 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Half-listen: Capturing Key-part Information in Continual Instruction Tuning
Mar 15, 2024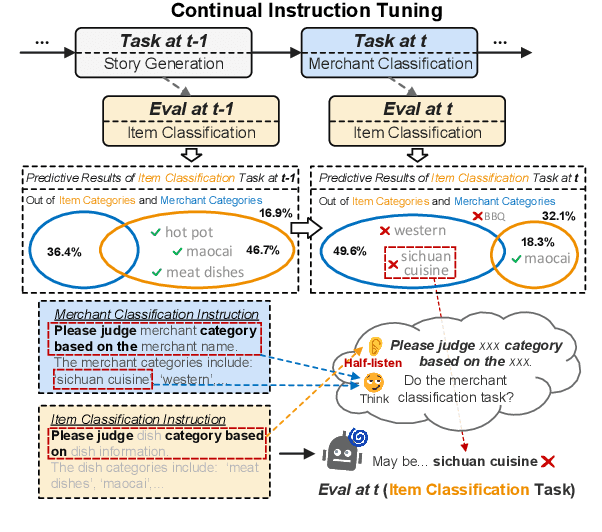



Instruction tuning for large language models (LLMs) can drive them to produce results consistent with human goals in specific downstream tasks. However, the process of continual instruction tuning (CIT) for LLMs may bring about the catastrophic forgetting (CF) problem, where previously learned abilities are degraded. Recent methods try to alleviate the CF problem by modifying models or replaying data, which may only remember the surface-level pattern of instructions and get confused on held-out tasks. In this paper, we propose a novel continual instruction tuning method based on Key-part Information Gain (KPIG). Our method computes the information gain on masked parts to dynamically replay data and refine the training objective, which enables LLMs to capture task-aware information relevant to the correct response and alleviate overfitting to general descriptions in instructions. In addition, we propose two metrics, P-score and V-score, to measure the generalization and instruction-following abilities of LLMs. Experiments demonstrate our method achieves superior performance on both seen and held-out tasks.
M$^2$S-Net: Multi-Modal Similarity Metric Learning based Deep Convolutional Network for Answer Selection
Mar 16, 2018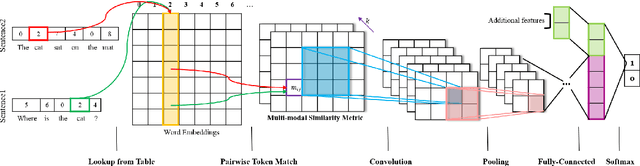
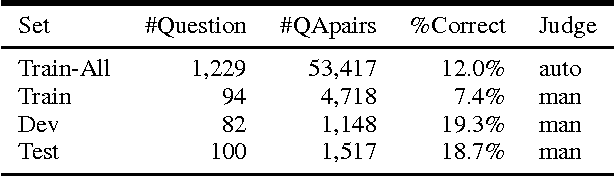
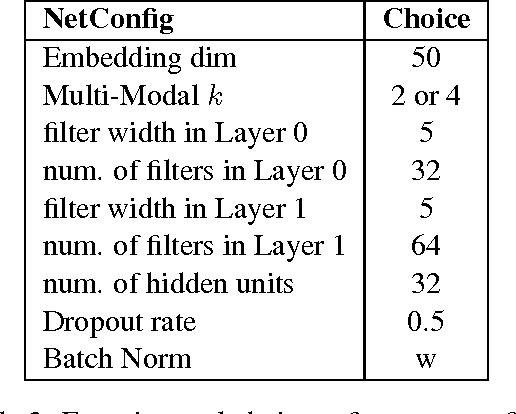

Recent works using artificial neural networks based on distributed word representation greatly boost performance on various natural language processing tasks, especially the answer selection problem. Nevertheless, most of the previous works used deep learning methods (like LSTM-RNN, CNN, etc.) only to capture semantic representation of each sentence separately, without considering the interdependence between each other. In this paper, we propose a novel end-to-end learning framework which constitutes deep convolutional neural network based on multi-modal similarity metric learning (M$^2$S-Net) on pairwise tokens. The proposed model demonstrates its performance by surpassing previous state-of-the-art systems on the answer selection benchmark, i.e., TREC-QA dataset, in both MAP and MRR metrics.
Skipping Word: A Character-Sequential Representation based Framework for Question Answering
Sep 02, 2016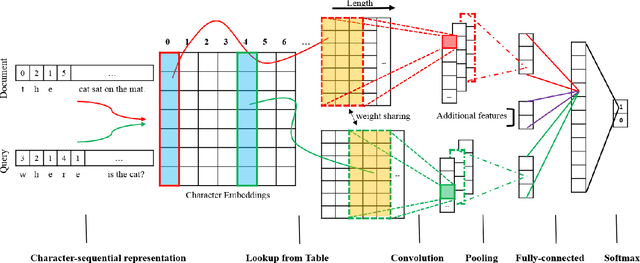
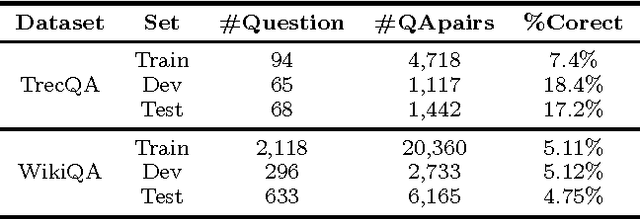

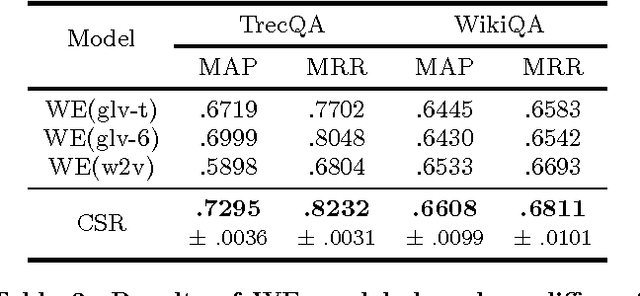
Recent works using artificial neural networks based on word distributed representation greatly boost the performance of various natural language learning tasks, especially question answering. Though, they also carry along with some attendant problems, such as corpus selection for embedding learning, dictionary transformation for different learning tasks, etc. In this paper, we propose to straightforwardly model sentences by means of character sequences, and then utilize convolutional neural networks to integrate character embedding learning together with point-wise answer selection training. Compared with deep models pre-trained on word embedding (WE) strategy, our character-sequential representation (CSR) based method shows a much simpler procedure and more stable performance across different benchmarks. Extensive experiments on two benchmark answer selection datasets exhibit the competitive performance compared with the state-of-the-art methods.