 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Based Food Analysis for Automatic Dietary Assessment
Aug 06, 2021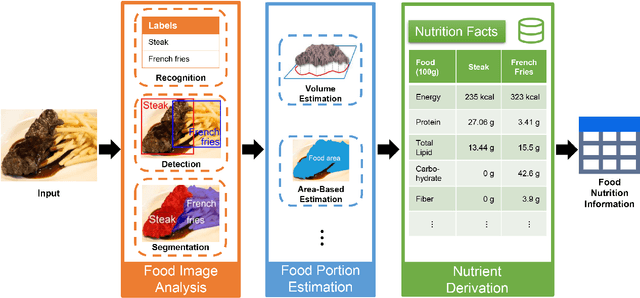

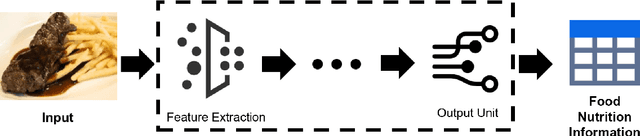
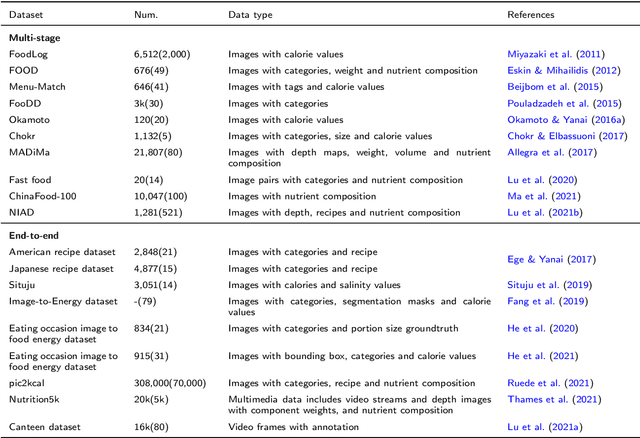
Background: Maintaining a healthy diet is vital to avoid health-related issues, e.g., undernutrition, obesity and many non-communicable diseases. An indispensable part of the health diet is dietary assessment. Traditional manual recording methods are burdensome and contain substantial biases and errors. Recent advances in Artificial Intelligence, especially computer vision technologies, have made it possible to develop automatic dietary assessment solutions, which are more convenient, less time-consuming and even more accurate to monitor daily food intake. Scope and approach: This review presents one unified Vision-Based Dietary Assessment (VBDA) framework, which generally consists of three stages: food image analysis, volume estimation and nutrient derivation. Vision-based food analysis methods, including food recognition, detection and segmentation, are systematically summarized, and methods of volume estimation and nutrient derivation are also given. The prosperity of deep learning makes VBDA gradually move to an end-to-end implementation, which applies food images to a single network to directly estimate the nutrition. The recently proposed end-to-end methods are also discussed. We further analyze existing dietary assessment datasets, indicating that one large-scale benchmark is urgently needed, and finally highlight key challenges and future trends for VBDA. Key findings and conclusions: After thorough exploration, we find that multi-task end-to-end deep learning approaches are one important trend of VBDA. Despite considerable research progress, many challenges remain for VBDA due to the meal complexity. We also provide the latest ideas for future development of VBDA, e.g., fine-grained food analysis and accurate volume estimation. This survey aims to encourage researchers to propose more practical solutions for VBDA.
Face Sketch Synthesis via Semantic-Driven Generative Adversarial Network
Jun 29, 2021
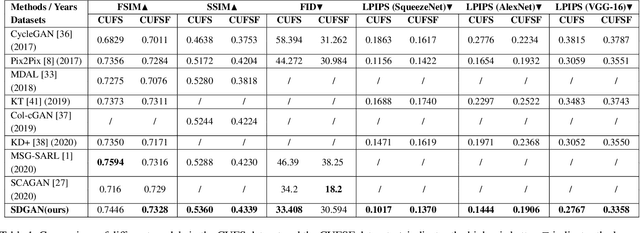


Face sketch synthesis has made significant progress with the development of deep neural networks in these years. The delicate depiction of sketch portraits facilitates a wide range of applications like digital entertainment and law enforcement. However, accurate and realistic face sketch generation is still a challenging task due to the illumination variations and complex backgrounds in the real scenes. To tackle these challenges, we propose a novel Semantic-Driven Generative Adversarial Network (SDGAN) which embeds global structure-level style injection and local class-level knowledge re-weighting. Specifically, we conduct facial saliency detection on the input face photos to provide overall facial texture structure, which could be used as a global type of prior information. In addition, we exploit face parsing layouts as the semantic-level spatial prior to enforce globally structural style injection in the generator of SDGAN. Furthermore, to enhance the realistic effect of the details, we propose a novel Adaptive Re-weighting Loss (ARLoss) which dedicates to balance the contributions of different semantic classes. Experimentally, our extensive experiments on CUFS and CUFSF datasets show that our proposed algorithm achieves state-of-the-art performance.