 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Parametric Injection-A Systematic Study of Parametric Retrieval-Augmented Generation
Oct 14, 2025



Retrieval-augmented generation (RAG) enhances large language models (LLMs) by retrieving external documents. As an emerging form of RAG, parametric retrieval-augmented generation (PRAG) encodes documents as model parameters (i.e., LoRA modules) and injects these representations into the model during inference, enabling interaction between the LLM and documents at parametric level. Compared with directly placing documents in the input context, PRAG is more efficient and has the potential to offer deeper model-document interaction. Despite its growing attention, the mechanism underlying parametric injection remains poorly understood. In this work, we present a systematic study of PRAG to clarify the role of parametric injection, showing that parameterized documents capture only partial semantic information of documents, and relying on them alone yields inferior performance compared to interaction at text level. However, these parametric representations encode high-level document information that can enhance the model's understanding of documents within the input context. When combined parameterized documents with textual documents, the model can leverage relevant information more effectively and become more robust to noisy inputs, achieving better performance than either source alone. We recommend jointly using parameterized and textual documents and advocate for increasing the information content of parametric representations to advance PRAG.
REMOTE: A Unified Multimodal Relation Extraction Framework with Multilevel Optimal Transport and Mixture-of-Experts
Sep 05, 2025
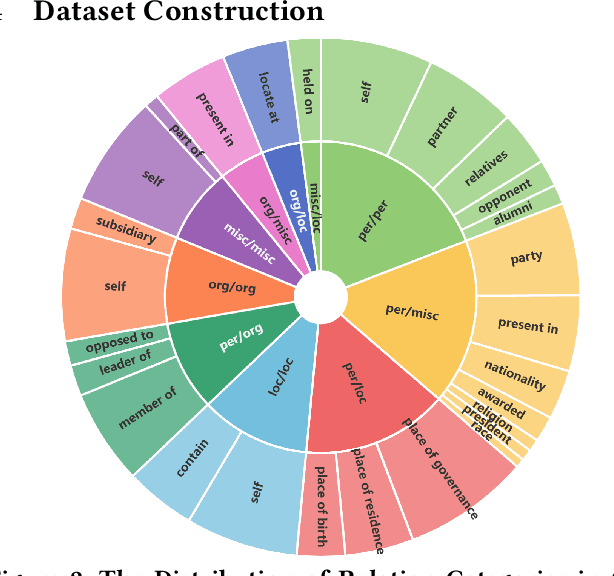
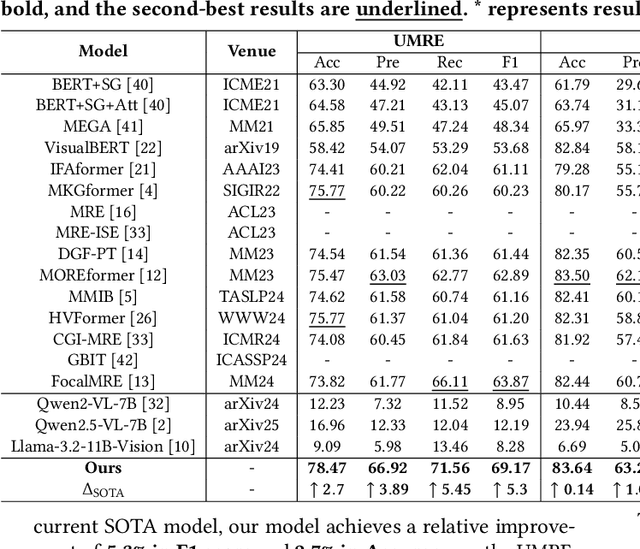
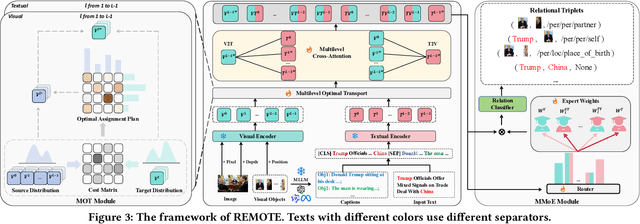
Multimodal relation extraction (MRE) is a crucial task in the fields of Knowledge Graph and Multimedia, playing a pivotal role in multimodal knowledge graph construction. However, existing methods are typically limited to extracting a single type of relational triplet, which restricts their ability to extract triplets beyond the specified types. Directly combining these methods fails to capture dynamic cross-modal interactions and introduces significant computational redundancy. Therefore, we propose a novel \textit{unified multimodal Relation Extraction framework with Multilevel Optimal Transport and mixture-of-Experts}, termed REMOTE, which can simultaneously extract intra-modal and inter-modal relations between textual entities and visual objects. To dynamically select optimal interaction features for different types of relational triplets, we introduce mixture-of-experts mechanism, ensuring the most relevant modality information is utilized. Additionally, considering that the inherent property of multilayer sequential encoding in existing encoders often leads to the loss of low-level information, we adopt a multilevel optimal transport fusion module to preserve low-level features while maintaining multilayer encoding, yielding more expressive representations. Correspondingly, we also create a Unified Multimodal Relation Extraction (UMRE) dataset to evaluate the effectiveness of our framework, encompassing diverse cases where the head and tail entities can originate from either text or image. Extensive experiments show that REMOTE effectively extracts various types of relational triplets and achieves state-of-the-art performanc on almost all metrics across two other public MRE datasets. We release our resources at https://github.com/Nikol-coder/REMOTE.
Leveraging LLMs for Utility-Focused Annotation: Reducing Manual Effort for Retrieval and RAG
Apr 08, 2025Retrieval models typically rely on costly human-labeled query-document relevance annotations for training and evaluation. To reduce this cost and leverage the potential of Large Language Models (LLMs) in relevance judgments, we aim to explore whether LLM-generated annotations can effectively replace human annotations in training retrieval models. Retrieval usually emphasizes relevance, which indicates "topic-relatedness" of a document to a query, while in RAG, the value of a document (or utility) depends on how it contributes to answer generation. Recognizing this mismatch, some researchers use LLM performance on downstream tasks with documents as labels, but this approach requires manual answers for specific tasks, leading to high costs and limited generalization. In another line of work, prompting LLMs to select useful documents as RAG references eliminates the need for human annotation and is not task-specific. If we leverage LLMs' utility judgments to annotate retrieval data, we may retain cross-task generalization without human annotation in large-scale corpora. Therefore, we investigate utility-focused annotation via LLMs for large-scale retriever training data across both in-domain and out-of-domain settings on the retrieval and RAG tasks. To reduce the impact of low-quality positives labeled by LLMs, we design a novel loss function, i.e., Disj-InfoNCE. Our experiments reveal that: (1) Retrievers trained on utility-focused annotations significantly outperform those trained on human annotations in the out-of-domain setting on both tasks, demonstrating superior generalization capabilities. (2) LLM annotation does not replace human annotation in the in-domain setting. However, incorporating just 20% human-annotated data enables retrievers trained with utility-focused annotations to match the performance of models trained entirely with human annotations.
Don't Half-listen: Capturing Key-part Information in Continual Instruction Tuning
Mar 15, 2024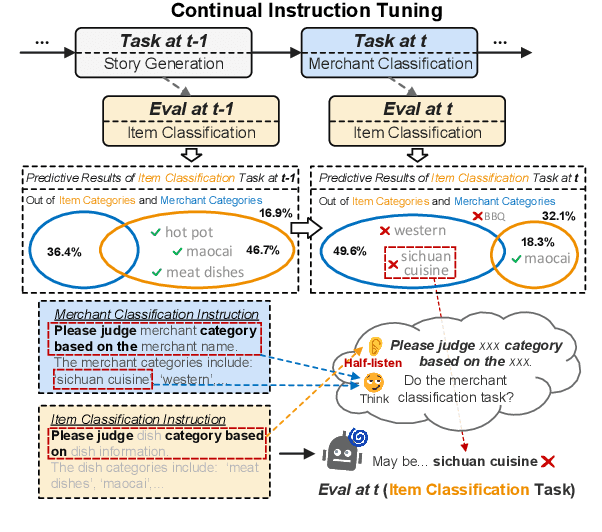



Instruction tuning for large language models (LLMs) can drive them to produce results consistent with human goals in specific downstream tasks. However, the process of continual instruction tuning (CIT) for LLMs may bring about the catastrophic forgetting (CF) problem, where previously learned abilities are degraded. Recent methods try to alleviate the CF problem by modifying models or replaying data, which may only remember the surface-level pattern of instructions and get confused on held-out tasks. In this paper, we propose a novel continual instruction tuning method based on Key-part Information Gain (KPIG). Our method computes the information gain on masked parts to dynamically replay data and refine the training objective, which enables LLMs to capture task-aware information relevant to the correct response and alleviate overfitting to general descriptions in instructions. In addition, we propose two metrics, P-score and V-score, to measure the generalization and instruction-following abilities of LLMs. Experiments demonstrate our method achieves superior performance on both seen and held-out tasks.
A Boundary Offset Prediction Network for Named Entity Recognition
Oct 23, 2023Named entity recognition (NER) is a fundamental task in natural language processing that aims to identify and classify named entities in text. However, span-based methods for NER typically assign entity types to text spans, resulting in an imbalanced sample space and neglecting the connections between non-entity and entity spans. To address these issues, we propose a novel approach for NER, named the Boundary Offset Prediction Network (BOPN), which predicts the boundary offsets between candidate spans and their nearest entity spans. By leveraging the guiding semantics of boundary offsets, BOPN establishes connections between non-entity and entity spans, enabling non-entity spans to function as additional positive samples for entity detection. Furthermore, our method integrates entity type and span representations to generate type-aware boundary offsets instead of using entity types as detection targets. We conduct experiments on eight widely-used NER datasets, and the results demonstrate that our proposed BOPN outperforms previous state-of-the-art methods.
Learning to Correct Noisy Labels for Fine-Grained Entity Typing via Co-Prediction Prompt Tuning
Oct 23, 2023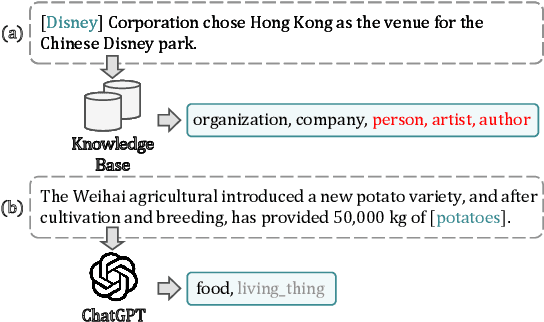
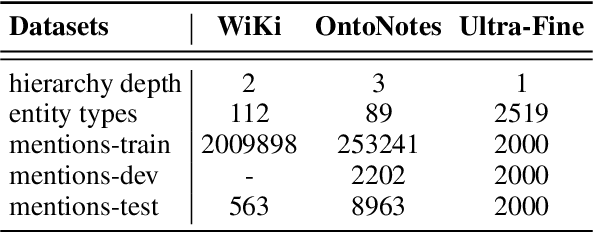
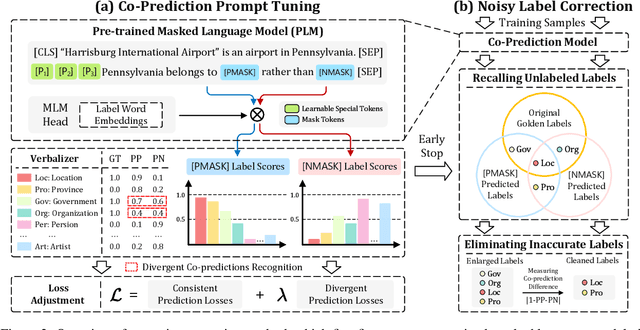
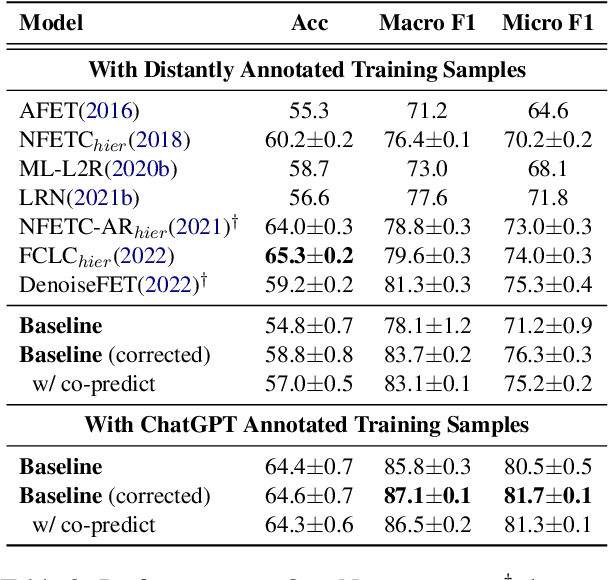
Fine-grained entity typing (FET) is an essential task in natural language processing that aims to assign semantic types to entities in text. However, FET poses a major challenge known as the noise labeling problem, whereby current methods rely on estimating noise distribution to identify noisy labels but are confused by diverse noise distribution deviation. To address this limitation, we introduce Co-Prediction Prompt Tuning for noise correction in FET, which leverages multiple prediction results to identify and correct noisy labels. Specifically, we integrate prediction results to recall labeled labels and utilize a differentiated margin to identify inaccurate labels. Moreover, we design an optimization objective concerning divergent co-predictions during fine-tuning, ensuring that the model captures sufficient information and maintains robustness in noise identification. Experimental results on three widely-used FET datasets demonstrate that our noise correction approach significantly enhances the quality of various types of training samples, including those annotated using distant supervision, ChatGPT, and crowdsourcing.