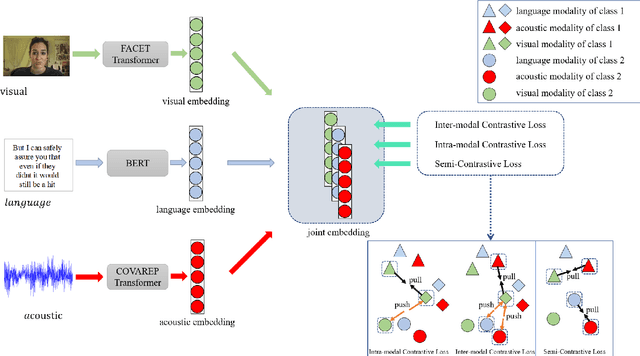
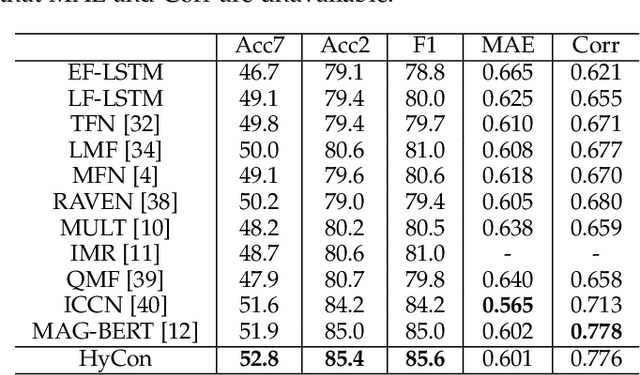
The wide application of smart devices enables the availability of multimodal data, which can be utilized in many tasks. In the field of multimodal sentiment analysis (MSA), most previous works focus on exploring intra- and inter-modal interactions. However, training a network with cross-modal information (language, visual, audio) is still challenging due to the modality gap, and existing methods still cannot ensure to sufficiently learn intra-/inter-modal dynamics. Besides, while learning dynamics within each sample draws great attention, the learning of inter-class relationships is neglected. Moreover, the size of datasets limits the generalization ability of existing methods. To address the afore-mentioned issues, we propose a novel framework HyCon for hybrid contrastive learning of tri-modal representation. Specifically, we simultaneously perform intra-/inter-modal contrastive learning and semi-contrastive learning (that is why we call it hybrid contrastive learning), with which the model can fully explore cross-modal interactions, preserve inter-class relationships and reduce the modality gap. Besides, a refinement term is devised to prevent the model falling into a sub-optimal solution. Moreover, HyCon can naturally generate a large amount of training pairs for better generalization and reduce the negative effect of limited datasets. Extensive experiments on public datasets demonstrate that our proposed method outperforms existing works.