 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Dataset and Effective Inter-Frame Alignment for Real-World Video Super-Resolution
Dec 10, 2022



Video super-resolution (VSR) aiming to reconstruct a high-resolution (HR) video from its low-resolution (LR) counterpart has made tremendous progress in recent years. However, it remains challenging to deploy existing VSR methods to real-world data with complex degradations. On the one hand, there are few well-aligned real-world VSR datasets, especially with large super-resolution scale factors, which limits the development of real-world VSR tasks. On the other hand, alignment algorithms in existing VSR methods perform poorly for real-world videos, leading to unsatisfactory results. As an attempt to address the aforementioned issues, we build a real-world 4 VSR dataset, namely MVSR4$\times$, where low- and high-resolution videos are captured with different focal length lenses of a smartphone, respectively. Moreover, we propose an effective alignment method for real-world VSR, namely EAVSR. EAVSR takes the proposed multi-layer adaptive spatial transform network (MultiAdaSTN) to refine the offsets provided by the pre-trained optical flow estimation network. Experimental results on RealVSR and MVSR4$\times$ datasets show the effectiveness and practicality of our method, and we achieve state-of-the-art performance in real-world VSR task. The dataset and code will be publicly available.
Self-Supervised Learning for Real-World Super-Resolution from Dual Zoomed Observations
Mar 02, 2022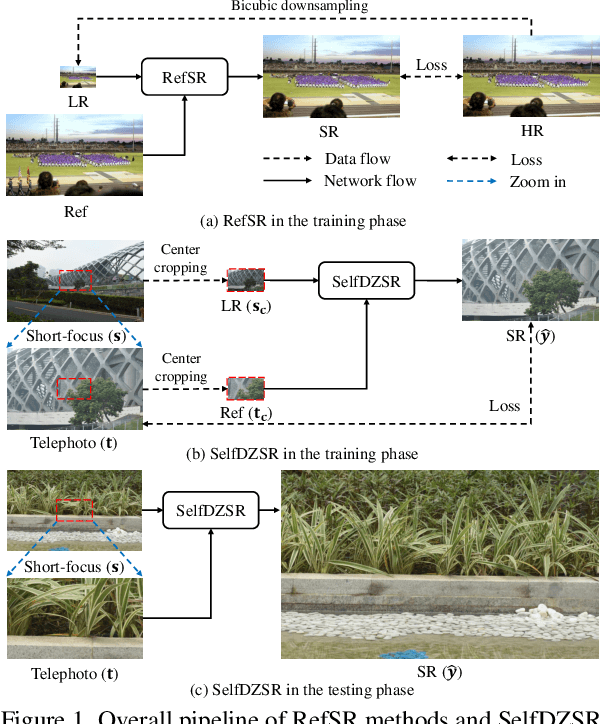
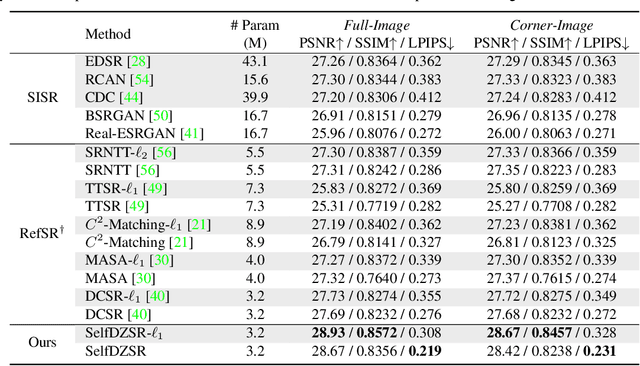

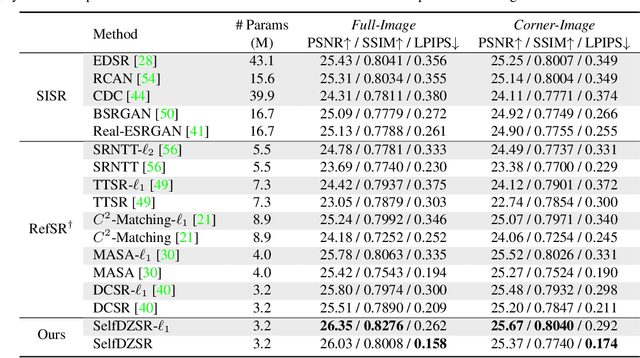
In this paper, we consider two challenging issues in reference-based super-resolution (RefSR), (i) how to choose a proper reference image, and (ii) how to learn real-world RefSR in a self-supervised manner. Particularly, we present a novel self-supervised learning approach for real-world image SR from observations at dual camera zooms (SelfDZSR). For the first issue, the more zoomed (telephoto) image can be naturally leveraged as the reference to guide the SR of the lesser zoomed (short-focus) image. For the second issue, SelfDZSR learns a deep network to obtain the SR result of short-focal image and with the same resolution as the telephoto image. For this purpose, we take the telephoto image instead of an additional high-resolution image as the supervision information and select a patch from it as the reference to super-resolve the corresponding short-focus image patch. To mitigate the effect of various misalignment between the short-focus low-resolution (LR) image and telephoto ground-truth (GT) image, we design a degradation model and map the GT to a pseudo-LR image aligned with GT. Then the pseudo-LR and LR image can be fed into the proposed adaptive spatial transformer networks (AdaSTN) to deform the LR features. During testing, SelfDZSR can be directly deployed to super-solve the whole short-focus image with the reference of telephoto image. Experiments show that our method achieves better quantitative and qualitative performance against state-of-the-arts. The code and pre-trained models will be publicly available.
Learning RAW-to-sRGB Mappings with Inaccurately Aligned Supervision
Aug 18, 2021
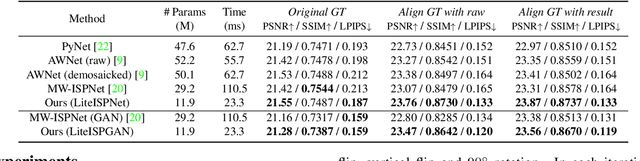
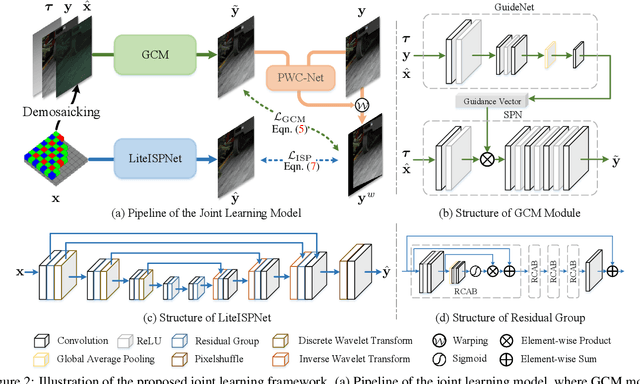
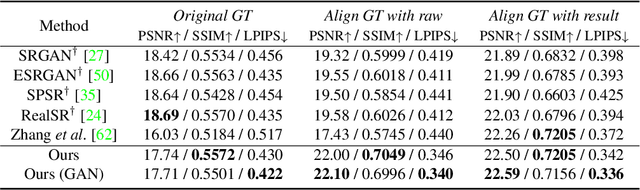
Learning RAW-to-sRGB mapping has drawn increasing attention in recent years, wherein an input raw image is trained to imitate the target sRGB image captured by another camera. However, the severe color inconsistency makes it very challenging to generate well-aligned training pairs of input raw and target sRGB images. While learning with inaccurately aligned supervision is prone to causing pixel shift and producing blurry results. In this paper, we circumvent such issue by presenting a joint learning model for image alignment and RAW-to-sRGB mapping. To diminish the effect of color inconsistency in image alignment, we introduce to use a global color mapping (GCM) module to generate an initial sRGB image given the input raw image, which can keep the spatial location of the pixels unchanged, and the target sRGB image is utilized to guide GCM for converting the color towards it. Then a pre-trained optical flow estimation network (e.g., PWC-Net) is deployed to warp the target sRGB image to align with the GCM output. To alleviate the effect of inaccurately aligned supervision, the warped target sRGB image is leveraged to learn RAW-to-sRGB mapping. When training is done, the GCM module and optical flow network can be detached, thereby bringing no extra computation cost for inference. Experiments show that our method performs favorably against state-of-the-arts on ZRR and SR-RAW datasets. With our joint learning model, a light-weight backbone can achieve better quantitative and qualitative performance on ZRR dataset. Codes are available at https://github.com/cszhilu1998/RAW-to-sRGB.