 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Social Bias in Vision-Language Models with Face-Only Counterfactuals from Real Photos
Jan 11, 2026Vision-Language Models (VLMs) are increasingly deployed in socially consequential settings, raising concerns about social bias driven by demographic cues. A central challenge in measuring such social bias is attribution under visual confounding: real-world images entangle race and gender with correlated factors such as background and clothing, obscuring attribution. We propose a \textbf{face-only counterfactual evaluation paradigm} that isolates demographic effects while preserving real-image realism. Starting from real photographs, we generate counterfactual variants by editing only facial attributes related to race and gender, keeping all other visual factors fixed. Based on this paradigm, we construct \textbf{FOCUS}, a dataset of 480 scene-matched counterfactual images across six occupations and ten demographic groups, and propose \textbf{REFLECT}, a benchmark comprising three decision-oriented tasks: two-alternative forced choice, multiple-choice socioeconomic inference, and numeric salary recommendation. Experiments on five state-of-the-art VLMs reveal that demographic disparities persist under strict visual control and vary substantially across task formulations. These findings underscore the necessity of controlled, counterfactual audits and highlight task design as a critical factor in evaluating social bias in multimodal models.
Underwater Image Enhancement with Cascaded Contrastive Learning
Nov 16, 2024



Underwater image enhancement (UIE) is a highly challenging task due to the complexity of underwater environment and the diversity of underwater image degradation. Due to the application of deep learning, current UIE methods have made significant progress. Most of the existing deep learning-based UIE methods follow a single-stage network which cannot effectively address the diverse degradations simultaneously. In this paper, we propose to address this issue by designing a two-stage deep learning framework and taking advantage of cascaded contrastive learning to guide the network training of each stage. The proposed method is called CCL-Net in short. Specifically, the proposed CCL-Net involves two cascaded stages, i.e., a color correction stage tailored to the color deviation issue and a haze removal stage tailored to improve the visibility and contrast of underwater images. To guarantee the underwater image can be progressively enhanced, we also apply contrastive loss as an additional constraint to guide the training of each stage. In the first stage, the raw underwater images are used as negative samples for building the first contrastive loss, ensuring the enhanced results of the first color correction stage are better than the original inputs. While in the second stage, the enhanced results rather than the raw underwater images of the first color correction stage are used as the negative samples for building the second contrastive loss, thus ensuring the final enhanced results of the second haze removal stage are better than the intermediate color corrected results. Extensive experiments on multiple benchmark datasets demonstrate that our CCL-Net can achieve superior performance compared to many state-of-the-art methods. The source code of CCL-Net will be released at https://github.com/lewis081/CCL-Net.
Vision-Language Consistency Guided Multi-modal Prompt Learning for Blind AI Generated Image Quality Assessment
Jun 24, 2024Recently, textual prompt tuning has shown inspirational performance in adapting Contrastive Language-Image Pre-training (CLIP) models to natural image quality assessment. However, such uni-modal prompt learning method only tunes the language branch of CLIP models. This is not enough for adapting CLIP models to AI generated image quality assessment (AGIQA) since AGIs visually differ from natural images. In addition, the consistency between AGIs and user input text prompts, which correlates with the perceptual quality of AGIs, is not investigated to guide AGIQA. In this letter, we propose vision-language consistency guided multi-modal prompt learning for blind AGIQA, dubbed CLIP-AGIQA. Specifically, we introduce learnable textual and visual prompts in language and vision branches of CLIP models, respectively. Moreover, we design a text-to-image alignment quality prediction task, whose learned vision-language consistency knowledge is used to guide the optimization of the above multi-modal prompts. Experimental results on two public AGIQA datasets demonstrate that the proposed method outperforms state-of-the-art quality assessment models. The source code is available at https://github.com/JunFu1995/CLIP-AGIQA.
Object Segmentation by Mining Cross-Modal Semantics
May 23, 2023



Multi-sensor clues have shown promise for object segmentation, but inherent noise in each sensor, as well as the calibration error in practice, may bias the segmentation accuracy. In this paper, we propose a novel approach by mining the Cross-Modal Semantics to guide the fusion and decoding of multimodal features, with the aim of controlling the modal contribution based on relative entropy. We explore semantics among the multimodal inputs in two aspects: the modality-shared consistency and the modality-specific variation. Specifically, we propose a novel network, termed XMSNet, consisting of (1) all-round attentive fusion (AF), (2) coarse-to-fine decoder (CFD), and (3) cross-layer self-supervision. On the one hand, the AF block explicitly dissociates the shared and specific representation and learns to weight the modal contribution by adjusting the proportion, region, and pattern, depending upon the quality. On the other hand, our CFD initially decodes the shared feature and then refines the output through specificity-aware querying. Further, we enforce semantic consistency across the decoding layers to enable interaction across network hierarchies, improving feature discriminability. Exhaustive comparison on eleven datasets with depth or thermal clues, and on two challenging tasks, namely salient and camouflage object segmentation, validate our effectiveness in terms of both performance and robustness.
A Weakly Supervised Learning Framework for Salient Object Detection via Hybrid Labels
Sep 07, 2022

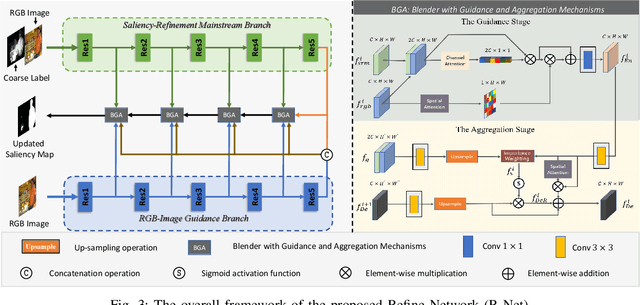

Fully-supervised salient object detection (SOD) methods have made great progress, but such methods often rely on a large number of pixel-level annotations, which are time-consuming and labour-intensive. In this paper, we focus on a new weakly-supervised SOD task under hybrid labels, where the supervision labels include a large number of coarse labels generated by the traditional unsupervised method and a small number of real labels. To address the issues of label noise and quantity imbalance in this task, we design a new pipeline framework with three sophisticated training strategies. In terms of model framework, we decouple the task into label refinement sub-task and salient object detection sub-task, which cooperate with each other and train alternately. Specifically, the R-Net is designed as a two-stream encoder-decoder model equipped with Blender with Guidance and Aggregation Mechanisms (BGA), aiming to rectify the coarse labels for more reliable pseudo-labels, while the S-Net is a replaceable SOD network supervised by the pseudo labels generated by the current R-Net. Note that, we only need to use the trained S-Net for testing. Moreover, in order to guarantee the effectiveness and efficiency of network training, we design three training strategies, including alternate iteration mechanism, group-wise incremental mechanism, and credibility verification mechanism. Experiments on five SOD benchmarks show that our method achieves competitive performance against weakly-supervised/unsupervised methods both qualitatively and quantitatively.
Blind Quality Assessment of 3D Dense Point Clouds with Structure Guided Resampling
Aug 31, 2022

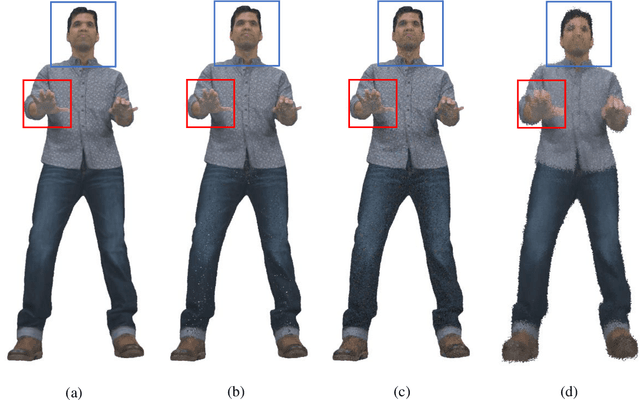

Objective quality assessment of 3D point clouds is essential for the development of immersive multimedia systems in real-world applications. Despite the success of perceptual quality evaluation for 2D images and videos, blind/no-reference metrics are still scarce for 3D point clouds with large-scale irregularly distributed 3D points. Therefore, in this paper, we propose an objective point cloud quality index with Structure Guided Resampling (SGR) to automatically evaluate the perceptually visual quality of 3D dense point clouds. The proposed SGR is a general-purpose blind quality assessment method without the assistance of any reference information. Specifically, considering that the human visual system (HVS) is highly sensitive to structure information, we first exploit the unique normal vectors of point clouds to execute regional pre-processing which consists of keypoint resampling and local region construction. Then, we extract three groups of quality-related features, including: 1) geometry density features; 2) color naturalness features; 3) angular consistency features. Both the cognitive peculiarities of the human brain and naturalness regularity are involved in the designed quality-aware features that can capture the most vital aspects of distorted 3D point clouds. Extensive experiments on several publicly available subjective point cloud quality databases validate that our proposed SGR can compete with state-of-the-art full-reference, reduced-reference, and no-reference quality assessment algorithms.
Quality Evaluation of Arbitrary Style Transfer: Subjective Study and Objective Metric
Aug 01, 2022
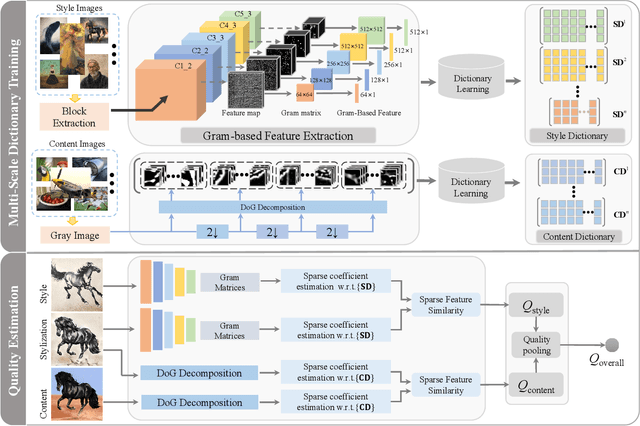

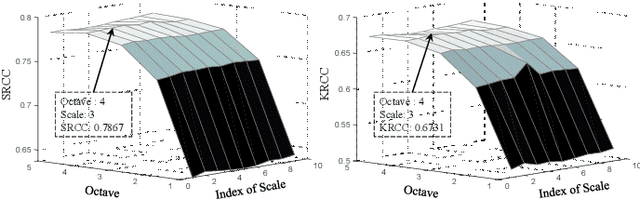
Arbitrary neural style transfer is a vital topic with research value and industrial application prospect, which strives to render the structure of one image using the style of another. Recent researches have devoted great efforts on the task of arbitrary style transfer (AST) for improving the stylization quality. However, there are very few explorations about the quality evaluation of AST images, even it can potentially guide the design of different algorithms. In this paper, we first construct a new AST images quality assessment database (AST-IQAD) that consists 150 content-style image pairs and the corresponding 1200 stylized images produced by eight typical AST algorithms. Then, a subjective study is conducted on our AST-IQAD database, which obtains the subjective rating scores of all stylized images on the three subjective evaluations, i.e., content preservation (CP), style resemblance (SR), and overall visual (OV). To quantitatively measure the quality of AST image, we proposed a new sparse representation-based image quality evaluation metric (SRQE), which computes the quality using the sparse feature similarity. Experimental results on the AST-IQAD have demonstrated the superiority of the proposed method. The dataset and source code will be released at https://github.com/Hangwei-Chen/AST-IQAD-SRQE
BCS-Net: Boundary, Context and Semantic for Automatic COVID-19 Lung Infection Segmentation from CT Images
Jul 17, 2022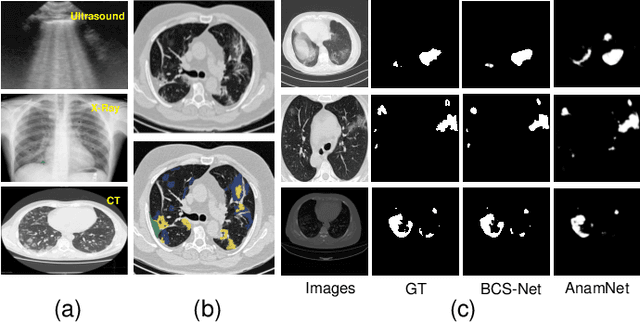
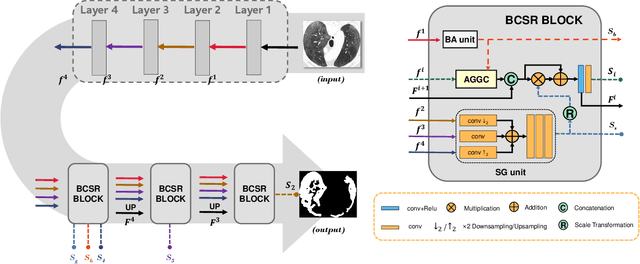
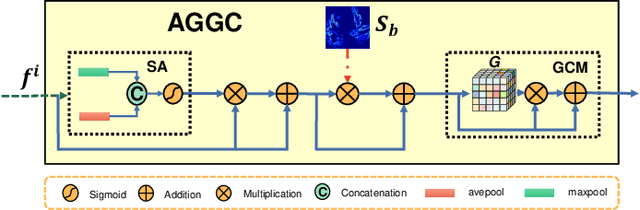
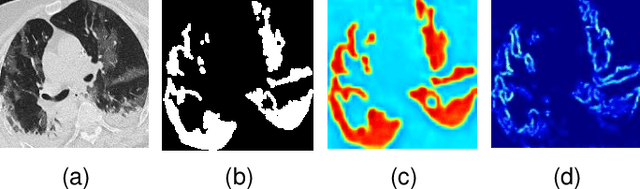
The spread of COVID-19 has brought a huge disaster to the world, and the automatic segmentation of infection regions can help doctors to make diagnosis quickly and reduce workload. However, there are several challenges for the accurate and complete segmentation, such as the scattered infection area distribution, complex background noises, and blurred segmentation boundaries. To this end, in this paper, we propose a novel network for automatic COVID-19 lung infection segmentation from CT images, named BCS-Net, which considers the boundary, context, and semantic attributes. The BCS-Net follows an encoder-decoder architecture, and more designs focus on the decoder stage that includes three progressively Boundary-Context-Semantic Reconstruction (BCSR) blocks. In each BCSR block, the attention-guided global context (AGGC) module is designed to learn the most valuable encoder features for decoder by highlighting the important spatial and boundary locations and modeling the global context dependence. Besides, a semantic guidance (SG) unit generates the semantic guidance map to refine the decoder features by aggregating multi-scale high-level features at the intermediate resolution. Extensive experiments demonstrate that our proposed framework outperforms the existing competitors both qualitatively and quantitatively.
Deep Decomposition and Bilinear Pooling Network for Blind Night-Time Image Quality Evaluation
May 12, 2022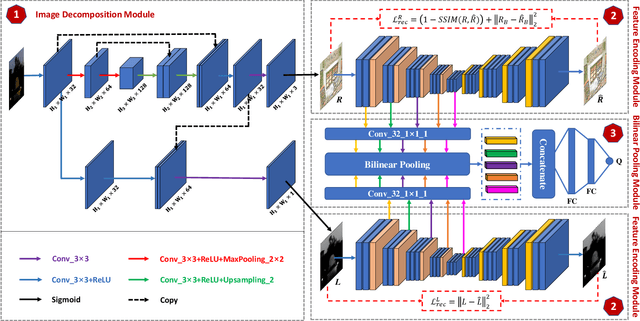
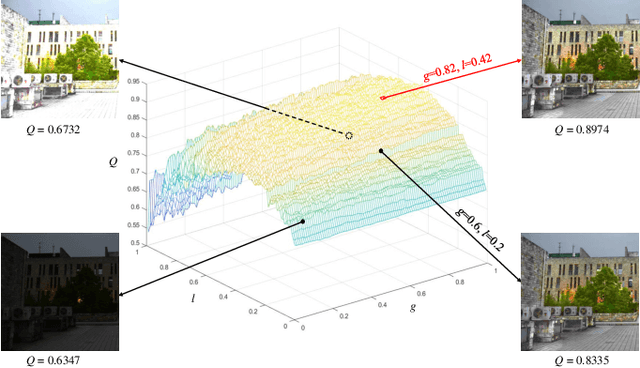
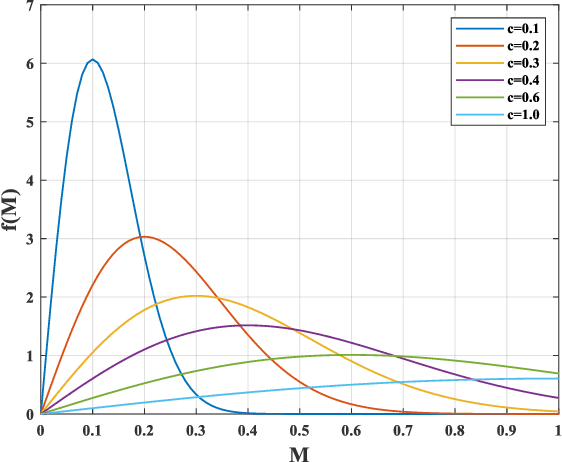
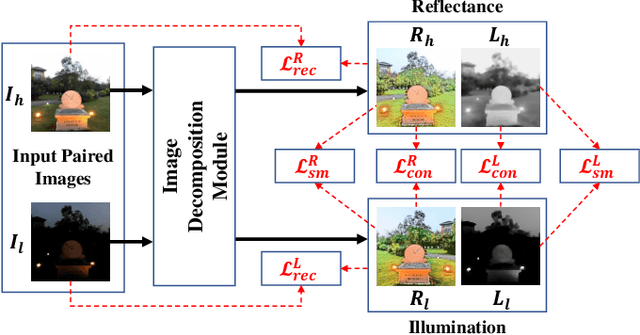
Blind image quality assessment (BIQA), which aims to accurately predict the image quality without any pristine reference information, has been highly concerned in the past decades. Especially, with the help of deep neural networks, great progress has been achieved so far. However, it remains less investigated on BIQA for night-time images (NTIs) which usually suffer from complicated authentic distortions such as reduced visibility, low contrast, additive noises, and color distortions. These diverse authentic degradations particularly challenges the design of effective deep neural network for blind NTI quality evaluation (NTIQE). In this paper, we propose a novel deep decomposition and bilinear pooling network (DDB-Net) to better address this issue. The DDB-Net contains three modules, i.e., an image decomposition module, a feature encoding module, and a bilinear pooling module. The image decomposition module is inspired by the Retinex theory and involves decoupling the input NTI into an illumination layer component responsible for illumination information and a reflectance layer component responsible for content information. Then, the feature encoding module involves learning multi-scale feature representations of degradations that are rooted in the two decoupled components separately. Finally, by modeling illumination-related and content-related degradations as two-factor variations, the two multi-scale feature sets are bilinearly pooled and concatenated together to form a unified representation for quality prediction. The superiority of the proposed DDB-Net is well validated by extensive experiments on two publicly available night-time image databases.
A Brief Survey on Adaptive Video Streaming Quality Assessment
Feb 25, 2022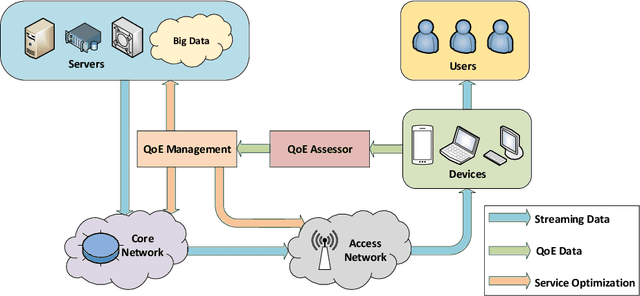
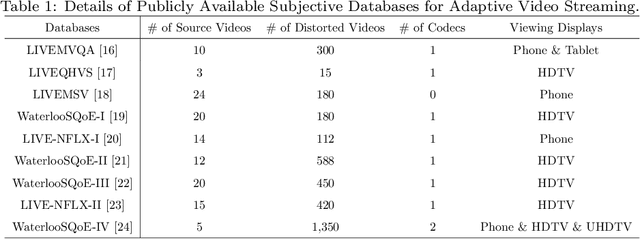
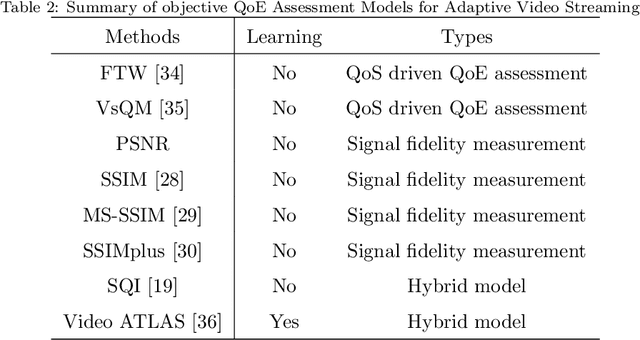

Quality of experience (QoE) assessment for adaptive video streaming plays a significant role in advanced network management systems. It is especially challenging in case of dynamic adaptive streaming schemes over HTTP (DASH) which has increasingly complex characteristics including additional playback issues. In this paper, we provide a brief overview of adaptive video streaming quality assessment. Upon our review of related works, we analyze and compare different variations of objective QoE assessment models with or without using machine learning techniques for adaptive video streaming. Through the performance analysis, we observe that hybrid models perform better than both quality-of-service (QoS) driven QoE approaches and signal fidelity measurement. Moreover, the machine learning-based model slightly outperforms the model without using machine learning for the same setting. In addition, we find that existing video streaming QoE assessment models still have limited performance, which makes it difficult to be applied in practical communication systems. Therefore, based on the success of deep learned feature representations for traditional video quality prediction, we also apply the off-the-shelf deep convolutional neural network (DCNN) to evaluate the perceptual quality of streaming videos, where the spatio-temporal properties of streaming videos are taken into consideration. Experiments demonstrate its superiority, which sheds light on the future development of specifically designed deep learning frameworks for adaptive video streaming quality assessment. We believe this survey can serve as a guideline for QoE assessment of adaptive video streaming.