 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Aided Open-Domain Question Answering
Jun 09, 2020

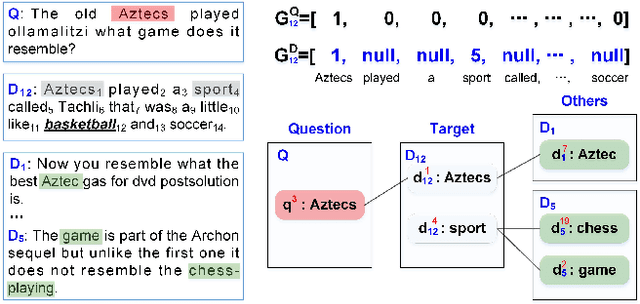
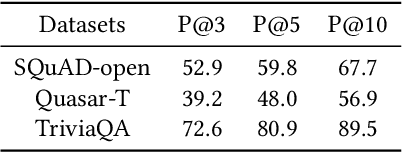
Open-domain question answering (QA) aims to find the answer to a question from a large collection of documents.Though many models for single-document machine comprehension have achieved strong performance, there is still much room for improving open-domain QA systems since document retrieval and answer reranking are still unsatisfactory. Golden documents that contain the correct answers may not be correctly scored by the retrieval component, and the correct answers that have been extracted may be wrongly ranked after other candidate answers by the reranking component. One of the reasons is derived from the independent principle in which each candidate document (or answer) is scored independently without considering its relationship to other documents (or answers). In this work, we propose a knowledge-aided open-domain QA (KAQA) method which targets at improving relevant document retrieval and candidate answer reranking by considering the relationship between a question and the documents (termed as question-document graph), and the relationship between candidate documents (termed as document-document graph). The graphs are built using knowledge triples from external knowledge resources. During document retrieval, a candidate document is scored by considering its relationship to the question and other documents. During answer reranking, a candidate answer is reranked using not only its own context but also the clues from other documents. The experimental results show that our proposed method improves document retrieval and answer reranking, and thereby enhances the overall performance of open-domain question answering.
A Self-Training Method for Machine Reading Comprehension with Soft Evidence Extraction
May 11, 2020
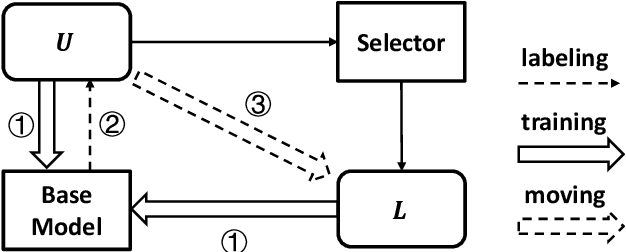
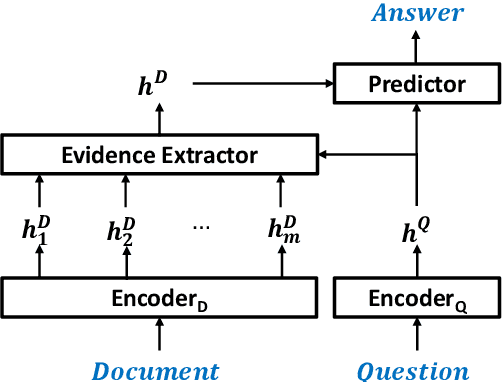
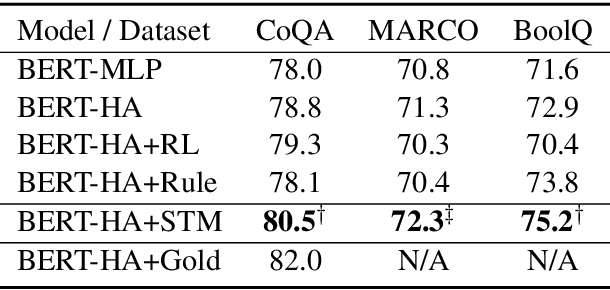
Neural models have achieved great success on machine reading comprehension (MRC), many of which typically consist of two components: an evidence extractor and an answer predictor. The former seeks the most relevant information from a reference text, while the latter is to locate or generate answers from the extracted evidence. Despite the importance of evidence labels for training the evidence extractor, they are not cheaply accessible, particularly in many non-extractive MRC tasks such as YES/NO question answering and multi-choice MRC. To address this problem, we present a Self-Training method (STM), which supervises the evidence extractor with auto-generated evidence labels in an iterative process. At each iteration, a base MRC model is trained with golden answers and noisy evidence labels. The trained model will predict pseudo evidence labels as extra supervision in the next iteration. We evaluate STM on seven datasets over three MRC tasks. Experimental results demonstrate the improvement on existing MRC models, and we also analyze how and why such a self-training method works in MRC.
Robust Reading Comprehension with Linguistic Constraints via Posterior Regularization
Nov 16, 2019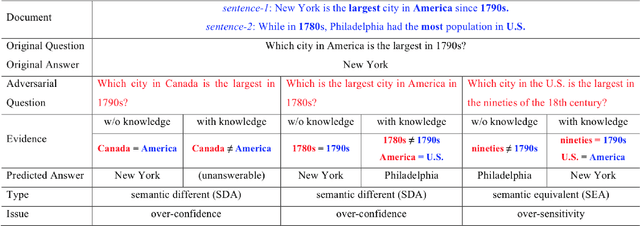
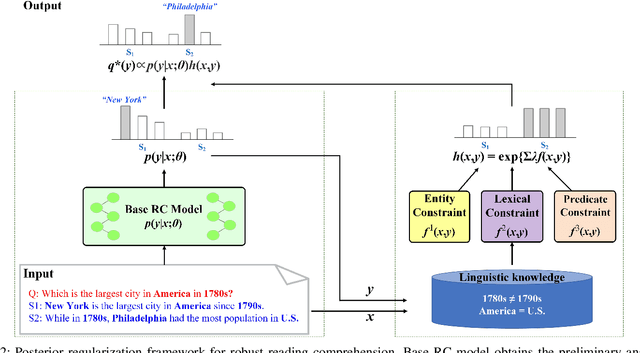
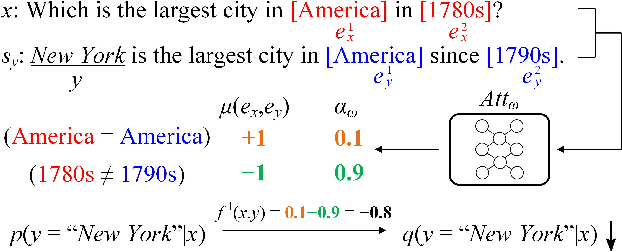

In spite of great advancements of machine reading comprehension (RC), existing RC models are still vulnerable and not robust to different types of adversarial examples. Neural models over-confidently predict wrong answers to semantic different adversarial examples, while over-sensitively predict wrong answers to semantic equivalent adversarial examples. Existing methods which improve the robustness of such neural models merely mitigate one of the two issues but ignore the other. In this paper, we address the over-confidence issue and the over-sensitivity issue existing in current RC models simultaneously with the help of external linguistic knowledge. We first incorporate external knowledge to impose different linguistic constraints (entity constraint, lexical constraint, and predicate constraint), and then regularize RC models through posterior regularization. Linguistic constraints induce more reasonable predictions for both semantic different and semantic equivalent adversarial examples, and posterior regularization provides an effective mechanism to incorporate these constraints. Our method can be applied to any existing neural RC models including state-of-the-art BERT models. Extensive experiments show that our method remarkably improves the robustness of base RC models, and is better to cope with these two issues simultaneously.
An Interpretable Reasoning Network for Multi-Relation Question Answering
Jun 01, 2018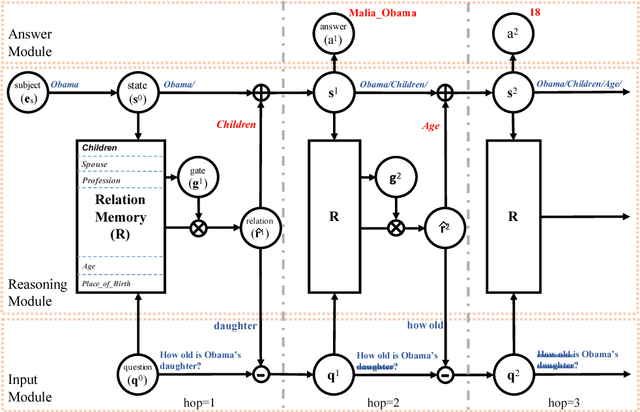

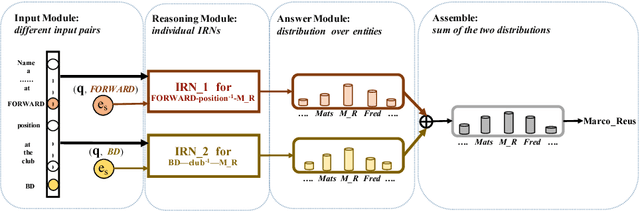
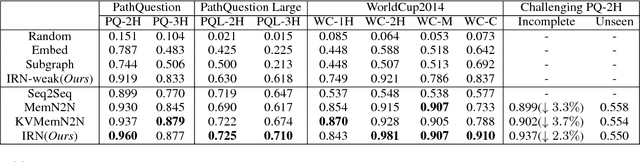
Multi-relation Question Answering is a challenging task, due to the requirement of elaborated analysis on questions and reasoning over multiple fact triples in knowledge base. In this paper, we present a novel model called Interpretable Reasoning Network that employs an interpretable, hop-by-hop reasoning process for question answering. The model dynamically decides which part of an input question should be analyzed at each hop; predicts a relation that corresponds to the current parsed results; utilizes the predicted relation to update the question representation and the state of the reasoning process; and then drives the next-hop reasoning. Experiments show that our model yields state-of-the-art results on two datasets. More interestingly, the model can offer traceable and observable intermediate predictions for reasoning analysis and failure diagnosis, thereby allowing manual manipulation in predicting the final answer.
Knowlege Graph Embedding by Flexible Translation
Sep 10, 2015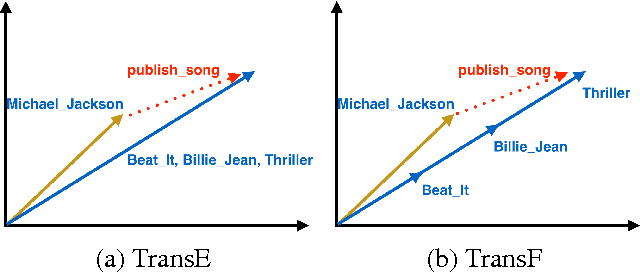
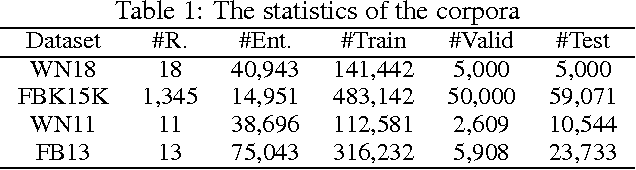
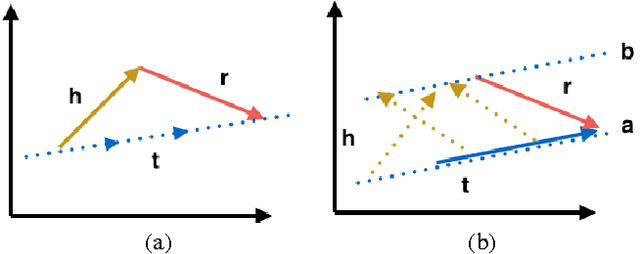
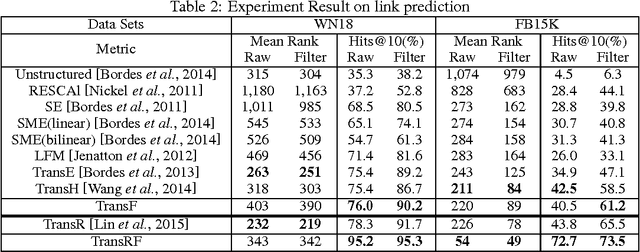
Knowledge graph embedding refers to projecting entities and relations in knowledge graph into continuous vector spaces. State-of-the-art methods, such as TransE, TransH, and TransR build embeddings by treating relation as translation from head entity to tail entity. However, previous models can not deal with reflexive/one-to-many/many-to-one/many-to-many relations properly, or lack of scalability and efficiency. Thus, we propose a novel method, flexible translation, named TransF, to address the above issues. TransF regards relation as translation between head entity vector and tail entity vector with flexible magnitude. To evaluate the proposed model, we conduct link prediction and triple classification on benchmark datasets. Experimental results show that our method remarkably improve the performance compared with several state-of-the-art baselines.