 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEssence Knowledge Distillation for Speech Recognition
Paper and Code
Jun 26, 2019
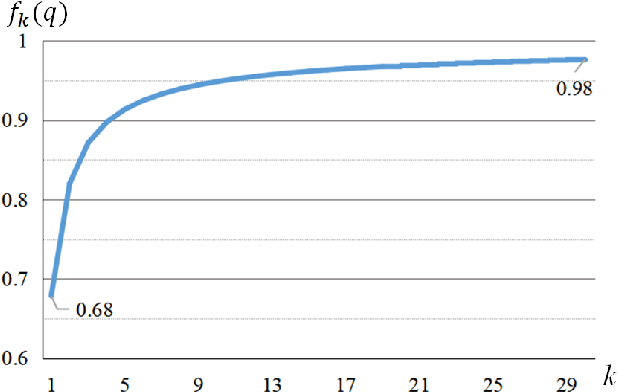
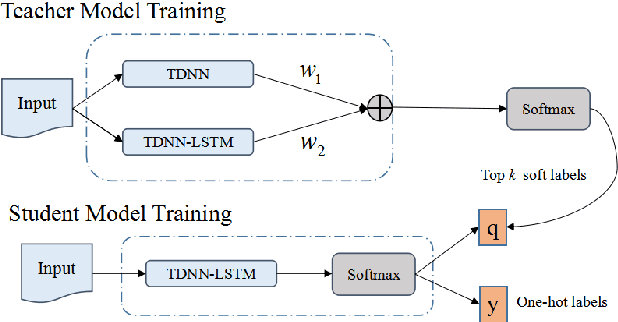
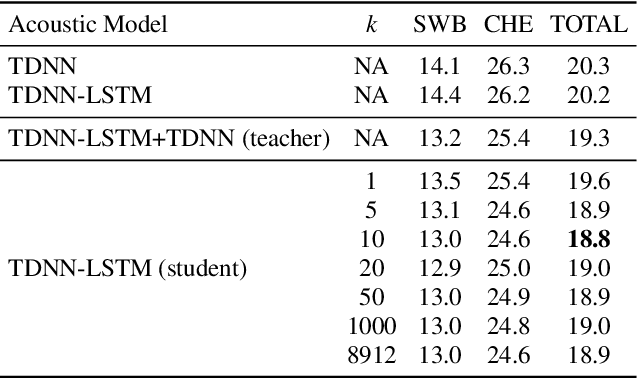
It is well known that a speech recognition system that combines multiple acoustic models trained on the same data significantly outperforms a single-model system. Unfortunately, real time speech recognition using a whole ensemble of models is too computationally expensive. In this paper, we propose to distill the knowledge of essence in an ensemble of models (i.e. the teacher model) to a single model (i.e. the student model) that needs much less computation to deploy. Previously, all the soften outputs of the teacher model are used to optimize the student model. We argue that not all the outputs of the ensemble are necessary to be distilled. Some of the outputs may even contain noisy information that is useless or even harmful to the training of the student model. In addition, we propose to train the student model with a multitask learning approach by utilizing both the soften outputs of the teacher model and the correct hard labels. The proposed method achieves some surprising results on the Switchboard data set. When the student model is trained together with the correct labels and the essence knowledge from the teacher model, it not only significantly outperforms another single model with the same architecture that is trained only with the correct labels, but also consistently outperforms the teacher model that is used to generate the soft labels.