 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Automated Fact-Checking for Medical LLM Responses with Knowledge Graphs
Nov 16, 2025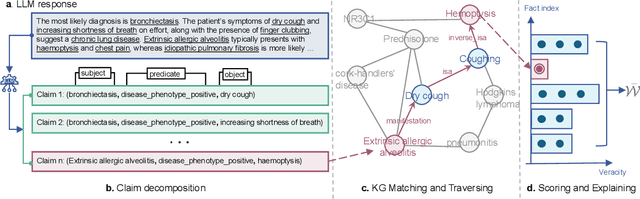
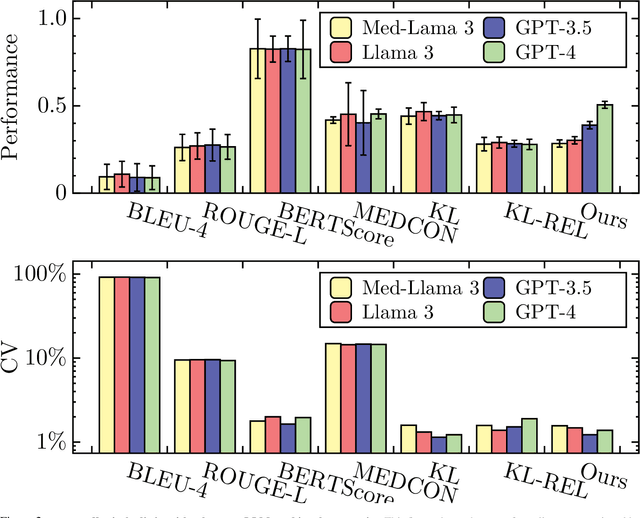
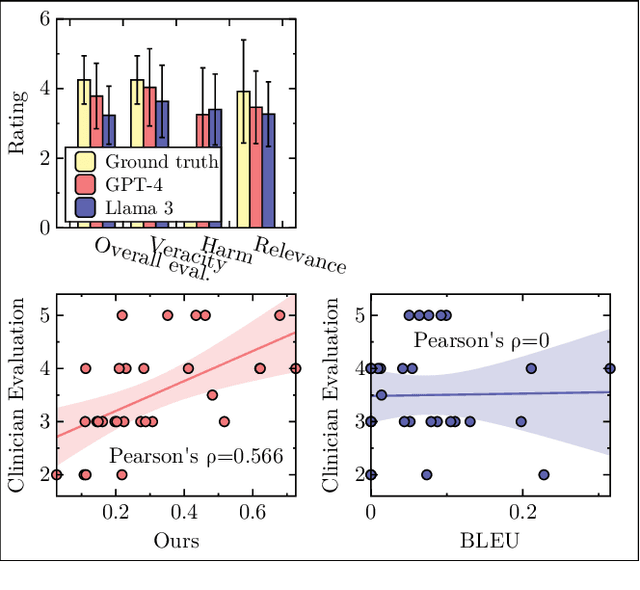
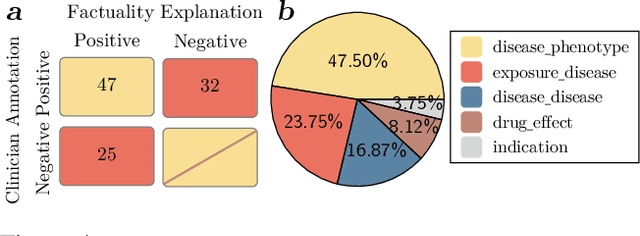
The recent proliferation of large language models (LLMs) holds the potential to revolutionize healthcare, with strong capabilities in diverse medical tasks. Yet, deploying LLMs in high-stakes healthcare settings requires rigorous verification and validation to understand any potential harm. This paper investigates the reliability and viability of using medical knowledge graphs (KGs) for the automated factuality evaluation of LLM-generated responses. To ground this investigation, we introduce FAITH, a framework designed to systematically probe the strengths and limitations of this KG-based approach. FAITH operates without reference answers by decomposing responses into atomic claims, linking them to a medical KG, and scoring them based on evidence paths. Experiments on diverse medical tasks with human subjective evaluations demonstrate that KG-grounded evaluation achieves considerably higher correlations with clinician judgments and can effectively distinguish LLMs with varying capabilities. It is also robust to textual variances. The inherent explainability of its scoring can further help users understand and mitigate the limitations of current LLMs. We conclude that while limitations exist, leveraging KGs is a prominent direction for automated factuality assessment in healthcare.
Conversational Exploration of Literature Landscape with LitChat
May 25, 2025We are living in an era of "big literature", where the volume of digital scientific publications is growing exponentially. While offering new opportunities, this also poses challenges for understanding literature landscapes, as traditional manual reviewing is no longer feasible. Recent large language models (LLMs) have shown strong capabilities for literature comprehension, yet they are incapable of offering "comprehensive, objective, open and transparent" views desired by systematic reviews due to their limited context windows and trust issues like hallucinations. Here we present LitChat, an end-to-end, interactive and conversational literature agent that augments LLM agents with data-driven discovery tools to facilitate literature exploration. LitChat automatically interprets user queries, retrieves relevant sources, constructs knowledge graphs, and employs diverse data-mining techniques to generate evidence-based insights addressing user needs. We illustrate the effectiveness of LitChat via a case study on AI4Health, highlighting its capacity to quickly navigate the users through large-scale literature landscape with data-based evidence that is otherwise infeasible with traditional means.
Rethinking Performance Analysis for Configurable Software Systems: A Case Study from a Fitness Landscape Perspective
Dec 22, 2024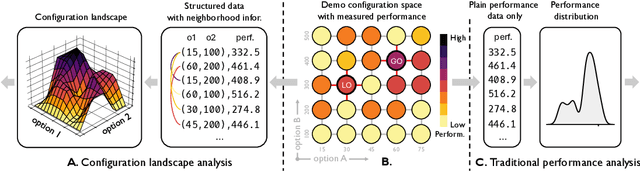

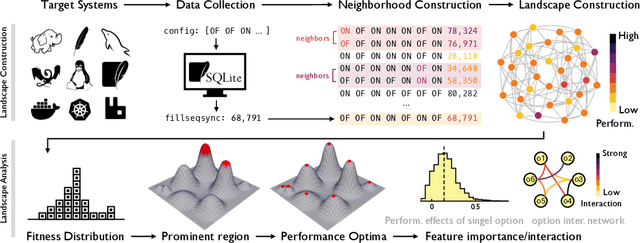
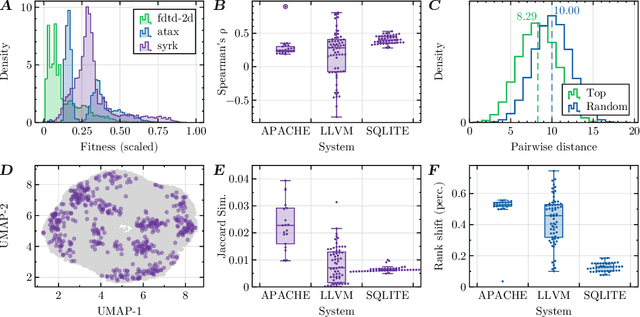
Modern software systems are often highly configurable to tailor varied requirements from diverse stakeholders. Understanding the mapping between configurations and the desired performance attributes plays a fundamental role in advancing the controllability and tuning of the underlying system, yet has long been a dark hole of knowledge due to its black-box nature. While there have been previous efforts in performance analysis for these systems, they analyze the configurations as isolated data points without considering their inherent spatial relationships. This renders them incapable of interrogating many important aspects of the configuration space like local optima. In this work, we advocate a novel perspective to rethink performance analysis -- modeling the configuration space as a structured ``landscape''. To support this proposition, we designed \our, an open-source, graph data mining empowered fitness landscape analysis (FLA) framework. By applying this framework to $86$M benchmarked configurations from $32$ running workloads of $3$ real-world systems, we arrived at $6$ main findings, which together constitute a holistic picture of the landscape topography, with thorough discussions about their implications on both configuration tuning and performance modeling.
* 23 pages, 8 figures, accepted as a conference paper at ISSTA 2025
FoodSky: A Food-oriented Large Language Model that Passes the Chef and Dietetic Examination
Jun 11, 2024



Food is foundational to human life, serving not only as a source of nourishment but also as a cornerstone of cultural identity and social interaction. As the complexity of global dietary needs and preferences grows, food intelligence is needed to enable food perception and reasoning for various tasks, ranging from recipe generation and dietary recommendation to diet-disease correlation discovery and understanding. Towards this goal, for powerful capabilities across various domains and tasks in Large Language Models (LLMs), we introduce Food-oriented LLM FoodSky to comprehend food data through perception and reasoning. Considering the complexity and typicality of Chinese cuisine, we first construct one comprehensive Chinese food corpus FoodEarth from various authoritative sources, which can be leveraged by FoodSky to achieve deep understanding of food-related data. We then propose Topic-based Selective State Space Model (TS3M) and the Hierarchical Topic Retrieval Augmented Generation (HTRAG) mechanism to enhance FoodSky in capturing fine-grained food semantics and generating context-aware food-relevant text, respectively. Our extensive evaluations demonstrate that FoodSky significantly outperforms general-purpose LLMs in both chef and dietetic examinations, with an accuracy of 67.2% and 66.4% on the Chinese National Chef Exam and the National Dietetic Exam, respectively. FoodSky not only promises to enhance culinary creativity and promote healthier eating patterns, but also sets a new standard for domain-specific LLMs that address complex real-world issues in the food domain. An online demonstration of FoodSky is available at http://222.92.101.211:8200.
Towards the Inferrence of Structural Similarity of Combinatorial Landscapes
Dec 05, 2023One of the most common problem-solving heuristics is by analogy. For a given problem, a solver can be viewed as a strategic walk on its fitness landscape. Thus if a solver works for one problem instance, we expect it will also be effective for other instances whose fitness landscapes essentially share structural similarities with each other. However, due to the black-box nature of combinatorial optimization, it is far from trivial to infer such similarity in real-world scenarios. To bridge this gap, by using local optima network as a proxy of fitness landscapes, this paper proposed to leverage graph data mining techniques to conduct qualitative and quantitative analyses to explore the latent topological structural information embedded in those landscapes. By conducting large-scale empirical experiments on three classic combinatorial optimization problems, we gain concrete evidence to support the existence of structural similarity between landscapes of the same classes within neighboring dimensions. We also interrogated the relationship between landscapes of different problem classes.
On the Hyperparameter Landscapes of Machine Learning Algorithms
Nov 23, 2023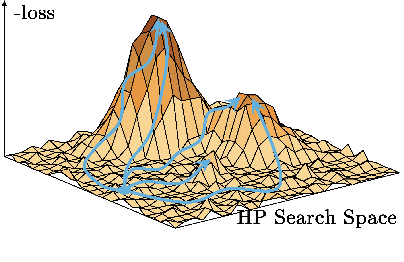
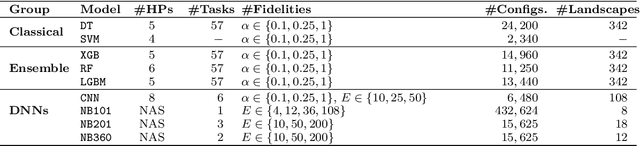
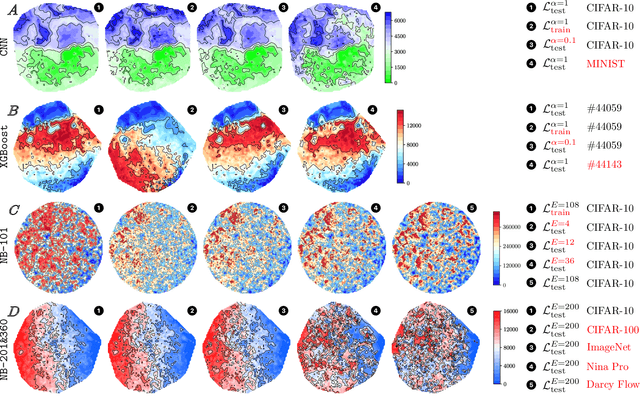
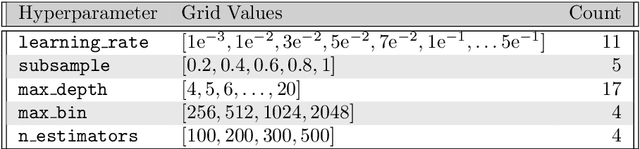
Despite the recent success in a plethora of hyperparameter optimization (HPO) methods for machine learning (ML) models, the intricate interplay between model hyperparameters (HPs) and predictive losses (a.k.a fitness), which is a key prerequisite for understanding HPO, remain notably underexplored in our community. This results in limited explainability in the HPO process, rendering a lack of human trust and difficulties in pinpointing algorithm bottlenecks. In this paper, we aim to shed light on this black box by conducting large-scale fitness landscape analysis (FLA) on 1,500 HP loss landscapes of 6 ML models with more than 11 model configurations, across 67 datasets and different levels of fidelities. We reveal the first unified, comprehensive portrait of their topographies in terms of smoothness, neutrality and modality. We also show that such properties are highly transferable across datasets and fidelities, providing fundamental evidence for the success of multi-fidelity and transfer learning methods. These findings are made possible by developing a dedicated FLA framework that incorporates a combination of visual and quantitative measures. We further demonstrate the potential of this framework by analyzing the NAS-Bench-101 landscape, and we believe it is able to faciliate fundamental understanding of a broader range of AutoML tasks.
Detecting Violations of Differential Privacy for Quantum Algorithms
Sep 09, 2023



Quantum algorithms for solving a wide range of practical problems have been proposed in the last ten years, such as data search and analysis, product recommendation, and credit scoring. The concern about privacy and other ethical issues in quantum computing naturally rises up. In this paper, we define a formal framework for detecting violations of differential privacy for quantum algorithms. A detection algorithm is developed to verify whether a (noisy) quantum algorithm is differentially private and automatically generate bugging information when the violation of differential privacy is reported. The information consists of a pair of quantum states that violate the privacy, to illustrate the cause of the violation. Our algorithm is equipped with Tensor Networks, a highly efficient data structure, and executed both on TensorFlow Quantum and TorchQuantum which are the quantum extensions of famous machine learning platforms -- TensorFlow and PyTorch, respectively. The effectiveness and efficiency of our algorithm are confirmed by the experimental results of almost all types of quantum algorithms already implemented on realistic quantum computers, including quantum supremacy algorithms (beyond the capability of classical algorithms), quantum machine learning models, quantum approximate optimization algorithms, and variational quantum eigensolvers with up to 21 quantum bits.