 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScatter Points in Space: 3D Detection from Multi-view Monocular Images
Paper and Code
Aug 31, 2022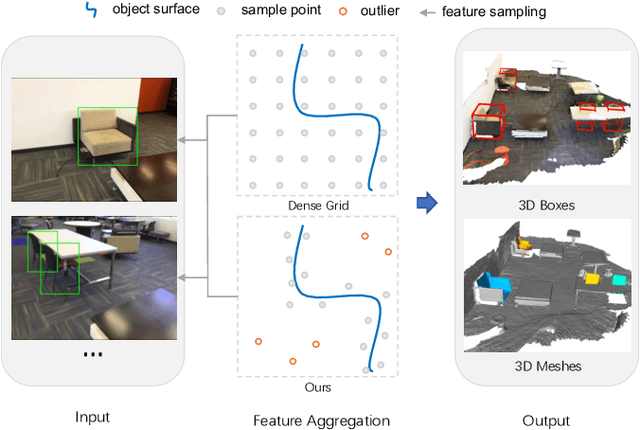
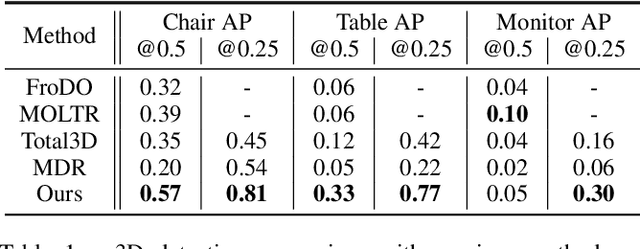
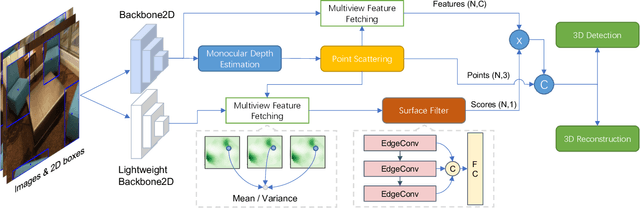
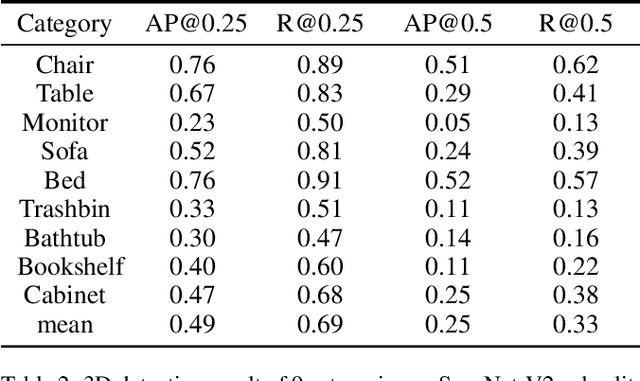
3D object detection from monocular image(s) is a challenging and long-standing problem of computer vision. To combine information from different perspectives without troublesome 2D instance tracking, recent methods tend to aggregate multiview feature by sampling regular 3D grid densely in space, which is inefficient. In this paper, we attempt to improve multi-view feature aggregation by proposing a learnable keypoints sampling method, which scatters pseudo surface points in 3D space, in order to keep data sparsity. The scattered points augmented by multi-view geometric constraints and visual features are then employed to infer objects location and shape in the scene. To make up the limitations of single frame and model multi-view geometry explicitly, we further propose a surface filter module for noise suppression. Experimental results show that our method achieves significantly better performance than previous works in terms of 3D detection (more than 0.1 AP improvement on some categories of ScanNet). The code will be publicly available.