 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniFood8K: Single-Image Nutrition Estimation via Hierarchical Frequency-Aligned Fusion
Apr 14, 2026Accurate estimation of food nutrition plays a vital role in promoting healthy dietary habits and personalized diet management. Most existing food datasets primarily focus on Western cuisines and lack sufficient coverage of Chinese dishes, which restricts accurate nutritional estimation for Chinese meals. Moreover, many state-of-the-art nutrition prediction methods rely on depth sensors, restricting their applicability in daily scenarios. To address these limitations, we introduce OmniFood8K, a comprehensive multimodal dataset comprising 8,036 food samples, each with detailed nutritional annotations and multi-view images. In addition, to enhance models' capability in nutritional prediction, we construct NutritionSynth-115K, a large-scale synthetic dataset that introduces compositional variations while preserving precise nutritional labels. Moreover, we propose an end-to-end framework for nutritional prediction from a single RGB image. First, we predict a depth map from a single RGB image and design the Scale-Shift Residual Adapter (SSRA) to refine it for global scale consistency and local structural preservation. Second, we propose the Frequency-Aligned Fusion Module (FAFM) to hierarchically align and fuse RGB and depth features in the frequency domain. Finally, we design a Mask-based Prediction Head (MPH) to emphasize key ingredient regions via dynamic channel selection for more accurate prediction. Extensive experiments on multiple datasets demonstrate the superiority of our method over existing approaches. Project homepage: https://yudongjian.github.io/OmniFood8K-food/
FoodSky: A Food-oriented Large Language Model that Passes the Chef and Dietetic Examination
Jun 11, 2024



Food is foundational to human life, serving not only as a source of nourishment but also as a cornerstone of cultural identity and social interaction. As the complexity of global dietary needs and preferences grows, food intelligence is needed to enable food perception and reasoning for various tasks, ranging from recipe generation and dietary recommendation to diet-disease correlation discovery and understanding. Towards this goal, for powerful capabilities across various domains and tasks in Large Language Models (LLMs), we introduce Food-oriented LLM FoodSky to comprehend food data through perception and reasoning. Considering the complexity and typicality of Chinese cuisine, we first construct one comprehensive Chinese food corpus FoodEarth from various authoritative sources, which can be leveraged by FoodSky to achieve deep understanding of food-related data. We then propose Topic-based Selective State Space Model (TS3M) and the Hierarchical Topic Retrieval Augmented Generation (HTRAG) mechanism to enhance FoodSky in capturing fine-grained food semantics and generating context-aware food-relevant text, respectively. Our extensive evaluations demonstrate that FoodSky significantly outperforms general-purpose LLMs in both chef and dietetic examinations, with an accuracy of 67.2% and 66.4% on the Chinese National Chef Exam and the National Dietetic Exam, respectively. FoodSky not only promises to enhance culinary creativity and promote healthier eating patterns, but also sets a new standard for domain-specific LLMs that address complex real-world issues in the food domain. An online demonstration of FoodSky is available at http://222.92.101.211:8200.
Synthesizing Knowledge-enhanced Features for Real-world Zero-shot Food Detection
Feb 14, 2024Food computing brings various perspectives to computer vision like vision-based food analysis for nutrition and health. As a fundamental task in food computing, food detection needs Zero-Shot Detection (ZSD) on novel unseen food objects to support real-world scenarios, such as intelligent kitchens and smart restaurants. Therefore, we first benchmark the task of Zero-Shot Food Detection (ZSFD) by introducing FOWA dataset with rich attribute annotations. Unlike ZSD, fine-grained problems in ZSFD like inter-class similarity make synthesized features inseparable. The complexity of food semantic attributes further makes it more difficult for current ZSD methods to distinguish various food categories. To address these problems, we propose a novel framework ZSFDet to tackle fine-grained problems by exploiting the interaction between complex attributes. Specifically, we model the correlation between food categories and attributes in ZSFDet by multi-source graphs to provide prior knowledge for distinguishing fine-grained features. Within ZSFDet, Knowledge-Enhanced Feature Synthesizer (KEFS) learns knowledge representation from multiple sources (e.g., ingredients correlation from knowledge graph) via the multi-source graph fusion. Conditioned on the fusion of semantic knowledge representation, the region feature diffusion model in KEFS can generate fine-grained features for training the effective zero-shot detector. Extensive evaluations demonstrate the superior performance of our method ZSFDet on FOWA and the widely-used food dataset UECFOOD-256, with significant improvements by 1.8% and 3.7% ZSD mAP compared with the strong baseline RRFS. Further experiments on PASCAL VOC and MS COCO prove that enhancement of the semantic knowledge can also improve the performance on general ZSD. Code and dataset are available at https://github.com/LanceZPF/KEFS.
SeeDS: Semantic Separable Diffusion Synthesizer for Zero-shot Food Detection
Oct 07, 2023
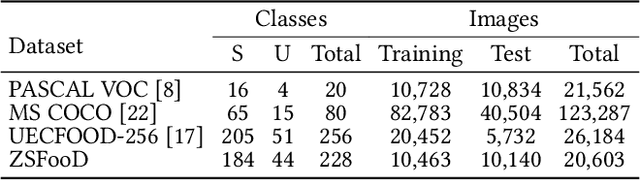

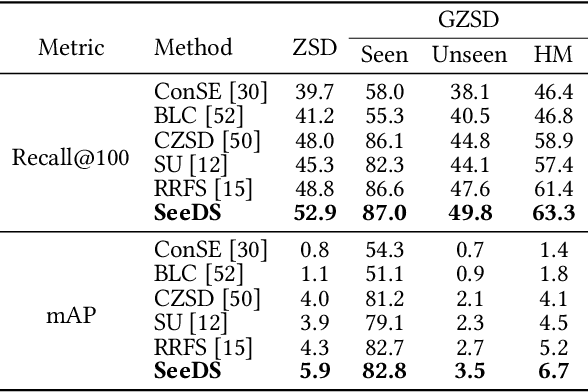
Food detection is becoming a fundamental task in food computing that supports various multimedia applications, including food recommendation and dietary monitoring. To deal with real-world scenarios, food detection needs to localize and recognize novel food objects that are not seen during training, demanding Zero-Shot Detection (ZSD). However, the complexity of semantic attributes and intra-class feature diversity poses challenges for ZSD methods in distinguishing fine-grained food classes. To tackle this, we propose the Semantic Separable Diffusion Synthesizer (SeeDS) framework for Zero-Shot Food Detection (ZSFD). SeeDS consists of two modules: a Semantic Separable Synthesizing Module (S$^3$M) and a Region Feature Denoising Diffusion Model (RFDDM). The S$^3$M learns the disentangled semantic representation for complex food attributes from ingredients and cuisines, and synthesizes discriminative food features via enhanced semantic information. The RFDDM utilizes a novel diffusion model to generate diversified region features and enhances ZSFD via fine-grained synthesized features. Extensive experiments show the state-of-the-art ZSFD performance of our proposed method on two food datasets, ZSFooD and UECFOOD-256. Moreover, SeeDS also maintains effectiveness on general ZSD datasets, PASCAL VOC and MS COCO. The code and dataset can be found at https://github.com/LanceZPF/SeeDS.
Deep Learning for Logo Detection: A Survey
Oct 10, 2022

When logos are increasingly created, logo detection has gradually become a research hotspot across many domains and tasks. Recent advances in this area are dominated by deep learning-based solutions, where many datasets, learning strategies, network architectures, etc. have been employed. This paper reviews the advance in applying deep learning techniques to logo detection. Firstly, we discuss a comprehensive account of public datasets designed to facilitate performance evaluation of logo detection algorithms, which tend to be more diverse, more challenging, and more reflective of real life. Next, we perform an in-depth analysis of the existing logo detection strategies and the strengths and weaknesses of each learning strategy. Subsequently, we summarize the applications of logo detection in various fields, from intelligent transportation and brand monitoring to copyright and trademark compliance. Finally, we analyze the potential challenges and present the future directions for the development of logo detection to complete this survey.
Discriminative Semantic Feature Pyramid Network with Guided Anchoring for Logo Detection
Aug 31, 2021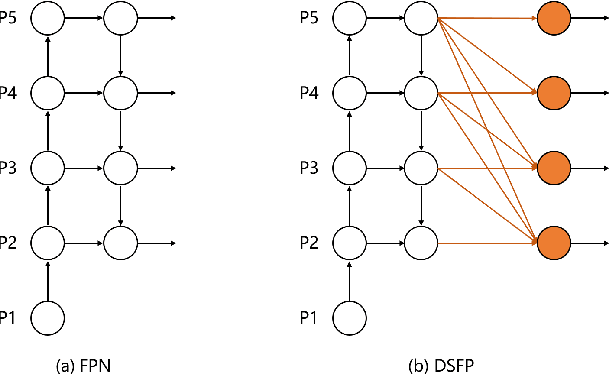
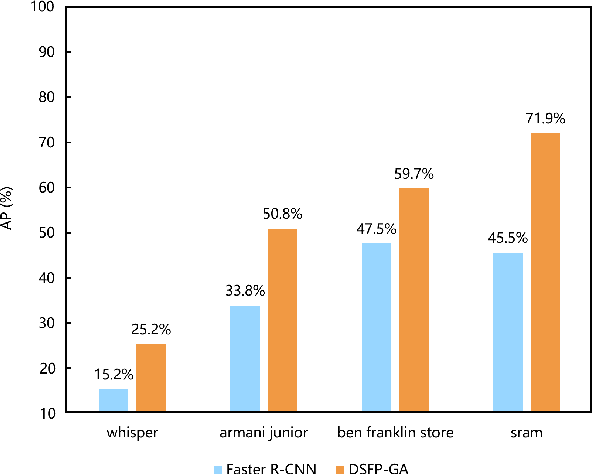
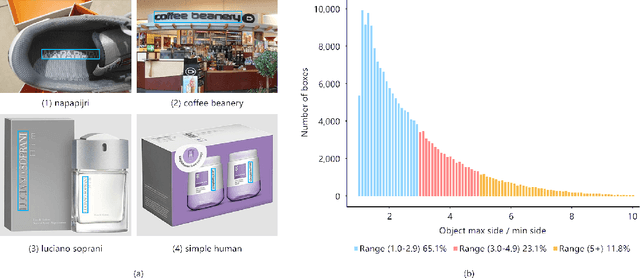
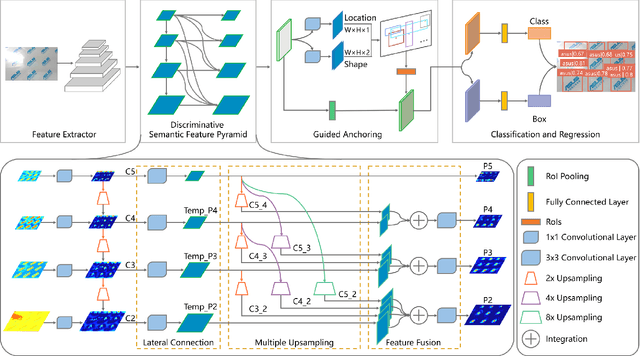
Recently, logo detection has received more and more attention for its wide applications in the multimedia field, such as intellectual property protection, product brand management, and logo duration monitoring. Unlike general object detection, logo detection is a challenging task, especially for small logo objects and large aspect ratio logo objects in the real-world scenario. In this paper, we propose a novel approach, named Discriminative Semantic Feature Pyramid Network with Guided Anchoring (DSFP-GA), which can address these challenges via aggregating the semantic information and generating different aspect ratio anchor boxes. More specifically, our approach mainly consists of Discriminative Semantic Feature Pyramid (DSFP) and Guided Anchoring (GA). Considering that low-level feature maps that are used to detect small logo objects lack semantic information, we propose the DSFP, which can enrich more discriminative semantic features of low-level feature maps and can achieve better performance on small logo objects. Furthermore, preset anchor boxes are less efficient for detecting large aspect ratio logo objects. We therefore integrate the GA into our method to generate large aspect ratio anchor boxes to mitigate this issue. Extensive experimental results on four benchmarks demonstrate the effectiveness of our proposed DSFP-GA. Moreover, we further conduct visual analysis and ablation studies to illustrate the advantage of our method in detecting small and large aspect logo objects. The code and models can be found at https://github.com/Zhangbaisong/DSFP-GA.
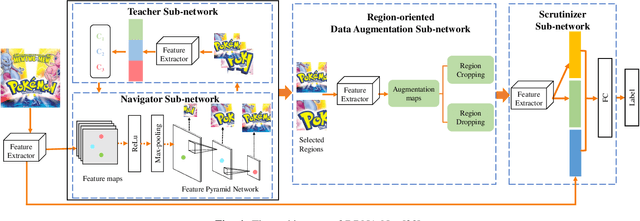
FoodLogoDet-1500: A Dataset for Large-Scale Food Logo Detection via Multi-Scale Feature Decoupling Network
Aug 10, 2021
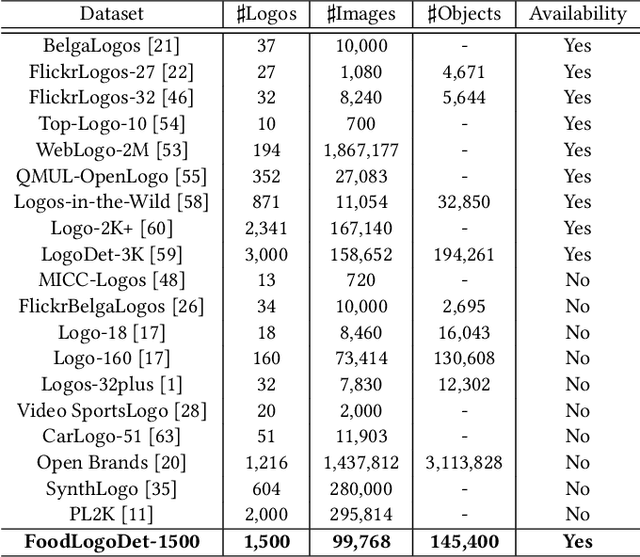
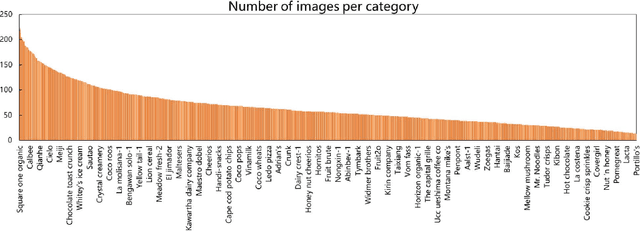
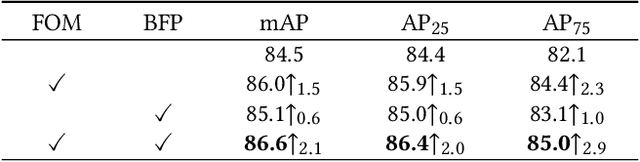
Food logo detection plays an important role in the multimedia for its wide real-world applications, such as food recommendation of the self-service shop and infringement detection on e-commerce platforms. A large-scale food logo dataset is urgently needed for developing advanced food logo detection algorithms. However, there are no available food logo datasets with food brand information. To support efforts towards food logo detection, we introduce the dataset FoodLogoDet-1500, a new large-scale publicly available food logo dataset, which has 1,500 categories, about 100,000 images and about 150,000 manually annotated food logo objects. We describe the collection and annotation process of FoodLogoDet-1500, analyze its scale and diversity, and compare it with other logo datasets. To the best of our knowledge, FoodLogoDet-1500 is the first largest publicly available high-quality dataset for food logo detection. The challenge of food logo detection lies in the large-scale categories and similarities between food logo categories. For that, we propose a novel food logo detection method Multi-scale Feature Decoupling Network (MFDNet), which decouples classification and regression into two branches and focuses on the classification branch to solve the problem of distinguishing multiple food logo categories. Specifically, we introduce the feature offset module, which utilizes the deformation-learning for optimal classification offset and can effectively obtain the most representative features of classification in detection. In addition, we adopt a balanced feature pyramid in MFDNet, which pays attention to global information, balances the multi-scale feature maps, and enhances feature extraction capability. Comprehensive experiments on FoodLogoDet-1500 and other two benchmark logo datasets demonstrate the effectiveness of the proposed method. The FoodLogoDet-1500 can be found at this https URL.
Vision-Based Food Analysis for Automatic Dietary Assessment
Aug 06, 2021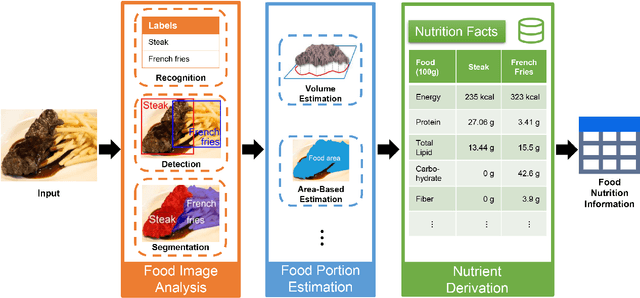

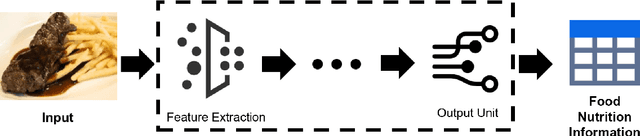
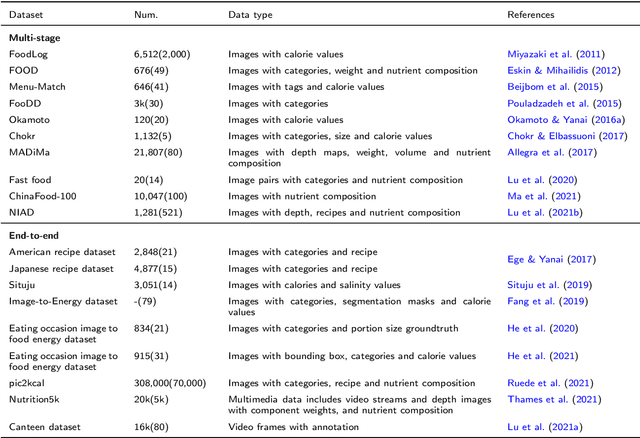
Background: Maintaining a healthy diet is vital to avoid health-related issues, e.g., undernutrition, obesity and many non-communicable diseases. An indispensable part of the health diet is dietary assessment. Traditional manual recording methods are burdensome and contain substantial biases and errors. Recent advances in Artificial Intelligence, especially computer vision technologies, have made it possible to develop automatic dietary assessment solutions, which are more convenient, less time-consuming and even more accurate to monitor daily food intake. Scope and approach: This review presents one unified Vision-Based Dietary Assessment (VBDA) framework, which generally consists of three stages: food image analysis, volume estimation and nutrient derivation. Vision-based food analysis methods, including food recognition, detection and segmentation, are systematically summarized, and methods of volume estimation and nutrient derivation are also given. The prosperity of deep learning makes VBDA gradually move to an end-to-end implementation, which applies food images to a single network to directly estimate the nutrition. The recently proposed end-to-end methods are also discussed. We further analyze existing dietary assessment datasets, indicating that one large-scale benchmark is urgently needed, and finally highlight key challenges and future trends for VBDA. Key findings and conclusions: After thorough exploration, we find that multi-task end-to-end deep learning approaches are one important trend of VBDA. Despite considerable research progress, many challenges remain for VBDA due to the meal complexity. We also provide the latest ideas for future development of VBDA, e.g., fine-grained food analysis and accurate volume estimation. This survey aims to encourage researchers to propose more practical solutions for VBDA.
Towards Building a Food Knowledge Graph for Internet of Food
Jul 13, 2021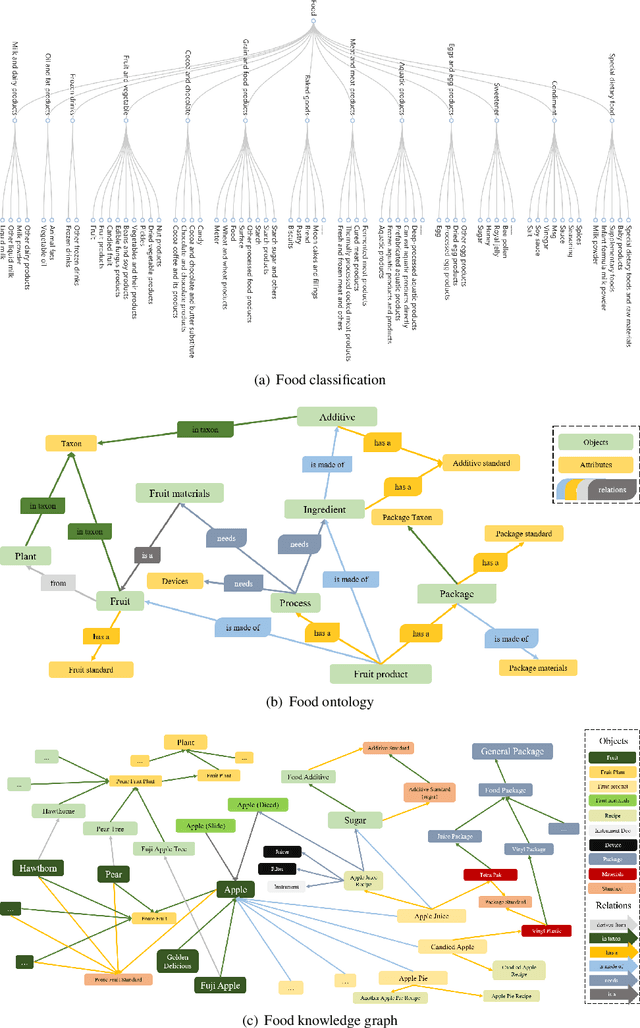
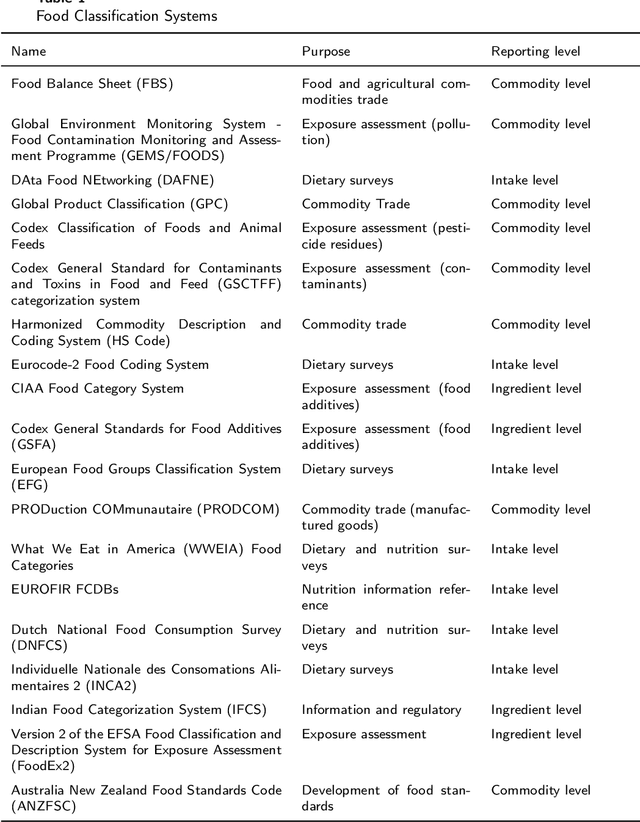
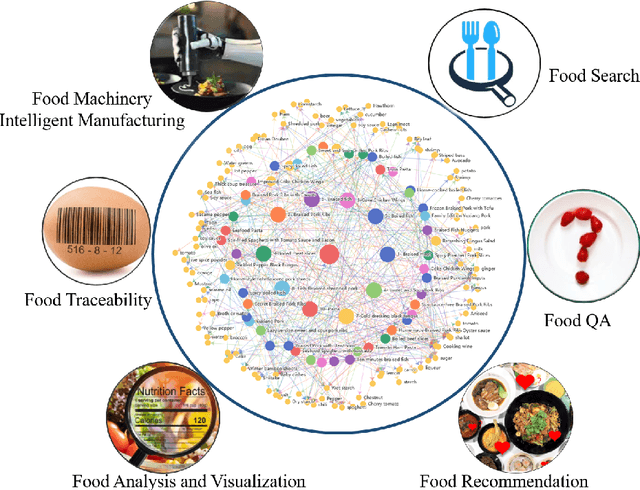
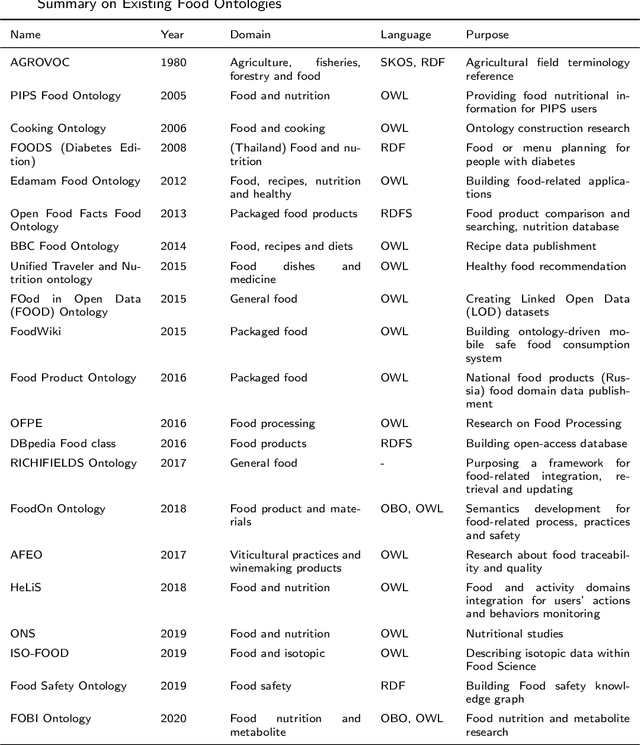
Background: The deployment of various networks (e.g., Internet of Things (IoT) and mobile networks) and databases (e.g., nutrition tables and food compositional databases) in the food system generates massive information silos due to the well-known data harmonization problem. The food knowledge graph provides a unified and standardized conceptual terminology and their relationships in a structured form and thus can transform these information silos across the whole food system to a more reusable globally digitally connected Internet of Food, enabling every stage of the food system from farm-to-fork. Scope and approach: We review the evolution of food knowledge organization, from food classification, food ontology to food knowledge graphs. We then discuss the progress in food knowledge graphs from several representative applications. We finally discuss the main challenges and future directions. Key findings and conclusions: Our comprehensive summary of current research on food knowledge graphs shows that food knowledge graphs play an important role in food-oriented applications, including food search and Question Answering (QA), personalized dietary recommendation, food analysis and visualization, food traceability, and food machinery intelligent manufacturing. Future directions for food knowledge graphs cover several fields such as multimodal food knowledge graphs and food intelligence.
Large Scale Visual Food Recognition
Mar 31, 2021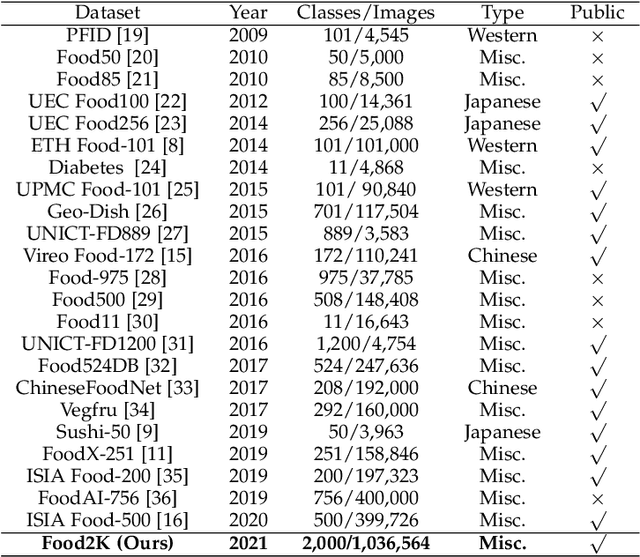
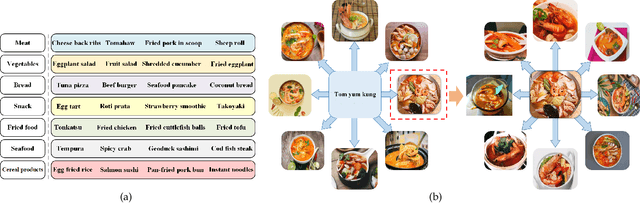


Food recognition plays an important role in food choice and intake, which is essential to the health and well-being of humans. It is thus of importance to the computer vision community, and can further support many food-oriented vision and multimodal tasks. Unfortunately, we have witnessed remarkable advancements in generic visual recognition for released large-scale datasets, yet largely lags in the food domain. In this paper, we introduce Food2K, which is the largest food recognition dataset with 2,000 categories and over 1 million images.Compared with existing food recognition datasets, Food2K bypasses them in both categories and images by one order of magnitude, and thus establishes a new challenging benchmark to develop advanced models for food visual representation learning. Furthermore, we propose a deep progressive region enhancement network for food recognition, which mainly consists of two components, namely progressive local feature learning and region feature enhancement. The former adopts improved progressive training to learn diverse and complementary local features, while the latter utilizes self-attention to incorporate richer context with multiple scales into local features for further local feature enhancement. Extensive experiments on Food2K demonstrate the effectiveness of our proposed method. More importantly, we have verified better generalization ability of Food2K in various tasks, including food recognition, food image retrieval, cross-modal recipe retrieval, food detection and segmentation. Food2K can be further explored to benefit more food-relevant tasks including emerging and more complex ones (e.g., nutritional understanding of food), and the trained models on Food2K can be expected as backbones to improve the performance of more food-relevant tasks. We also hope Food2K can serve as a large scale fine-grained visual recognition benchmark.